

Every leaderboard shows you the Elo. None of them tells you which model is actually cheapest within 10% of the leader, or what a 47% win rate vs human experts means for staffing. Here is GDPval translated into a buying decision.
What is GDPval, and why does it matter in 2026?
The GDPval benchmark 2026 is OpenAI’s evaluation of whether AI models can produce real, economically valuable work deliverables — slide decks, spreadsheets, legal reviews, engineering specs — at a quality human experts would accept. Unlike abstract reasoning tests, it grades the artifact, not the answer. That single design choice is why it has become the benchmark operators actually cite when deciding what to deploy.
GDPval covers 1,320 tasks spanning 44 occupations across the nine largest sectors of the U.S. economy, with each task authored by industry experts averaging 14 years of experience (OpenAI, arXiv:2510.04374). The tasks are deliberately mundane and real: “analyze this financial report and build a stakeholder deck,” “review this contract for risk.” Models are scored through blind pairwise grading, where expert reviewers compare an AI’s deliverable against a human’s and rule it better, as good as, or worse.
The reason the GDPval benchmark 2026 matters more than the alphabet soup of older tests is economic framing. OpenAI reports that the human baseline averages roughly 7 hours and about $361 in wages per task, and that frontier models complete the same work roughly 100x faster and 100x cheaper. That converts a benchmark score into a budget line — which is exactly what every raw leaderboard refuses to do for you.
GDPval measures whether a model’s finished work product would survive an expert’s blind review — not whether it can solve a puzzle. Score it like you’d score a contractor’s deliverable.
GDPval leaderboard: scores by model (June 2026)
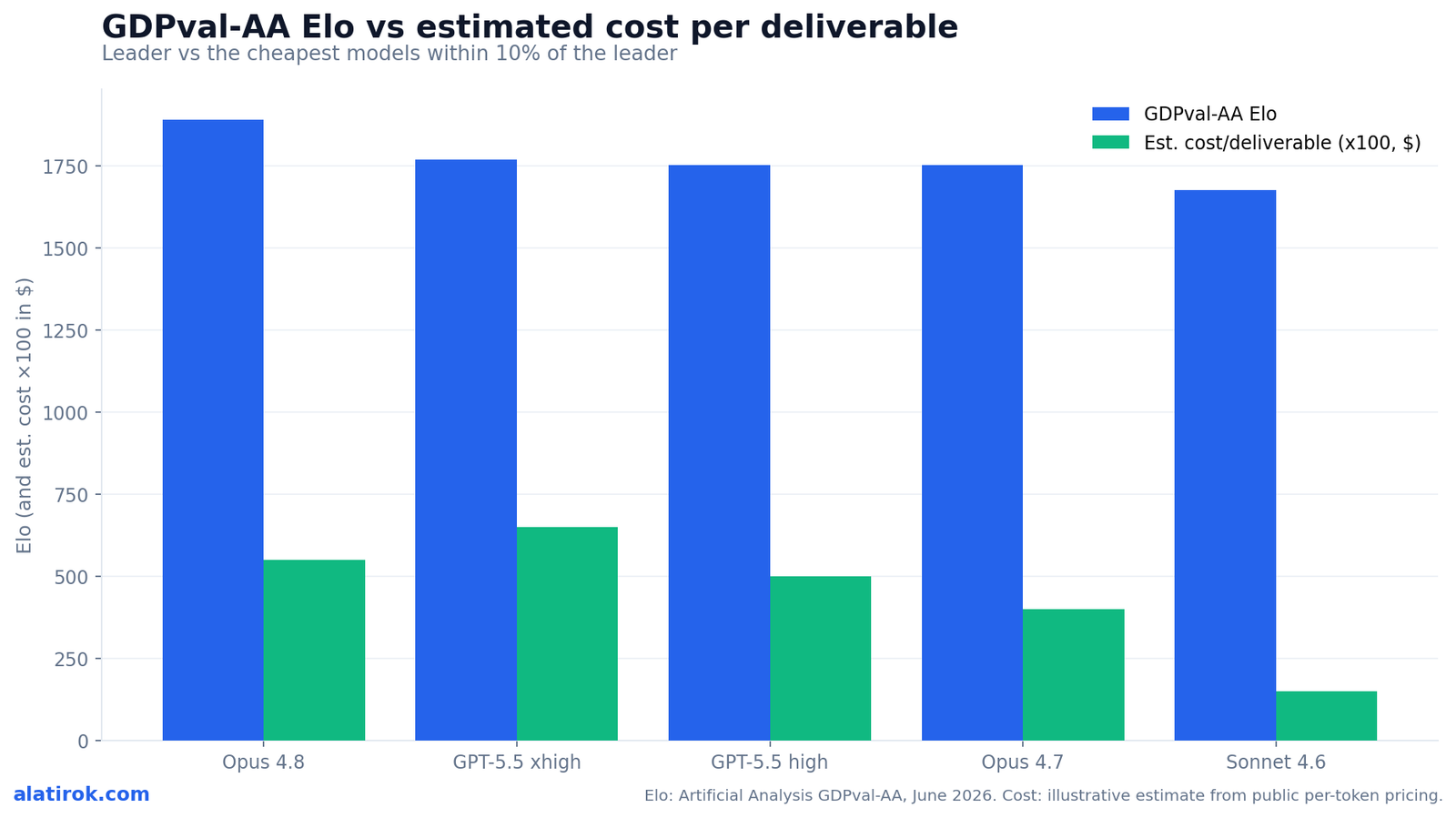
On the Artificial Analysis GDPval-AA leaderboard, Claude Opus 4.8 leads at 1,890 Elo as of June 2026, with GPT-5.5 (xhigh) at 1,769 and GPT-5.5 (high) at 1,753. Opus 4.8 sits 121 Elo points clear of second place — an implied head-to-head win rate near 67% over GPT-5.5 xhigh (Artificial Analysis).
