


A sourced tokens-and-dollars-per-task reference by agent type, the context-snowball mechanic that drives input cost, and the 30x variance that makes outcome pricing impossible.
What is the AI agent token cost per task in 2026?
~1000x
More tokens than code chat
Stanford Digital Economy Lab, arXiv 2604.22750
Up to 30x
Same-task run-to-run variance
Same agent, same task, different trajectory
~25:1
Input-to-output token ratio
Agentic coding, Vantage 2026
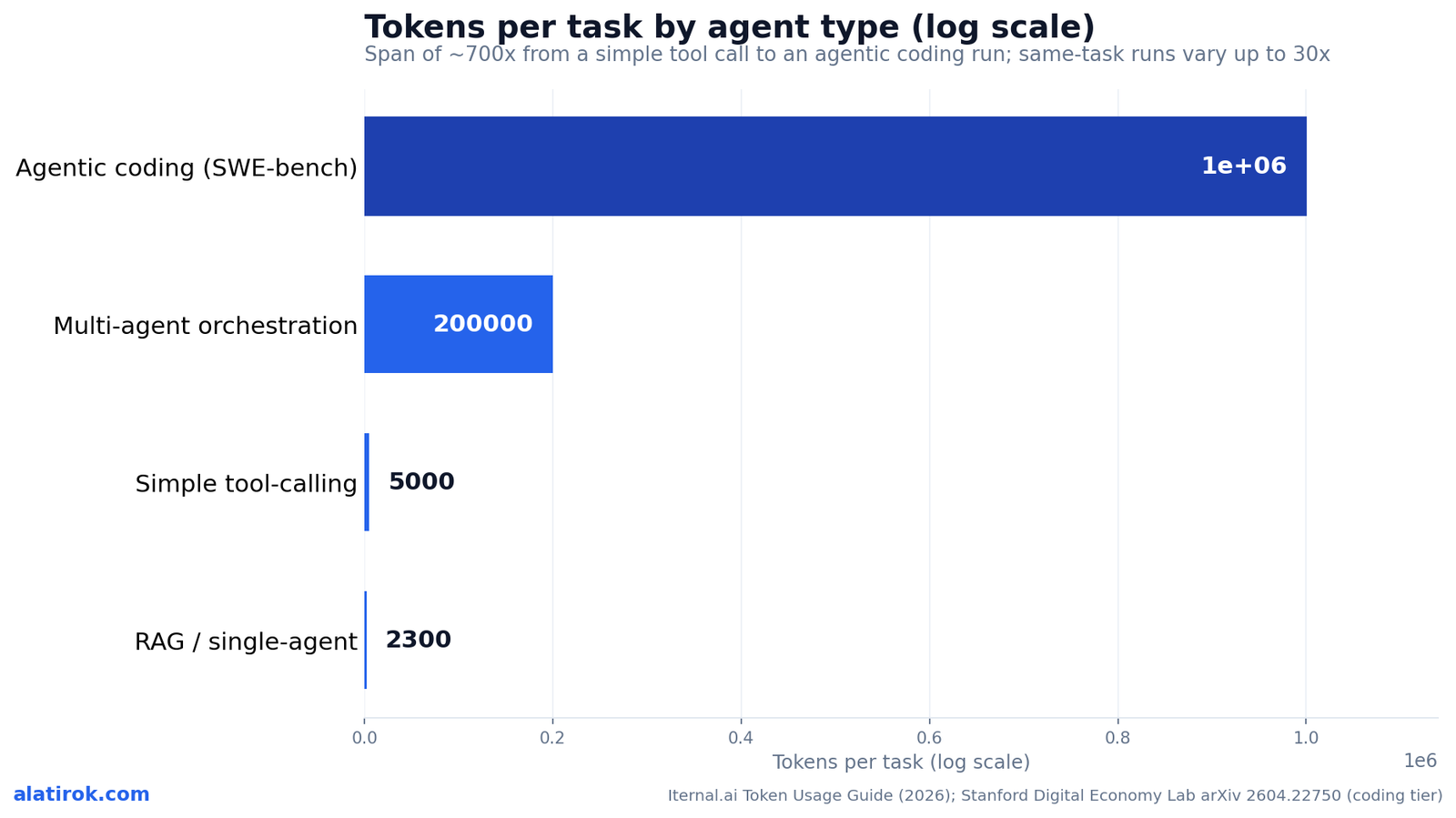
5K → 3.5M
Tokens/task across agent types
Iternal.ai 2026 + Stanford
The AI agent token cost per task in 2026 ranges from about 5,000 tokens for a simple tool-calling agent to 1-3.5 million tokens for an agentic coding run — a span of roughly 700x — and the same task can vary up to 30x run to run, so a single “cost per task” number is misleading without a range. The figure depends almost entirely on agent architecture, not on the model you pick.
