A new Stanford/MIT/Microsoft study measured token consumption across 8 frontier models on SWE-bench Verified. The numbers are wilder than any vendor cost guide admits.
How many tokens does a coding agent use per task?
An agentic coding task burns roughly 1 million to 3.5 million tokens on average once you count retries, far more than most teams assume — and the same task can vary by up to 30x in total tokens depending on the run. The tokens per agentic coding task figure that vendors quote is almost always a clean single number; the reality measured on real benchmark trajectories is a wide, skewed distribution.
The definitive data point arrived in April 2026. A team from Stanford, MIT, Microsoft, and the University of Michigan — including Erik Brynjolfsson, Alex Pentland, and Jiaxin Pei — published “How Do AI Agents Spend Your Money?” (arXiv:2604.22750, submitted 24 April 2026). They ran 8 frontier models on SWE-bench Verified, 4 runs per task, and logged every token. It is the first systematic measurement of agentic coding token consumption at this granularity, and it contradicts most of the generic cost guides currently ranking on this topic.
The headline: agentic tasks consume roughly 1000x more tokens than code chat or single-shot code reasoning. When you ask a model a question in a chat box, you spend thousands of tokens. When you hand an autonomous agent a repository, a test suite, and a bug, it spends millions — looping through reads, edits, test runs, and re-reads, each turn re-ingesting the growing context.
Why do AI agents use so many tokens?
AI agents use so many tokens because every turn re-feeds the entire growing context — files, tool outputs, prior reasoning — back into the model as input, so cost compounds with conversation length rather than with the size of the final answer. This is the single most misunderstood fact in agent economics, and it is why agentic coding token consumption dwarfs chat.
The paper is explicit: input tokens, not output tokens, drive the overall cost. A coding agent‘s output per turn is small — a patch, a command, a short rationale. But the input balloons. Turn 20 of a debugging loop sends the original prompt, every file the agent has opened, every test log it has read, and every prior step’s reasoning back through the model. Without caching, you pay full input price for that entire history on every single turn.
The study also found that the most token-hungry models — Kimi-K2, Claude Sonnet 4, Qwen3-Coder-480B — perform more file actions, and roughly 50% of those are repeated actions on the same file. That is the mechanical source of the bloat: exploratory, redundant interaction patterns where the agent re-opens and re-reads files it has already seen, re-injecting them into context each time.
Code chat costs thousands of tokens. An agentic coding task costs millions. The difference is not the answer — it is the context the agent re-reads on every turn. Optimize the input path or nothing else matters.
Tokens per agentic coding task by model: the per-model data
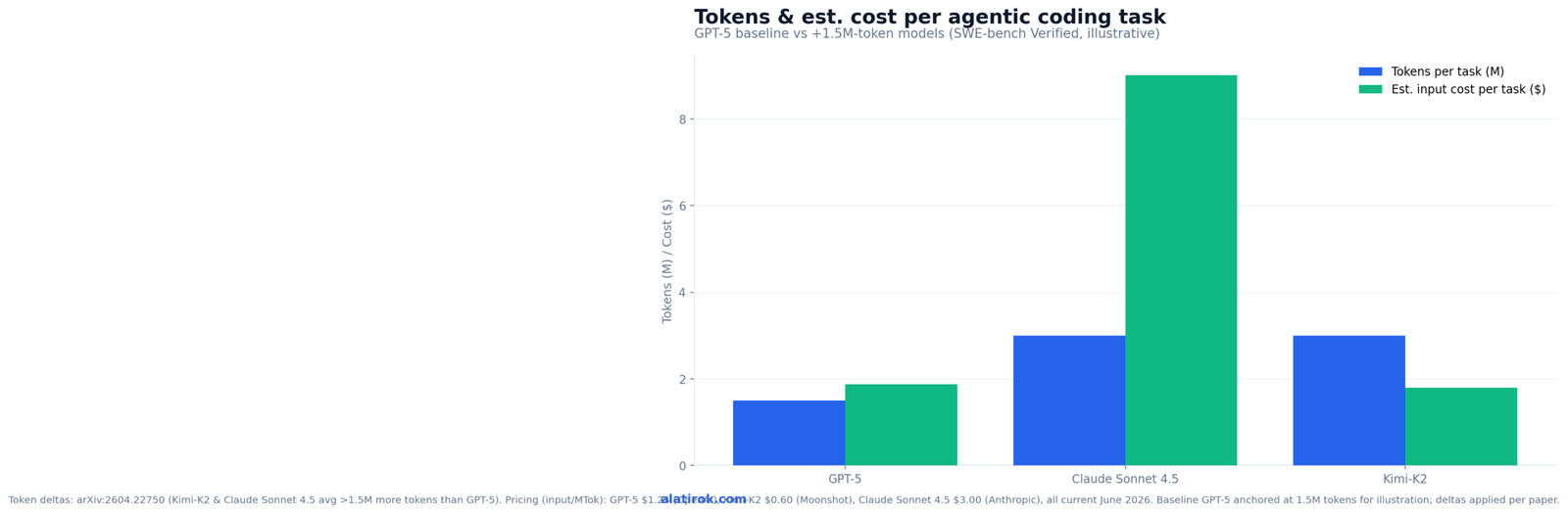
On identical SWE-bench Verified tasks, Kimi-K2 and Claude Sonnet 4.5 each consumed on average over 1.5 million more tokens than GPT-5 — yet GPT-5 achieved strong accuracy at the lowest cost, while Kimi-K2 posted the highest token usage and the lowest accuracy. This is the per-model tokens per agentic coding task picture the paper never published as a clean, priced table, so we built one.
