

A multi-model scoreboard built from RULER, MRCR v2, NoLiMa and LongBench v2 — and why a 10M-token window can collapse to 26% accuracy at depth.
What is effective context length?
Effective context length is the longest input a model can process while still reliably using the information inside it — typically 60-70% of the advertised window, and often far less for multi-fact reasoning. The advertised number (1M tokens, 10M tokens) describes what the model will accept without erroring. The effective number describes where it still answers correctly. Those are two different quantities, and in 2026 the gap between them is the most important — and least advertised — spec on any model card.
Benchmarks measure this gap with a precise definition. NVIDIA’s RULER fixes an accuracy floor — 85.6%, anchored to Llama-2-7b’s score at 4K tokens — and reports the maximum sequence length at which a model stays above it. Adobe Research’s NoLiMa uses a similar rule: the effective length is the longest context where a model holds at least 85% of its own short-context baseline. Under both definitions, a model advertising 128K can have an effective length of 64K or lower once the task requires anything beyond literal keyword matching.
The reason is mechanical, not cosmetic. Attention has to compete against an ever-larger field of distractor tokens, and the further apart a question and its supporting facts sit, the harder the retrieval. Simple needle-in-a-haystack tests hide this because the needle is a verbatim match. The moment you remove the literal overlap — or ask the model to combine several scattered facts — accuracy falls off a cliff that token counts never reveal.
The four benchmarks on the scoreboard
RULER, MRCR v2, NoLiMa and LongBench v2 each stress a different failure mode, and a model that aces one can fail another — which is exactly why no single score captures effective context length. Reading them together is what turns a marketing window into an engineering budget.
RULER is NVIDIA’s synthetic suite of 13 tasks across four families: retrieval, multi-hop tracing, aggregation, and question answering, run at configurable sequence lengths. It is the benchmark that first proved most models ‘pass’ vanilla needle tests yet degrade sharply on multi-hop work as length grows. MRCR v2 (Multi-Round Co-reference Resolution) plants multiple near-identical ‘needles’ — 4-needle and 8-needle variants — and forces the model to find and disambiguate all of them, which is the closest public proxy for RAG-over-long-documents.
NoLiMa, from Adobe Research and presented at ICML 2025, is the cruelest of the four: it strips literal keyword overlap between the question and the planted fact, so the model must infer a latent association rather than pattern-match. LongBench v2 abandons synthetic needles entirely for 503 realistic multiple-choice tasks over documents up to 2M words, with a human baseline measured under a 15-minute time limit — a sanity check on whether ‘long-context reasoning‘ beats a hurried person.
The accuracy cliff past 128K tokens
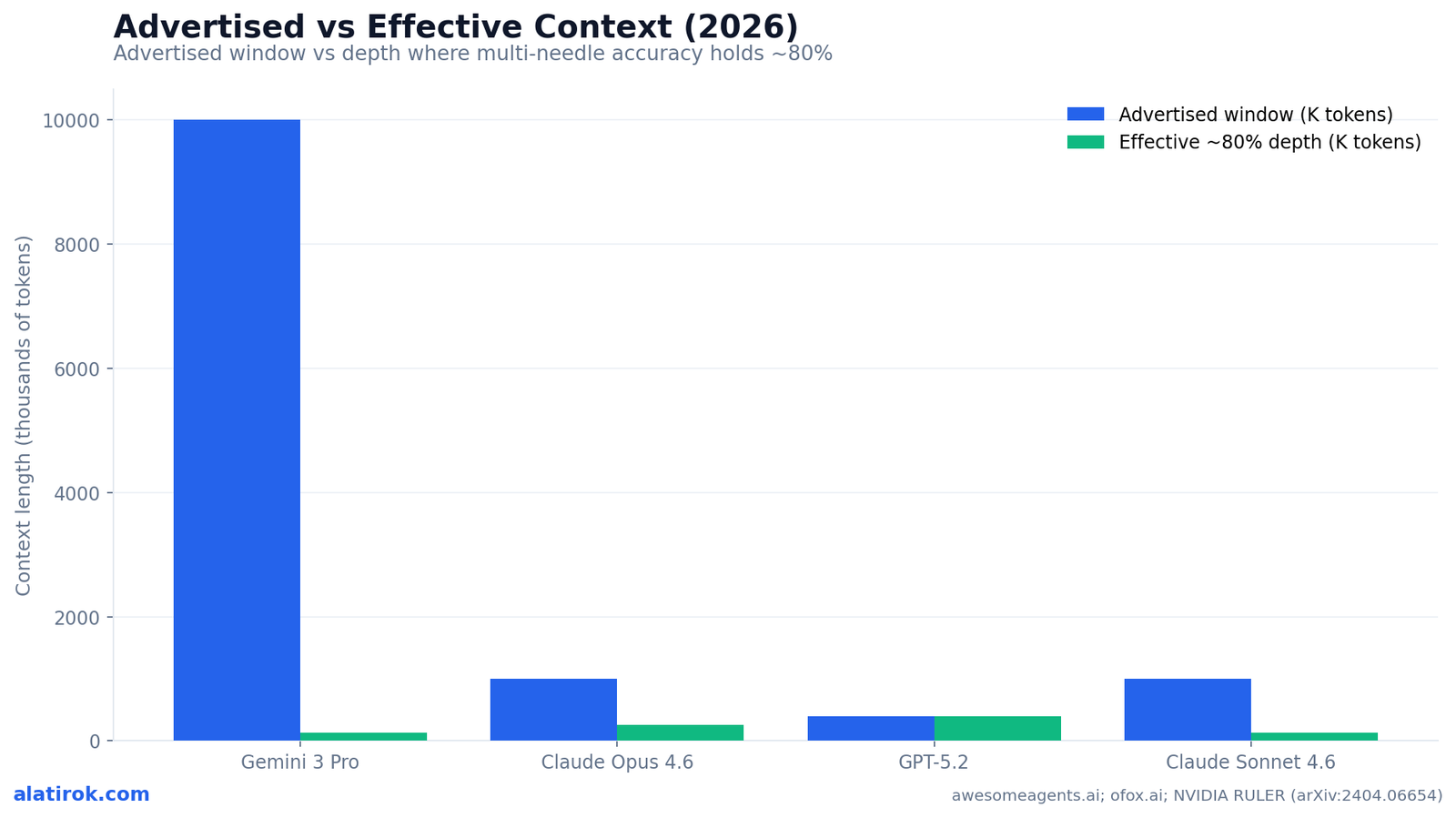
