


Every vendor publishes a base rate and stops there. We stacked orchestration, STT, LLM tokens, TTS, and telephony into one neutral per-minute number per stack — with a worked 3-minute call and a sensitivity table.
What is the real AI voice agent cost per minute in 2026?
The real AI voice agent cost per minute in 2026 is $0.12–$0.20 for a typical production stack, not the $0.05–$0.07 base rate vendors advertise. The advertised number is only the orchestration layer — once you add speech-to-text, LLM tokens, text-to-speech, and telephony, the loaded cost is roughly 2.5–3x the sticker.
Here is the problem with every pricing page you will read. Retell ranks its own pricing post at #1; Famulor, Ringlyn, and Klariqo all sell agents and quote the layers that flatter their own bundle. Each one shows a base orchestration rate and lets you assume that is the bill. It is not. The base rate is the floor of a five-part stack, and the four parts they leave out are the ones that actually move the invoice.
Alatirok sells no voice product. We have nothing to upsell and no base rate to defend, so this piece does the thing none of the ranking pages do: it sums every layer — orchestration plus STT plus LLM plus TTS plus telephony — into one neutral all-in number per stack, shows the math on a real 3-minute call, and then stress-tests it for silence and concurrency. If you are comparing voice-agent stacks and want the blended price a finance team would actually sign off on, this is the decomposition.
Across the 2026 market the all-in cost per minute spans roughly $0.07 at the aggressive self-serve end to about $0.35 at premium enterprise — a 5x spread (Famulor, 2026). Where you land inside that band is decided less by which orchestrator you pick and more by which LLM and which TTS voice you wire behind it.

The five layers behind every voice agent per-minute price
Every AI voice agent cost per minute breaks into five stacked layers: orchestration, speech-to-text (STT), the LLM, text-to-speech (TTS), and telephony. Advertised rates almost always show only the orchestration layer; the other four are billed separately or passed through at provider cost.
Think of it as a stack of fees that all run against the same connected minute. The orchestration platform (Vapi, Retell) charges to manage turn-taking, latency, barge-in, and call state. STT transcribes the caller. The LLM generates the reply, billed by token but expressible per minute. TTS speaks the reply, billed by character. Telephony carries the call over the PSTN, billed per leg.
Here are the real 2026 component costs we will use throughout, drawn from the vendors’ own pages and a neutral calculator:
Bring-your-own-key platforms advertise ‘model costs at $0 if you bring your own API key’ — but that only zeroes the platform’s markup, not the underlying provider bill. You still pay OpenAI, Deepgram, and ElevenLabs directly. ‘At cost’ helps only if your negotiated cost is actually good.
| Layer | What it does | Representative 2026 cost / min | Source |
|---|---|---|---|
| Orchestration | Turn-taking, latency, barge-in, call state | $0.05 (Vapi) / $0.055 (Retell base) | Vapi, Retell AI |
| STT (speech-to-text) | Transcribes the caller in real time | ~$0.004–$0.008 (Deepgram Nova-3) | Deepgram |
| LLM | Generates the agent’s reply (token-based) | ~$0.01–$0.04 (GPT-4o); $0.003 nano → $0.16 frontier | Retell AI, Softcery |
| TTS (text-to-speech) | Speaks the reply (character-based) | ~$0.03–$0.05 (ElevenLabs Flash/Turbo) up to $0.04+ premium | ElevenLabs, Retell AI |
| Telephony | Carries the call over the PSTN | ~$0.0085 inbound / $0.014 outbound (Twilio US) | Twilio |
Vapi cost per minute: stacking the real number
Vapi cost per minute starts at a $0.05/min orchestration fee, but a realistic GPT-4o + Deepgram + ElevenLabs + Twilio stack lands at roughly $0.08–$0.15/min all-in. The $0.05 is hosting and orchestration only; Vapi passes STT, LLM, and TTS through ‘at cost’ (Vapi, 2026).