The chart below pairs the paper’s token deltas with current published API input-token pricing to estimate a dollar cost per task. Read the pricing assumptions carefully — they are stated inline, and the absolute token baseline is an illustrative anchor, not a figure lifted verbatim from the paper. What is directly from the paper is the relative gap: roughly 1.5M+ extra tokens for Kimi-K2 and Claude Sonnet 4.5 over GPT-5 on the same work.
Note the counterintuitive cost ordering. Kimi-K2’s per-token price is the lowest of the three ($0.60 per million input tokens), but it burns so many more tokens that its per-task input cost can still undercut Claude Sonnet 4.5 while landing well above GPT-5. Cheap tokens do not guarantee a cheap task. Token efficiency — accuracy per million tokens — is the metric that actually maps to your bill.
Input vs output tokens: where the agent cost actually goes
Input tokens, not output tokens, dominate agentic coding cost — the paper found input is the primary cost driver, which is the opposite of the chat workloads most pricing intuition is built on. Understanding the input vs output token split is the difference between a manageable agent bill and a runaway one.
In a chat app, output is expensive: you pay a high per-token rate for a long generated answer, and input is a short question. Agentic coding inverts this. The generated patch is tiny; the re-ingested context is enormous. Because output rates are typically 4-12x input rates, you might assume output dominates — but at agent scale the sheer volume of repeatedly re-read input flips the math entirely.
This is exactly why prompt caching is the highest-leverage optimization available. Anthropic’s cache reads cost 0.1x the base input price; OpenAI offers cached-input rates well below standard input. If your agent’s stable context — system prompt, repo map, unchanged files — is cached, you stop paying full freight to re-read it every turn. On a 3M-token task that is the difference between a few dollars and a few cents on the dominant cost line.
| Model | Input $/MTok | Output $/MTok | Cached input | Token-efficiency note |
|---|---|---|---|---|
| GPT-5 (Aug 2025) | $1.25 | $10.00 | $0.125 (cached) | Strong accuracy at lowest token cost |
| Claude Sonnet 4.5 | $3.00 | $15.00 | $0.30 (cache read) | 1.5M+ more tokens than GPT-5 on same task |
| Kimi-K2 | $0.60 | $2.50 | ~$0.10-0.16 (cache hit) | Highest token usage, lowest accuracy in study |
Why more tokens does not buy more accuracy
The study found accuracy peaks at intermediate token cost and then saturates — spending more tokens past that point does not improve task success and often signals unproductive thrash. This is the finding that should change how teams configure agents, and it is completely absent from the vendor cost guides currently ranking for this keyword.
The intuition that “letting the model think longer” or “giving it more turns” improves outcomes is wrong beyond a threshold. The accuracy-versus-cost curve rises, peaks at a middle band of token spend, and flattens. Beyond the peak you are buying additional file reads, repeated edits, and longer reasoning chains that do not move the success rate — you are paying for the agent to spin.
There is a second, quieter result that compounds the problem: the models cannot predict their own token usage. When asked to estimate task cost before execution, predictions showed only weak-to-moderate correlation with actual spend (up to 0.39). You cannot ask the agent how much a task will cost and trust the answer — which is precisely why external observability and hard budget caps, not model self-reports, have to govern agent spend.
“More tokens did not translate into higher accuracy. Accuracy peaked at intermediate cost and saturated — past the peak you pay for thrash, not quality.”
arXiv:2604.22750, How Do AI Agents Spend Your Money?
The 30x same-task variance: budgeting for the tail
Runs on the exact same task differed by up to 30x in total tokens, meaning per-task cost is inherently stochastic and any flat per-task estimate based on the average will systematically underbudget the tail. Token cost variance on the same task is the operational risk almost no cost guide quantifies.
