

Effective Context Length: The Cliff Past 128K Tokens
The effective context length of frontier models is 60-70% of the advertised…
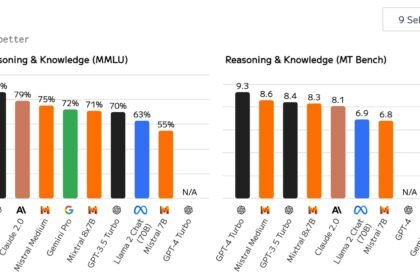
Agentic AI Benchmarks: A Different Model Wins Each
In 2026 the agentic AI benchmarks crown a different winner on every…
LLM Hallucination Rates 2026: Reasoning Flagships Lose
LLM hallucination rates in 2026 hold a surprise: reasoning flagships like Claude…