Vapi is the clearest example of the gap between sticker and bill because its pricing page is honest about being incomplete: it lists calls at $0.05/min and explicitly states model provider cost (STT, LLM, TTS) is billed ‘at cost — $0 if you bring your own API key.’ That last clause is the trap. Bringing your own key removes Vapi’s markup, not the provider’s invoice.
Here is the worked mid-point for a standard outbound stack: $0.05 orchestration + ~$0.008 Deepgram Nova-3 streaming STT + ~$0.02 GPT-4o LLM + ~$0.03 ElevenLabs Flash TTS + $0.014 Twilio outbound = about $0.122/min. Swap to a cheaper TTS voice and a GPT-4o-mini-class model and you can press toward the $0.08 floor; swap to a frontier model and a premium voice and you blow past $0.15.
The lesson: with Vapi, the platform fee is the most predictable line on the bill. Your variance lives entirely in the model and voice choices you make above it.
Retell AI pricing per minute: where the bundle hides
Retell AI pricing per minute is $0.055/min for the core voice infrastructure, building to roughly $0.11–$0.15/min once you add an LLM, a premium TTS voice, and telephony. Retell’s own page itemizes TTS at $0.015–$0.040/min and LLM from $0.003 (nano) to $0.16 (frontier) (Retell AI, 2026).
Retell’s base voice infrastructure is $0.055/min, and the company’s pricing page is more granular than most — it breaks out TTS separately ($0.015/min for platform/Cartesia/Fish voices up to $0.040/min for ElevenLabs), the LLM as a pass-through, and telephony by country. It also stacks optional per-minute add-ons that quietly inflate the bill: knowledge base (+$0.005), advanced denoising (+$0.005), safety guardrails (+$0.005), and PII removal (+$0.01).
Worked mid-point for a comparable stack: $0.055 base + ~$0.02 GPT-4o LLM + ~$0.04 ElevenLabs TTS + $0.014 Twilio = about $0.129/min. Note that Retell’s base rate already absorbs STT, which is why you do not see a separate STT line — but that also means you cannot shop STT independently the way you can on a pure-passthrough platform.
Retell’s own blog quotes a realistic production range of $0.11–$0.15/min with all components included, and $0.13–$0.31/min once premium models and features stack — which matches our decomposition almost exactly (Retell AI, 2026).
ElevenLabs conversational AI cost: the bundled alternative
ElevenLabs conversational AI cost is effectively $0.08–$0.20/min, with model tiers at roughly $0.08 (standard), $0.10 (turbo), and $0.12 (premium) per minute before telephony (ElevenLabs / Softcery, 2026). It bundles STT, LLM, and ElevenLabs’ own TTS into one rate, so the per-minute number looks higher but hides fewer surprises.
ElevenLabs Agents (its Conversational AI product) is the inverse philosophy to Vapi. Instead of a thin orchestration fee plus four pass-through layers, it sells a single per-minute rate that already contains STT, the LLM, and ElevenLabs’ best-in-class TTS. You trade the ability to shop each layer for a number that is closer to all-in out of the box.
Worked mid-point: $0.12/min premium tier + $0.014 Twilio outbound = about $0.134/min — landing right between the Vapi and Retell mid-points. The premium tier exists because TTS voice quality is ElevenLabs’ moat, and that quality is priced into every minute whether your script needs it or not.
The trade-off is real. If voice realism is the product — concierge, luxury, brand-sensitive lines — the bundle is worth it. If you are running high-volume routing where a synthetic-but-fine voice is acceptable, you are paying a premium-voice tax on every minute you may not need.