This stochasticity comes from the agent’s nondeterministic path. One run finds the bug in three file reads and two edits; another wanders, re-reads the same module five times, runs the test suite repeatedly, and burns 30x the tokens reaching the same — or a worse — outcome. Same task, same model, wildly different bills.
The practical consequence: model your agent’s per-task cost as a distribution and budget against a high percentile, not the mean. If you sell agentic features at a fixed price per task, the long tail is your margin risk. The defenses are structural — hard turn limits, context-window caps, early-exit heuristics when the agent loops — because you cannot rely on the model to self-regulate the spend it cannot even predict.
Pros
Cons
What this means for AI inference economics in 2026
The tokens per agentic coding task data reframes inference economics around efficiency and observability rather than headline per-token price — the winning stack is the one that does the task in the fewest re-read tokens, not the one with the lowest sticker rate. That is the durable lesson from arXiv:2604.22750 for anyone building or buying agents in 2026.
The market has spent two years competing on per-token price. This study shows that axis is nearly irrelevant for agentic workloads, because a cheap model that re-reads files and loops can cost more per finished task than a pricier, disciplined one. The real competitive surface is token efficiency: accuracy per million tokens, and how aggressively the harness caches, compacts, and caps context.
For builders, the to-do list is concrete: instrument tokens per task as a first-class metric, alert on the tail not the mean, cache the stable context, cap the loop, and benchmark candidate models on accuracy-per-dollar against your own tasks rather than on a leaderboard. The agents that win on cost in 2026 will be the ones that learned to stop re-reading the same file.
Stop optimizing for per-token price. The cheapest tokens per agentic coding task come from re-reading the least context — cache aggressively, cap the loop, and measure accuracy per dollar, not tokensBuilder’s take
I run the billing for an AI orchestration engine and a discussion platform, so I read this paper the way a restaurant owner reads a wholesale invoice. Three things changed how I budget agents:
- The cost driver is input tokens, not output. Every redundant file re-read, every bloated system prompt, every uncompacted trajectory re-enters the context window on the next turn and gets billed again. Prompt caching is not a nice-to-have here; it is the single biggest lever on your agent bill.
- The 30x same-task variance means your per-task cost is a distribution, not a number. If you quote a customer a flat rate per task, you are underwriting the tail. Budget against P95, not the mean.
- More tokens did not buy more accuracy. The accuracy curve peaks at intermediate cost and flattens. That kills the reflex to ‘just let it think longer’ — past a point you are paying for thrash, not quality. Cap turns, cap context, and measure.
Frequently asked questions
Roughly 1 million to 3.5 million tokens on average once retries are included, and the same task can vary up to 30x between runs. That is about 1000x more than a single code-chat exchange, because the agent re-ingests its growing context on every turn rather than producing one short answer.
Because input tokens, not output, dominate. Each turn re-feeds the entire conversation — opened files, tool outputs, prior reasoning — back into the model. Token-heavy models also repeat file actions (about 50% are repeats on the same file), re-reading content they have already seen and re-billing it every turn.
Yes. In arXiv:2604.22750, Kimi-K2 and Claude Sonnet 4.5 each consumed on average over 1.5 million more tokens than GPT-5 on identical SWE-bench Verified tasks. GPT-5 achieved strong accuracy at the lowest token cost; Kimi-K2 had the highest usage and the lowest accuracy.
No. The study found accuracy peaks at intermediate token cost and then saturates. Spending more tokens past that peak does not raise the success rate and usually reflects unproductive looping, so ‘let it think longer’ is a poor default beyond a threshold.
Input tokens. The paper identifies input as the primary cost driver because the re-read context grows every turn while the generated patch stays small. This is why prompt caching — cache reads cost about 0.1x base input price on Claude — is the highest-leverage cost optimization for agents.
It depends heavily on the model and caching. As a rough input-only estimate at June 2026 pricing, a 3M-token task is about $1.80 on Kimi-K2 ($0.60/MTok), under $4 on GPT-5 ($1.25/MTok), and up to ~$9 on Claude Sonnet 4.5 ($3/MTok). Aggressive caching can cut the dominant input line by an order of magnitude.
Primary sources
- How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks (arXiv:2604.22750) — arXiv
- Project page: Token Consumption in Agentic Coding — Longju Bai et al.
- Anthropic Claude API pricing — Anthropic
- OpenAI API pricing — OpenAI
- Kimi K2 API pricing — PricePerToken
- The Coding Assistant Breakdown: More Tokens Please — SemiAnalysis
Last updated: June 6, 2026. Related: Observability.