The reason this question is so hard to answer cleanly is that the most authoritative data lives in an academic paper — the Stanford Digital Economy Lab’s How Do AI Agents Spend Your Money? (arXiv 2604.22750, published May 5, 2026) — which quantifies the consumption but never publishes a buyer-facing dollar table. Meanwhile the practitioner write-ups give scattered token ranges. This page fuses both into one reference, then explains the mechanism that makes the AI agent token cost per task behave so badly.
The headline from Stanford: agentic tasks consume roughly 1000x more tokens than code reasoning or code chat. That single multiplier is why your chat-era cost intuition is wrong for agents. A developer asking a model a question spends thousands of tokens; the same developer pointing an agent at the same repository spends millions, because the agent does not ask once — it reads, acts, re-reads, and iterates until it converges or gives up.

Tokens per task by agent type: the sourced table
Token consumption rises by orders of magnitude as you move from a single tool call to a multi-agent system to a full agentic coding run — roughly 5K → 50K → 1M → 3.5M tokens per task. The table below fuses the Iternal.ai 2026 Token Usage Guide ranges with the Stanford per-task data so you can size a workload before you build it.
Two columns matter most for FinOps. The first is the token range, which sets the floor and ceiling of your bill. The second is the dollar estimate, which we derive at illustrative frontier-model input pricing (roughly $3-$15 per million input tokens depending on tier) — because input tokens, not output, dominate the AI agent token cost per task. Treat the dollar column as an order-of-magnitude guide, not a quote: the 30x variance discussed below applies on top.
Notice that RAG and single-agent retrieval systems are cheap — comparable to a rich chat turn — while the jump to multi-agent orchestration is where budgets break. Iternal pegs the multi-agent penalty at roughly 7x per additional agent in hierarchical setups, which is how a three-agent system lands in the hundreds of thousands of tokens per task.
Costs assume input tokens at roughly $3-$15 per million (current frontier tiers) and that ~85% of spend is input, per Vantage. Output is a rounding error here. Your actual bill swings with model choice and the run-to-run variance below — size the range, not the point estimate.
| Agent type | Tokens per task | Cost driver | Illustrative cost per task |
|---|---|---|---|
| Simple tool-calling (1-2 calls) | 5,000 – 15,000 | Small fixed context | < $0.05 |
| RAG / single-agent retrieval | ~2,300 – 4,800 | Retrieved chunks + answer | < $0.05 |
| Multi-agent orchestration | 200,000 – 1,000,000+ | ~7x per added agent; shared context | $0.60 – $15+ |
| Agentic coding (SWE-bench class) | 1,000,000 – 3,500,000 | Context snowball + retries | $3 – $50+ |
How many tokens does an AI agent use — and why is it mostly input?
An AI agent uses far more input tokens than output tokens — about 25 input tokens for every 1 output token in agentic coding, with input accounting for roughly 85% of the total cost — because the agent re-reads its entire growing context before every single action. This is the single most counterintuitive fact about the AI agent token cost per task, and it explains why agents are so expensive relative to chat.
The mechanism is what Stanford and practitioners alike call the context snowball. An agent reads the task, gets a response, then has to re-read everything — the original prompt, the system instructions, every file it has opened, every tool result, every error message, and the full transcript of prior turns — before it can decide its next action. Each turn the snowball gets bigger, and the model pays for the whole thing again on every request.
Vantage’s 2026 teardown of agentic coding sessions makes the curve concrete: turn 1 might send 5,000 input tokens, but by turn 30 the model is carrying 25,000-35,000 input tokens of accumulated context on every single request, and by turn 50 it is hitting the context-window limit and compacting. The output — the actual code edit — stays small. You are not paying for what the agent writes; you are paying, over and over, for what it has to re-read.
“You are not paying for what the agent writes. You are paying, over and over, for what it has to re-read.”
The context-snowball mechanic behind agent bills
Why are AI agents so expensive? The 30x same-task variance
AI agents are expensive — and unpredictable — because the same agent running the same task can consume up to 30x more tokens on one run than another, and the agents themselves cannot predict their own spend. Stanford found that token usage is “highly variable and inherently stochastic,” which is the finding most likely to wreck a naive per-task budget.