AI voice agent pricing comparison: one all-in number per stack
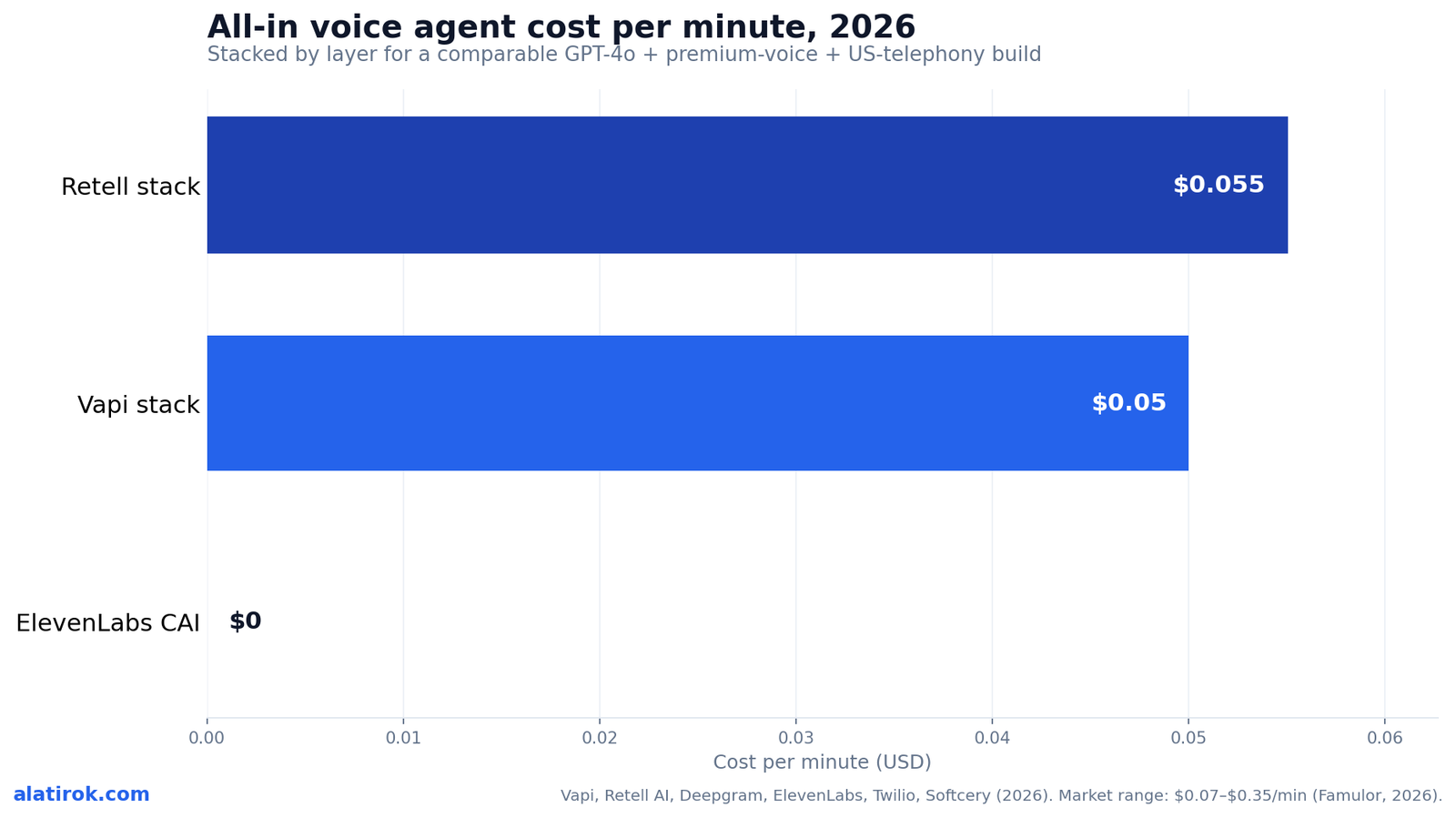
On a like-for-like GPT-4o + premium-TTS + US-telephony build, the all-in AI voice agent cost per minute is roughly $0.12 (Vapi), $0.13 (Retell), and $0.13 (ElevenLabs CAI) at the mid-point — far closer to each other than their advertised base rates ($0.05 vs $0.055 vs $0.12) suggest.