Two leaderboards are in play and they do not agree, which trips up most buyers. The GDPval-AA (text) track, run by Artificial Analysis using the open Stirrup agentic harness, puts Opus 4.8 on top. OpenAI’s own GDPval-MM (multimodal) reporting puts GPT-5.5 first at 0.849, alongside 82.7% on Terminal-Bench 2.0 (MarkTechPost, Apr 2026). Same family of benchmark, different deliverable mix, different winner.
Here is the GDPval leaderboard as a model-selection table — Elo plus the practical context the auto-updating ranking pages leave out.
| Model | GDPval-AA Elo | Standard API price (in/out per 1M) | Est. cost / deliverable | Position |
|---|---|---|---|---|
| Claude Opus 4.8 (Max Effort) | 1,890 | $5 / $25 | ~$4–7 | Leader — best quality, premium spend |
| GPT-5.5 (xhigh) | 1,769 | ~$5 / $30 | ~$5–8 | Within 10% of leader on Elo |
| GPT-5.5 (high) | 1,753 | ~$5 / $30 | ~$4–6 | Within 10%, cheaper effort tier |
| Claude Opus 4.7 (Max Effort) | 1,753 | $5 / $25 | ~$3–5 | Last-gen, strong value |
| Claude Sonnet 4.6 (max) | 1,676 | lower | ~$1–2 | Volume workhorse, ~11% below leader |
GDPval cost per task: which model is cheapest within 10% of the leader?
The buyer’s answer: GPT-5.5 (high) at 1,753 Elo is the cheapest model that lands within 10% of the 1,890-Elo leader, making it the rational default for high-volume pipelines where every deliverable’s GDPval cost per task compounds. A 10% band off 1,890 Elo runs down to roughly 1,700, which captures both GPT-5.5 tiers and last-gen Opus 4.7 — a crowded value zone the leader’s trophy hides.
This is the gap every ranking page leaves open. Artificial Analysis, llm-stats, Epoch and the launch posts all give you Elo on the y-axis and stop. But Elo is a quality signal, not a spend signal. A 1,890-Elo leader can lose decisively on cost-per-deliverable when you multiply across 50,000 monthly tasks. The discipline borrowed from ARC-AGI-2 — which now reports humans at ~$17/task versus Gemini 3 at ~$77/task (IntuitionLabs) — is to plot both axes and find the efficiency frontier.
Because no vendor publishes a per-deliverable GDPval cost, we derive an illustrative range from public per-token pricing (Opus 4.8 at $5/$25, GPT-5.5 at ~$5/$30 per million tokens) applied to a typical multi-step agentic run. Treat the absolute dollars as directional; the ratios are what drive the decision.
What does GDPval win rate vs human experts actually mean for staffing?