This is the data point that the buyer-intent SEO results miss entirely. It is not just that agentic coding costs 1-3.5M tokens; it is that the SAME ticket might cost you 100,000 tokens on a lucky trajectory and 3 million on an unlucky one. The agent might find the bug on the first read, or it might thrash through a dozen wrong files, re-run a failing test suite five times, and balloon its own context. You cannot tell in advance which run you’ll get.
Worse for anyone hoping to quote a fixed price: Stanford reports that frontier models fail to predict their own token usage, with weak-to-moderate correlations (up to 0.39) between predicted and actual spend, and they systematically underestimate real cost. The lab also found that higher token usage does not buy higher accuracy — accuracy often peaks at intermediate cost and saturates after that. So the expensive runs are frequently the failing runs, not the thorough ones.
There is a model-choice dimension too. On the same task set, Stanford measured that Kimi-K2 and Claude Sonnet-4.5 consumed, on average, over 1.5 million more tokens than GPT-5. Token efficiency is now a model property worth benchmarking, not an afterthought — two models that score similarly on capability can differ by millions of tokens, and therefore dollars, on identical work.
Pros
Cons
Claude Code cost per day: what real agentic usage looks like
The average Claude Code cost is about $6 per developer per day, with 90% of developers staying under $12 per day — but the spread is roughly 100x between the lightest and heaviest users, and an all-frontier-model session can cost 10x a mixed-model one for the same work. Those Anthropic-published averages are the most-cited real-world anchor for the AI agent token cost per task in coding.
Vantage’s session-level analysis sharpens the picture. A single 50-turn agentic coding session on a top-tier model (Claude Opus class) runs about $6 in their model, versus roughly $0.60 on a cheaper coding model like Composer 2 Standard — a 10x gap driven almost entirely by input-token pricing on that re-read context. Scaled to a 25-developer team running ~1,000 sessions a month, that is the difference between roughly $6,000/month (~$72,000/year) on all-frontier and ~$600/month (~$7,200/year) on the cheaper tier.
The practical takeaway for Claude Code cost per day is that the model mix, not the task, sets your bill. An all-Opus pipeline that uses the most expensive model for trivial sub-steps will land at the top of the range; a pipeline that routes a Haiku/Sonnet/Opus mix — cheap models for reads and routing, the expensive model only for the hard reasoning step — lands at the bottom. Same outcomes, a fraction of the AI agent token cost per task.
| Metric | Value | Source |
|---|---|---|
| Average Claude Code cost / dev / day | ~$6 | Anthropic averages (via Vantage) |
| Developers under $12 / day | 90% | Anthropic averages (via Vantage) |
| 50-turn session, frontier model | ~$6 | Vantage model |
| 50-turn session, cheaper coding model | ~$0.60 | Vantage model |
| 25-dev team, all-frontier / year | ~$72,000 | Vantage model |
| 25-dev team, cheaper tier / year | ~$7,200 | Vantage model |
How to estimate AI agent token cost per task before you build
To estimate the AI agent token cost per task before building, pick your architecture row from the table above for the median, then multiply the high end by ~3x to budget for variance, and assume ~85% of cost is input tokens. Because agents cannot predict their own spend, your estimate must come from architecture and measured trajectories, not from asking the model.
A workable estimation flow: (1) Classify the task — tool call, retrieval, multi-agent, or coding — and read the median tokens from the table. (2) Multiply by your model’s input price per million tokens, since input dominates. (3) Add a variance buffer; for coding tasks the safe planning assumption is the high end of the range, because the 30x tail is real and the failing runs are often the expensive ones. (4) Subtract savings from prompt caching, which can recover a large share of that re-read input context if your framework supports it.
Then instrument and verify. The Stanford result that matters operationally is that the only reliable per-task number is a measured one. Wire per-task token accounting into your agent loop, log tokens-in and tokens-out per trajectory, and build your real cost-per-task distribution from your own traffic. That measured distribution — median plus the fat tail — is what you hand finance, and it’s the input layer that makes spend tracking and capping (the FinOps job) and model selection (the inference-economics job) actually work.
Median = architecture row from the table. Budget = high end of that row × your input price per million tokens × ~1.15 to cover the small output share. Then cap turns/context to bound the 30x tail, and turn on prompt caching to claw back re-read input.
Where this is heading: 24x more tokens by 2030
The bottom line on AI agent token cost per task
Goldman Sachs projects AI-agent token consumption will multiply roughly 24x to about 120 quadrillion tokens per month by 2030, driven by the rise of agentic AI — so the per-task economics in this article are about to be multiplied across an enormous and growing base. The macro trend amplifies every inefficiency in the AI agent token cost per task.