This is the chart no vendor publishes, because it erases the advantage their base rate is meant to imply. When you stack every layer, the orchestration fee — the number everyone competes on — turns out to be a minority of the bill. The LLM and TTS layers, which buyers treat as an afterthought, are where the money actually goes.
The stacked-bar view below is our original decomposition. Each bar is one stack, segmented by layer, summed to a single all-in number, with the market range band ($0.07 aggressive self-serve to $0.35 premium enterprise) drawn for context.
Pros
Cons
Worked example: what a 3-minute call actually costs
A typical 3-minute outbound call costs about $0.37 on a mid-point Vapi stack, $0.39 on Retell, and $0.40 on ElevenLabs Conversational AI — roughly 11–13 cents per minute connected. At 10,000 minutes/month that is $1,220–$1,340, before per-feature add-ons and concurrency lines.
Multiply the mid-points out and the abstraction becomes a budget. The per-call delta between the three stacks is about three cents — noise next to the LLM and TTS choices inside each one. This is exactly why base-rate shopping misleads: you optimize the 5-cent line and ignore the 5-cent-to-15-cent lines stacked on top of it.
The table below scales the mid-point all-in cost across common call volumes so you can sanity-check a vendor quote against the loaded math.
“The orchestration fee everyone competes on is a minority of the bill. The LLM and TTS layers buyers treat as an afterthought are where the money actually goes.”
Alatirok analysis, 2026
| Volume | Vapi (~$0.122/min) | Retell (~$0.129/min) | ElevenLabs CAI (~$0.134/min) |
|---|---|---|---|
| 3-minute call | $0.37 | $0.39 | $0.40 |
| 100 calls (3 min avg) | $36.60 | $38.70 | $40.20 |
| 1,000 min / mo | $122 | $129 | $134 |
| 10,000 min / mo | $1,220 | $1,290 | $1,340 |
| 100,000 min / mo | $12,200 | $12,900 | $13,400 |
Sensitivity: how silence, barge-in, and concurrency change the bill
Budget for $0.12–$0.20/min, then optimize the LLM and TTS — not the base rate
Because you pay for connected wall-clock time, silence and hold music cost the same per minute as productive speech — so a call with 30% dead air costs ~30% more per useful minute. Concurrency lines and per-feature add-ons (knowledge base, PII redaction) can add $0.01–$0.025/min and a per-line monthly fee on top of usage.
Two variables that no base rate captures will swing your real number more than the vendor you choose. The first is talk-time efficiency. Voice agents bill the connected minute, not the productive minute, so long IVR menus, hold music, slow endpointing, and a caller who rambles all inflate cost without adding value. Tight endpointing and reliable barge-in (letting the caller interrupt) are cost levers, not just UX polish — they shorten the connected minute.
The second is scale structure. Vapi includes 10 concurrent lines then charges per line; Retell includes 20 then charges monthly per line plus its per-minute add-ons. At 100,000 minutes/month those lines and add-ons can quietly add a four-to-five-figure layer that never appears in a per-minute comparison.
The sensitivity table shows how a nominal $0.122/min Vapi mid-point shifts under realistic conditions.
| Scenario | Adjustment | Effective cost / connected min |
|---|---|---|
| Baseline (GPT-4o, Flash TTS) | — | $0.122 |
| 30% silence / hold per useful min | ÷0.70 useful | ~$0.174 per useful min |
| Downgrade to mini-class LLM | −$0.015 LLM | ~$0.107 |
| Premium frontier LLM | +$0.12 LLM | ~$0.242 |
| + Knowledge base + PII redaction | +$0.015 | ~$0.137 |
| Cheap synthetic TTS voice | −$0.025 TTS | ~$0.097 |
Builder’s take
I have shipped voice into both Cyntr and Loomfeed, and the single most expensive mistake I see buyers make is budgeting off the headline number. Here is how I actually model it.