The accuracy cliff past 128K tokens is the single most consequential finding in 2026 long-context evaluation: multi-needle accuracy for several frontier models falls 30 to 60 points between 128K and 1M, even when the window is advertised at 1M or beyond. The cliff is not gradual decay — it is a step function that appears precisely in the depth range most teams assume is ‘free.’
Gemini 3 Pro is the canonical example. At 128K tokens it posts a strong 77% on MRCR v2 8-needle. Push the same task to the actual 1M-token mark and it drops to 26.3% — worse than a coin flip on whether it found all eight needles. Claude Opus 4.6, by contrast, holds 76% at 1M on the same 8-needle task and 93.0% at 128K, a flatter and far more usable curve. The advertised windows are identical in spirit (‘millions of tokens’); the effective windows are not remotely comparable.
NoLiMa shows the cliff arrives even earlier when literal matching is removed. In its evaluation, 11 of the tested models dropped below half of their short-context baseline by 32K tokens, and even a strong performer like GPT-4o fell from a 99.3% baseline to 69.7% at 32K. The lesson is blunt: if your task involves inference rather than lookup, the effective window may be a tenth of what the spec sheet promises.
On MRCR v2 8-needle, Gemini 3 Pro scores 77% at 128K tokens but collapses to 26.3% at 1M — a ~50-point cliff — despite advertising a 10M-token window. The window opens; the comprehension does not follow it in.
Advertised versus effective: the full scoreboard
Across 2026 trackers, every frontier model except the Gemini 3 line shows effective production context in the 200-400K band against advertised windows of 1M or more — a 50-65% utilization rate on RULER’s multi-hop tasks. The chart below pairs each model’s advertised ceiling with the depth at which its measured MRCR/RULER accuracy still clears roughly 80%, the threshold most teams treat as production-grade.
The contrast is stark. Gemini 3 Pro advertises 10M tokens but its reliable 8-needle band ends around 128K, because the 1M score craters to 26.3%. GPT-5.2 advertises a more modest 400K and backs it with a 98% MRCR v2 4-needle score at 256K — a smaller window that is almost entirely usable. Claude Opus 4.6 (1M advertised) sustains ~90% at 256K on the 4-needle task and 76% at 1M on the harder 8-needle, the flattest curve of the group. Claude Sonnet 4.6 (1M advertised) sits a tier lower at ~82% on 4-needle/256K and 84.9% on 8-needle at 128K.
Read the secondary accuracy-versus-depth lines and a pattern emerges that the bar heights alone hide: the rankings reshuffle by depth. A model that leads at 128K can trail at 1M, and a model with a smaller advertised window can be the safer choice for real work because its entire window actually functions.
Reading the depth curves: where rankings flip
26.3%
Gemini 3 Pro, MRCR v2 8-needle at 1M
down from 77% at 128K
60-70%
Typical effective vs advertised context
NVIDIA RULER multi-hop tasks
98%
GPT-5.2, MRCR v2 4-needle at 256K
smaller window, fully usable
53.7%
Human baseline on LongBench v2
under a 15-minute time limit
Single-needle scores are useless for picking a model; multi-needle accuracy at 128K-256K — where roughly 95% of real workloads live — is the only number that predicts production behavior. The distinction is everything, because vendors quote the easy test and ship the hard reality.