Goldman’s breakdown attributes a ~12x lift to consumer agents by 2030 and an even larger enterprise effect over the longer horizon (a ~55x enterprise lift by 2040 in their longer-dated scenario). The offsetting force is falling unit cost: the bank notes semiconductor and inference providers cutting cost per token by roughly 60-70% per year. But unit-cost deflation does not save you if your agents are stochastically burning 30x on bad runs — efficiency at the trajectory level is what compounds.
That is precisely why the per-task consumption layer deserves its own discipline. As token volume 24x’s, the teams that win on AI agent unit economics will be the ones who measured tokens per task early, shrank the context snowball, routed model mixes intelligently, and capped the variance tail — rather than discovering their bill after the agentic-economy wave has already multiplied it.
Builder’s take
I run the token meter on Cyntr and Loomfeed every day, so the Stanford finding that agents can’t predict their own spend isn’t an abstraction to me — it’s a line item. Here is what the per-task numbers actually changed about how I build:
- Budget by trajectory, not by task. The same ticket can cost 30x more on a bad run, so any per-task estimate you hand finance is a median with a fat tail — caps belong on the trajectory (max turns, max context), not on a per-task dollar guess.
- Input tokens are the bill. With a ~25:1 input-to-output ratio and input at ~85% of cost, every optimization that doesn’t shrink the re-read context (pruning history, scoping retrieval, prompt caching) is rounding error.
- Model mix beats model loyalty. An all-frontier-model session can run 10x a mixed Haiku/Sonnet/Opus pipeline for the same work; routing cheap models to cheap steps is the single biggest lever most teams haven’t pulled.
- Measure first, cap second. You can’t FinOps what you don’t meter — wire per-task token accounting before you argue about which model to standardize on.
Frequently asked questions
It depends entirely on architecture. A simple tool-calling agent uses 5,000-15,000 tokens (under $0.05). A RAG or single-agent retrieval task uses ~2,300-4,800 tokens. A multi-agent system uses 200,000-1,000,000+ tokens ($0.60-$15+). An agentic coding task uses 1,000,000-3,500,000 tokens including retries ($3-$50+), per the Iternal.ai 2026 guide and the Stanford Digital Economy Lab. On top of that, the same task can vary up to 30x between runs.
From about 5,000 tokens for a simple tool call to 1-3.5 million for an agentic coding run — a roughly 700x range driven by how much context the agent accumulates and re-reads. Stanford found agentic tasks consume about 1000x more tokens than code chat, with input tokens (the re-read context) rather than output tokens driving the cost.
Because of the context snowball: an agent re-reads its entire growing context — system prompt, every file opened, every tool result, every error, and the full transcript — before every single action. In agentic coding, input tokens outnumber output by about 25:1 and make up roughly 85% of the cost. Add up to 30x run-to-run variance, and you get bills that are both high and unpredictable.
About $6 per developer per day on average, with 90% of developers staying under $12 per day, per Anthropic’s published averages cited by Vantage. The spread is roughly 100x between light and heavy users, and an all-frontier-model session can cost about 10x a mixed-model session (~$6 vs ~$0.60 for a 50-turn coding session) for the same work.
It is very hard to do reliably. Stanford found that the same agent on the same task varies up to 30x in token use, that agents fail to predict their own spend (correlation up to 0.39) and systematically underestimate cost, and that higher spend doesn’t buy higher accuracy. You can estimate a median per-task cost from the architecture, but any fixed per-task price carries a fat tail. Cap turns and context to bound the worst case.
Token efficiency varies widely between models. Stanford measured that, on the same task set, Kimi-K2 and Claude Sonnet-4.5 consumed on average over 1.5 million more tokens than GPT-5 to do the same work. Token efficiency is now a model property worth benchmarking directly, because two models with similar capability scores can differ by millions of tokens — and therefore dollars — on identical tasks.
Primary sources
- How Do AI Agents Spend Your Money? (arXiv 2604.22750) — Bai, Brynjolfsson, Pentland, Pei — Stanford Digital Economy Lab
- How are AI agents spending your tokens? — Stanford Digital Economy Lab
- AI Token Usage Guide (2026) — Use Case Cost Profiles — Iternal.ai
- The Hidden Cost Driver in Agentic Coding Sessions in 2026 — Vantage
- Context Engineering: Why More Tokens Makes Agents Worse — Morph
- 120 Quadrillion Tokens Monthly By 2030: Goldman’s Deep Dive Into The Agentic Economy — ZeroHedge (citing Goldman Sachs Research)
- AI Agents Forecast to Boost Tech Cash Flow as Usage Soars — Goldman Sachs
Last updated: June 2, 2026. Related: Capital.