- Budget off the loaded minute, not the base rate. A $0.05/min orchestration fee routinely lands at $0.12–$0.15 once STT, LLM, TTS, and telephony are added. Plan for 2.5–3x the sticker.
- Your LLM and TTS choices move the bill more than your platform choice. Swapping a premium TTS voice for a Flash-tier voice can save more per minute than switching orchestrators entirely.
- Silence is not free. You pay for connected wall-clock time, so a chatty IVR with long hold music or dead air burns the same per-minute rate as productive talk. Aggressive endpointing and barge-in are cost levers, not just UX.
- Concurrency lines and per-feature add-ons (knowledge base, PII redaction, denoising) are the quiet six-figure surprise at enterprise scale. Price the whole bundle before you sign.
- BYOK is a trap if you do not have negotiated model rates. ‘At cost’ only helps if your cost is good — otherwise the bundled platforms with volume discounts can be cheaper.
Frequently asked questions
A typical production stack lands at $0.12–$0.20 per minute all-in. The full market spans about $0.07/min for aggressive self-serve builds to $0.35/min for premium enterprise — a roughly 5x spread (Famulor, 2026). The advertised base rate of $0.05–$0.07 covers only the orchestration layer, not the STT, LLM, TTS, and telephony stacked on top.
Vapi charges a $0.05/min orchestration fee, but a realistic GPT-4o + Deepgram STT + ElevenLabs TTS + Twilio telephony stack lands at about $0.08–$0.15/min all-in. Vapi passes model costs through ‘at cost’ — which removes its markup but not the underlying OpenAI, Deepgram, and ElevenLabs bills (Vapi, 2026).
Retell AI’s base voice infrastructure is $0.055/min, building to roughly $0.11–$0.15/min once you add an LLM, a TTS voice, and telephony. Retell’s own page itemizes TTS at $0.015–$0.040/min, LLM from $0.003 (nano) to $0.16 (frontier), plus per-minute add-ons for knowledge base, denoising, and PII removal (Retell AI, 2026).
ElevenLabs Conversational AI (Agents) runs about $0.08/min standard, $0.10/min turbo, and $0.12/min premium, before telephony — effectively $0.08–$0.20/min all-in. Unlike Vapi or Retell, it bundles STT, the LLM, and ElevenLabs’ own premium TTS into one rate, so the number is higher but hides fewer line items (ElevenLabs / Softcery, 2026).
Advertised base rates show only the orchestration layer. The four layers they exclude — STT (~$0.004–$0.008), LLM (~$0.01–$0.04), TTS (~$0.03–$0.05), and telephony (~$0.014) — typically add up to more than the base rate itself, pushing the loaded cost to roughly 2.5–3x the sticker. That is why a $0.05/min platform commonly bills $0.12–$0.15/min.
Three levers, in order of impact: downgrade the LLM to a mini-class model where quality allows (saves ~$0.01–$0.04/min); pick a cheaper TTS voice when premium realism isn’t required (saves ~$0.02–$0.03/min); and shorten connected time with tight endpointing and barge-in so you pay for fewer silent or hold minutes. Switching orchestrators usually saves the least, because the base fee is the smallest variable layer.
Primary sources
- Vapi Pricing (orchestration $0.05/min, BYOK at-cost) — Vapi
- Retell AI Pricing ($0.055/min voice infra + components) — Retell AI
- AI Voice Agent Pricing 2026: What 10 Platforms Actually Cost Per Minute — Famulor
- AI Voice Agent Cost Calculator 2026 (component breakdown) — Softcery
- Deepgram Pricing (Nova-3 STT per minute) — Deepgram
- ElevenLabs Pricing (Conversational AI / Agents) — ElevenLabs
- Programmable Voice Pricing in United States — Twilio
- AI Voice Agent Pricing in 2026: Full Cost Breakdown & ROI — Retell AI
Last updated: June 2, 2026. Related: Products.




