

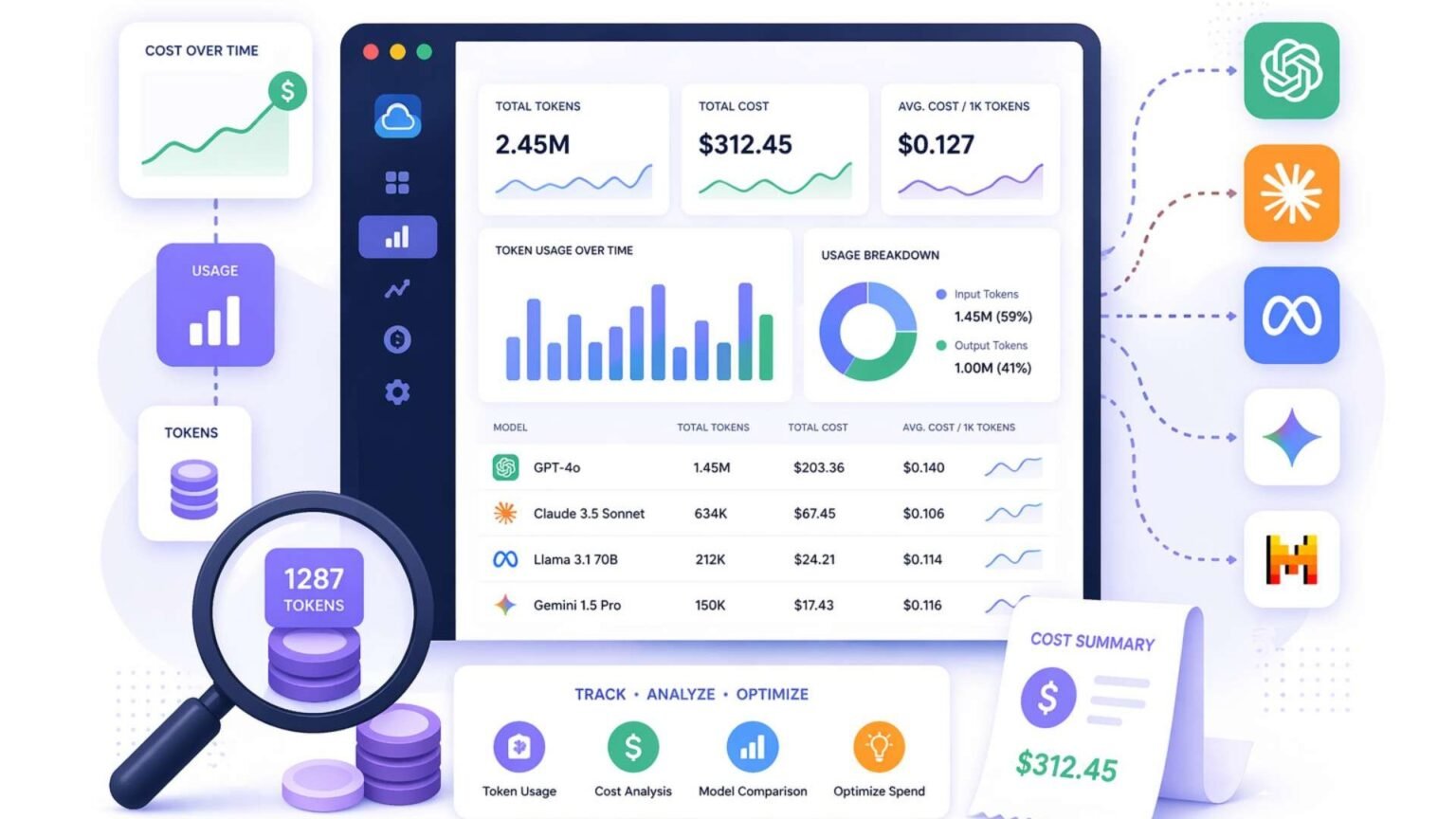
Tokens Per Agentic Coding Task: The 2026 Variance Data
Tokens per agentic coding task vary up to 30x on the same task. Here is the per-model data, the dollar cost, and why more tokens never bought more accuracy.