At single-needle retrieval over 1M tokens, the field looks healthy: Gemini 3 Deep Think hits 99%, GPT-5.5 96%, Claude Opus 4.7 89%, and DeepSeek V4 Pro 78%. Anyone benchmarking on that task alone would conclude the 1M era has arrived. But switch to RULER’s full multi-hop suite at 256K and the floor drops out: Gemini 3 Deep Think is the only model above 80% (at 84%), GPT-5.5 falls to 72%, and Claude Opus 4.7 to 61%. Same models, same depth, vastly harder task — and a completely different leaderboard.
MRCR v2 8-needle at 128K tells the same story from another angle: Claude Opus 4.6 leads at 93.0%, Claude Sonnet 4.6 and Gemini 3.1 Pro tie at 84.9%, and GPT-5.5’s 8-needle variant sits at 74.0%. The practical takeaway is that ‘best long-context model’ is not a single title — it is a function of depth and needle count. Pick the wrong axis and you optimize for a benchmark your users will never run.
LongBench v2 and the realistic-task reality check
On LongBench v2’s realistic multi-document tasks, Gemini 3 Pro scores 68.2% and GPT-5.2 scores 54.5% — both above the human baseline of 53.7%, but only barely, which reframes what ‘superhuman long context’ actually means. The synthetic benchmarks measure ceilings; LongBench v2 measures whether any of that translates to messy real documents.
The narrow margins matter. A model that beats a time-pressured human by 14 points on a multiple-choice exam over 2M-word documents is genuinely useful, but it is not the oracle the 10M-token marketing implies. And the spread between models on realistic tasks (68.2% vs 54.5%) is wider than their advertised windows would suggest, because the realistic test punishes exactly the multi-hop reasoning that synthetic needle tests under-weight.
This is why a serious evaluation reads all four benchmarks as one instrument. RULER and MRCR v2 expose the cliff, NoLiMa proves it gets worse without literal matches, and LongBench v2 confirms whether the surviving accuracy is good enough to beat a human on a real document. A model can win the first and lose the last.
| Model | Advertised window | MRCR v2 8-needle (128K → 1M) | MRCR v2 4-needle (256K) | RULER multi-hop (256K) | LongBench v2 |
|---|---|---|---|---|---|
| Gemini 3 Pro | 10M | 77% → 26.3% | — | 84% (Deep Think) | 68.2% |
| Claude Opus 4.6 | 1M | 93.0% → 76% | ~90% | 61% (Opus 4.7) | — |
| GPT-5.2 | 400K | 74% (GPT-5.5 var.) | 98% | 72% (GPT-5.5) | 54.5% |
| Claude Sonnet 4.6 | 1M | 84.9% → — | ~82% | — | — |
| DeepSeek V4 Pro | 1M | — | — | 78% single-needle 1M | — |
How to size your context budget in production
Set your usable context budget to the depth where your chosen model’s multi-needle accuracy stays above ~80%, then use retrieval to keep real inputs inside that band — never size to the advertised window. Treating the marketing number as a budget is the most common and most expensive long-context mistake of 2026.
The math is simple once you accept the cliff. If Claude Opus 4.6 holds ~90% at 256K on 4-needle work, 256K is a defensible budget for retrieval-heavy tasks; if Gemini 3 Pro’s 8-needle accuracy is 26.3% at 1M, then 1M is a capacity ceiling, not a working window, and you should chunk-and-rank down into its 128K comfort zone. The benchmark you trust should match your task: 8-needle MRCR for multi-document synthesis, NoLiMa-style reasoning for inference without keyword overlap, single-needle only for pure lookup.
Re-running this scoreboard is not optional, because the numbers move fast. MRCR v2’s current state of the art is GPT-5.4 at 97.3%, with DeepSeek V4 Pro leading open-source at 83.5% against a field median of just 67.2%. A model-routing decision made on last quarter’s leaderboard is a decision made on stale evidence. Version your choices against a dated snapshot so you always know which numbers a pipeline was built on.
Pros
Cons
“A 10M-token window that scores 26% at depth is a capacity ceiling, not a feature. Buy the benchmark, not the number.”
The 2026 effective context length scoreboard
The verdict on effective context length
Treat the advertised window as a ceiling, the benchmark as the budget
The verdict: effective context length, not the advertised window, is the real spec — and in 2026 the two diverge by 30 to 60 points for multi-fact retrieval past 200K tokens. Every model on the scoreboard tells the same story in different proportions: the window you can fill is far larger than the window you can trust.