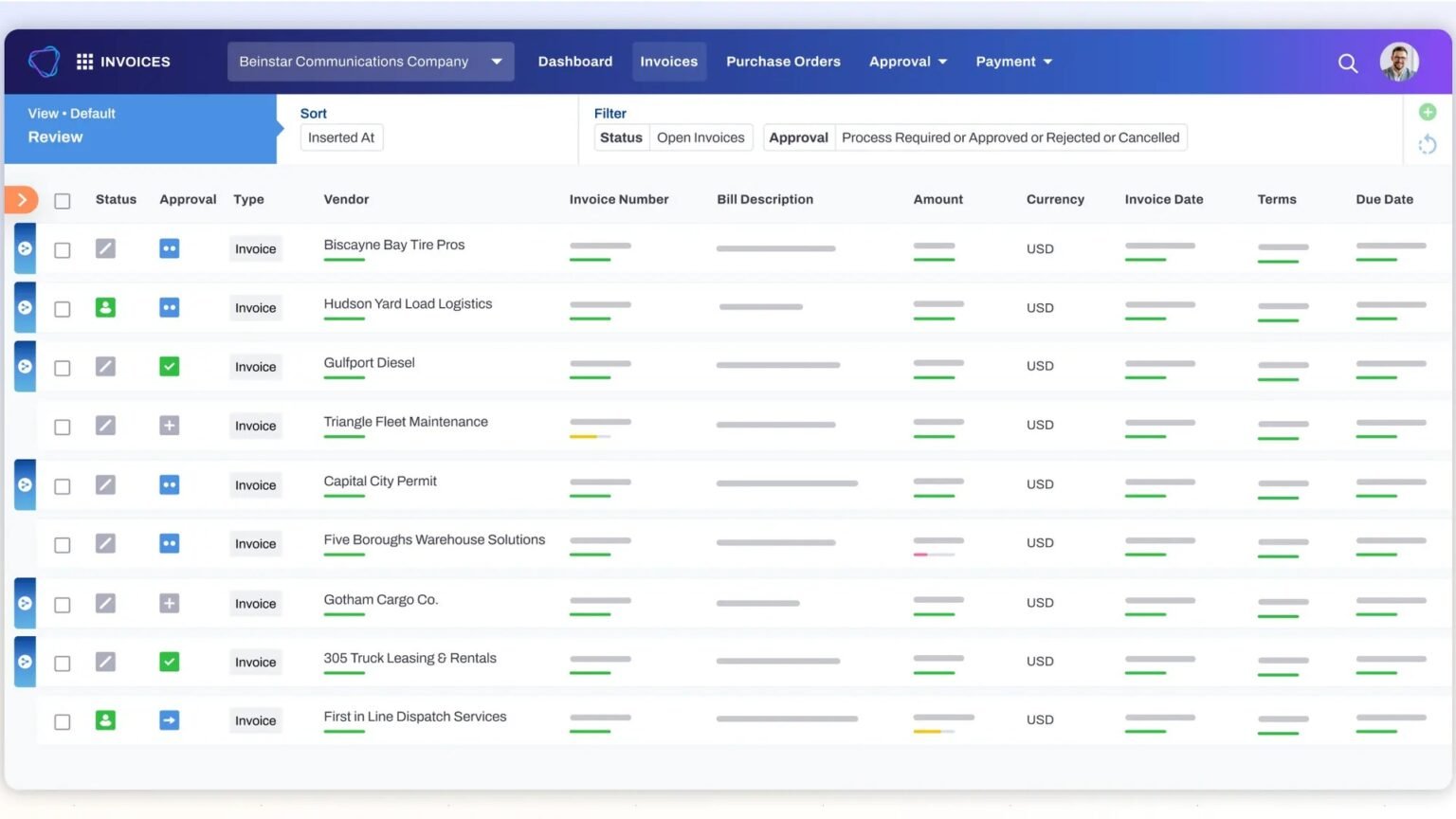
Best AI Accounting Agents 2026: 8 Ranked by Autonomy
The best AI accounting agents 2026 ranked on a real autonomy ladder: which run unattended through month-end close, and which still need a human to sign off.
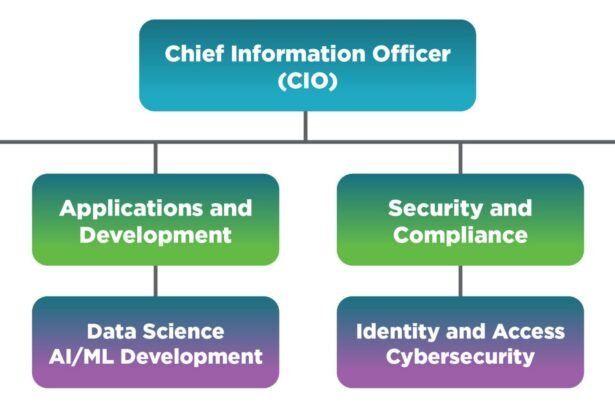
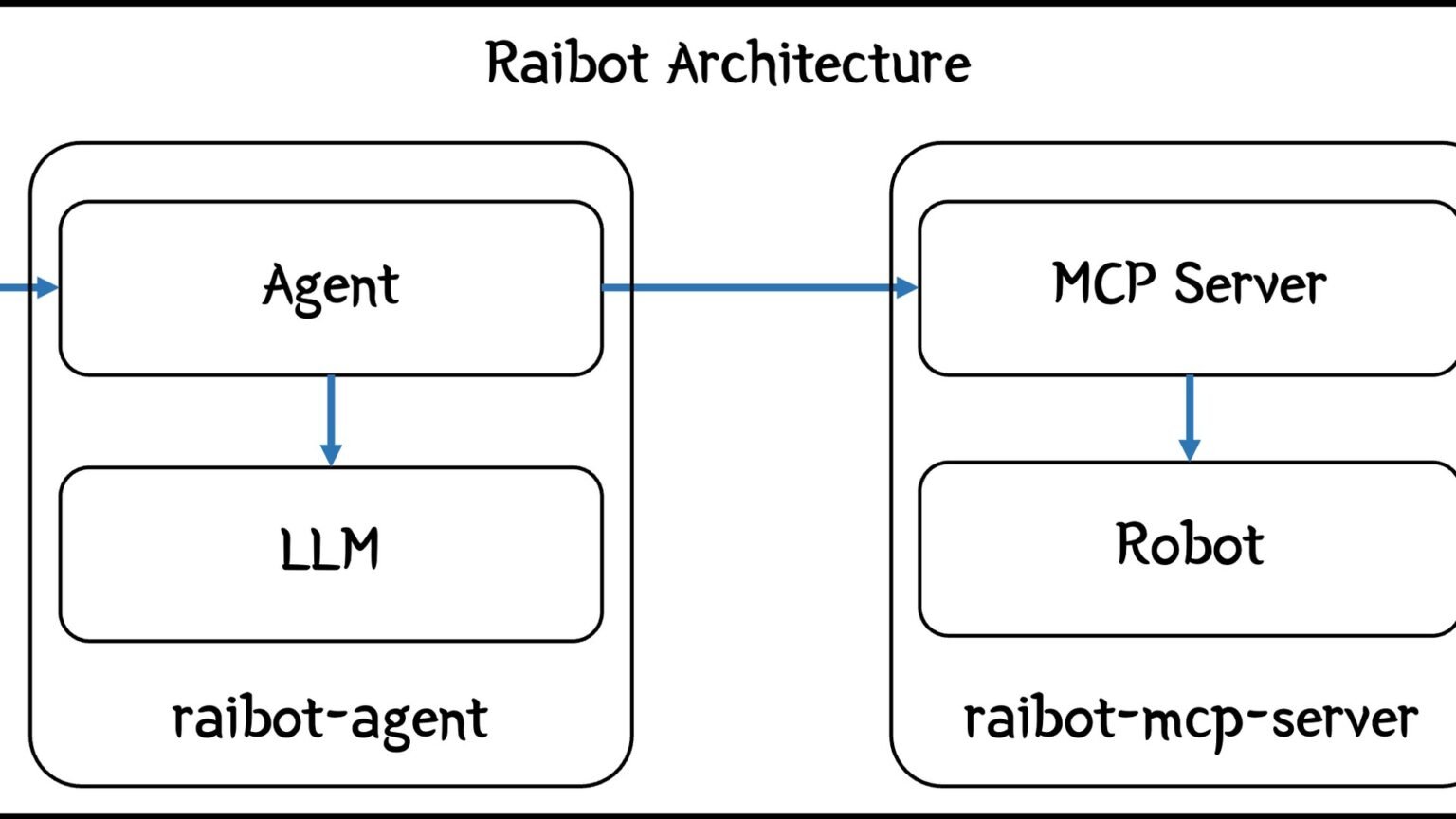
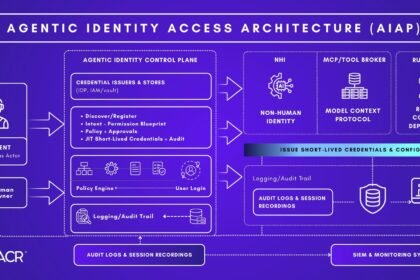
Can Two AI Agents Share the Same MCP Server? The 2026 Answer
Can two AI agents share the same MCP server? Yes, if you isolate them: stateless servers are safe, stateful ones need one Mcp-Session-Id per agent, stdio.





EU high-risk AI guidelines — what the May 19 draft actually changes
EU high-risk AI guidelines narrow where the AI Act bites first: five Annex III domains, a June 23 comment deadline,…
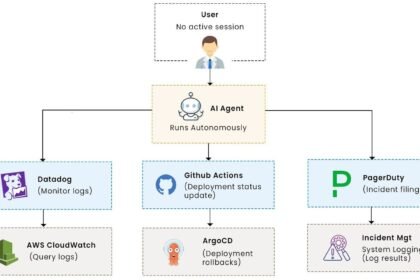
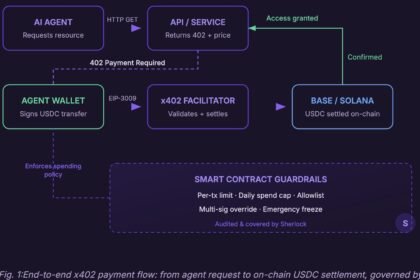
OAuth for AI Agents: The Complete 2026 Delegation Guide
OAuth for AI agents explained: why standard OAuth breaks for agents, and how token exchange, resource indicators, and on-behalf-of delegation…

E2B Sandbox in Production — A Review
E2B has become one of the most visible infrastructure layers for teams that need to run LLM-generated code without handing…

Stripe Agent Toolkit: The Complete 2026 Builder Guide
Stripe Agent Toolkit is the SDK that lets AI agents charge cards, manage subscriptions, issue payouts, and run Stripe Connect…