The practical hierarchy is now clear. For pure lookup, advertised windows roughly hold and almost any frontier model works. For multi-document synthesis — the work agents actually do — size to MRCR v2 and RULER multi-hop scores, keep inputs inside the ~80%-accuracy band, and let retrieval do the rest. And whatever you choose, re-benchmark every quarter, because GPT-5.4’s 97.3% and Gemini 3.1’s reshuffled 128K rankings already make last season’s scoreboard obsolete.
Builder’s take
I run retrieval-heavy agents on Cyntr and Loomfeed, and the single most expensive mistake I see teams make is treating the advertised context number as a usable budget. It isn’t. Here is how I actually reason about it.
- Buy the benchmark, not the number. A 10M-token window that scores 26% on MRCR v2 8-needle at 1M is a marketing number; the 128K band where it scores 77% is the product. I size my pipelines to the depth where accuracy stays above ~80%, then treat everything beyond as a graceful-degradation zone, not a feature.
- Multi-needle is the only test that matters for agents. Single-needle NIAH is solved — Gemini 3 Deep Think hits 99% at 1M. My Cyntr orchestration loops fail on the multi-hop tasks RULER and MRCR v2 measure, so those are the only scores I trust when picking a model for a job.
- Chunk-and-rank still beats brute-force stuffing. When I needed reliable cross-document reasoning on Loomfeed threads, retrieval into a 64-128K window outperformed dumping 500K tokens into a 1M model. The accuracy cliff is real money — wrong answers at depth cost more than the retrieval infra.
- Re-run the scoreboard every quarter. These numbers move fast: GPT-5.4 now leads MRCR v2 at 97.3% and Gemini 3.1 reshuffled the 128K band. I version my model choices against a dated benchmark snapshot so I know exactly which evidence a routing decision was built on.
Frequently asked questions
Effective context length is the longest input a model can process while still reliably using the information inside it. Benchmarks like NVIDIA RULER define it as the maximum sequence length where accuracy stays above a fixed floor (85.6%, anchored to Llama-2-7b at 4K). In 2026 it is typically 60-70% of the advertised window, and far less for multi-fact reasoning.
Gemini 3 Pro advertises a 10M-token window but scores just 26.3% on MRCR v2’s 8-needle task at 1M, down from 77% at 128K. The window describes what the model accepts without erroring, not what it comprehends. Attention struggles to find and combine multiple scattered facts as the field of distractor tokens grows, producing a step-function accuracy cliff rather than gradual decay.
RULER is NVIDIA’s synthetic suite of 13 retrieval, multi-hop, aggregation, and QA tasks. MRCR v2 plants 4 or 8 near-identical needles to test multi-fact disambiguation. NoLiMa (Adobe Research) removes literal keyword overlap so the model must infer associations. LongBench v2 uses 503 realistic multiple-choice tasks over documents up to 2M words, with a human baseline under time pressure.
It depends on depth and task. For multi-needle work at 128K, Claude Opus 4.6 leads at 93.0% on MRCR v2 8-needle. At 256K on 4-needle, GPT-5.2 hits 98% despite a smaller 400K window. Gemini 3 Pro leads realistic LongBench v2 at 68.2% but collapses to 26.3% at 1M on 8-needle. The current MRCR v2 state of the art is GPT-5.4 at 97.3%.
On NVIDIA RULER’s multi-hop tasks, most frontier models reliably use only 50-65% of their advertised context, with effective capacity typically 60-70% of the advertised maximum. Multiple 2026 trackers find advertised and effective context diverge by 30 to 60 points for multi-fact retrieval past 200K tokens, putting real production windows in the 200-400K band for models advertising 1M or more.
Set your usable budget to the depth where your model’s multi-needle accuracy (MRCR v2 or RULER multi-hop) stays above roughly 80%, then use retrieval to keep real inputs inside that band rather than stuffing the full advertised window. Match the benchmark to the task — 8-needle MRCR for synthesis, NoLiMa-style reasoning for inference without keyword overlap — and re-run the scoreboard each quarter as scores shift.
Primary sources
- Long-Context Benchmarks Leaderboard: MRCR, RULER, LongBench v2 — Awesome Agents
- Long-Context LLM Benchmarks 2026: Which Model Holds Accuracy Past 200K? — Ofox AI
- Long-Context Retrieval 2026: Needle-in-Haystack Test — Digital Applied
- RULER: What’s the Real Context Size of Your Long-Context Language Models? — arXiv (NVIDIA)
- NoLiMa: Long-Context Evaluation Beyond Literal Matching — arXiv (Adobe Research)
- NVIDIA/RULER source repository — GitHub
- MRCR v2 Leaderboard — LLM Registry
Last updated: June 1, 2026. Related: Observability.