A GDPval win rate vs human experts of ~47% means the model’s deliverable was judged better than or equal to a human expert’s in nearly half of blind comparisons — which is a signal to add AI-plus-review capacity, not to cut headcount. In OpenAI’s grading, top models reached win-or-tie rates approaching 47.6% (Claude Opus 4.1) and standalone win rates up to 40.6% for GPT-5-class models.
Read that number the way a staffing manager would, not the way a press release does. A 47% tie-or-win rate is also a 53% lose-or-needs-rework rate. For staffing math, that means roughly half of generated deliverables still require a human to catch, correct, or rebuild. The model is a force multiplier on a reviewer, not a replacement for the expert.
This reframing is the practical heart of the GDPval benchmark 2026. The win rate tells you the size of your review queue, and the cost-per-task tells you whether running the model is cheaper than the labor it offloads. A model that wins half the time at $5/deliverable against a $361 human baseline is economically transformative even if it never crosses 50%.
“Win rate vs human experts isn’t a quality grade — it’s the size of the review queue you still have to staff.”
Alatirok analysis of OpenAI GDPval results
GDPval-AA vs GDPval-MM: why the two tracks pick different winners
GDPval-AA scores text-centric deliverables and is led by Claude Opus 4.8 (1,890 Elo); GDPval-MM scores multimodal deliverables — slides, diagrams, visual artifacts — and is led by GPT-5.5 at 0.849. Choosing the wrong track is the most common GDPval misread of 2026.
The divergence is structural, not noise. GDPval-AA, as run by Artificial Analysis through the open Stirrup harness, leans on shell access, file manipulation and web search to produce documents and spreadsheets. GDPval-MM weights the model’s ability to read and generate visual content — exactly where GPT-5.5’s retrained vision and computer-use stack shines (MarkTechPost). If your real workload is investor decks and annotated screenshots, the AA leaderboard will point you at the wrong model.
Practically: map your deliverable type to the track first, then read the leaderboard. Text-heavy legal, finance, and research output? Trust GDPval-AA. Slide-, diagram-, and screen-heavy output? Trust GDPval-MM. Treating one Elo as the universal score is how teams deploy a benchmark leader that underperforms on their actual artifacts.
Pros
Cons
GDPval vs SWE-bench: which benchmark predicts real value?
GDPval vs SWE-bench comes down to scope: SWE-bench measures whether a model can resolve a verified GitHub issue, while GDPval measures whether a model can produce an accepted professional deliverable across 44 occupations. SWE-bench predicts coding agent reliability; GDPval predicts knowledge-work substitution.
SWE-bench (and Terminal-Bench 2.0, where GPT-5.5 hits 82.7%) is pass/fail and binary: did the test suite go green? That is perfect for engineering teams and useless for a paralegal, analyst, or consultant whose output has no unit tests. GDPval fills that gap by grading subjective deliverables through expert review, which is why it spans economics, not just software.
For a buyer, the rule is simple. If you’re deploying coding agents, weight SWE-bench and Terminal-Bench. If you’re deploying agents for documents, analysis, and client deliverables, weight GDPval — and within GDPval, weight the track that matches your output type. The two benchmarks answer different questions; using SWE-bench to predict knowledge-work value is the category error this benchmark was built to fix.
A model topping SWE-bench can still produce mediocre slide decks, and a GDPval leader isn’t guaranteed to fix your flaky test suite. Match the benchmark to the deliverable.
How to read the GDPval leaderboard like an operator
1,890
Opus 4.8 GDPval-AA Elo
Leader, June 2026 (Artificial Analysis)
0.849
GPT-5.5 GDPval-MM score
Multimodal track leader (MarkTechPost)
~47.6%
Top win-or-tie vs human experts
Claude Opus 4.1 in OpenAI grading
~$361 / 7h
Human-expert baseline per task
Average wage + time (OpenAI)
Best default for most operators: GPT-5.5 (high) or Opus 4.7
The operator’s workflow: pick your track (AA vs MM), draw a 10% band below the leader’s Elo, then choose the cheapest model inside that band that matches your deliverable type — not the top of the table. Applied to June 2026 data, that yields GPT-5.5 (high) or last-gen Opus 4.7 for most text pipelines, with Opus 4.8 reserved for highest-stakes, low-volume work.
Then layer in win rate as a staffing input, not a quality grade: a ~47% tie-or-win rate means roughly half your output needs human review, so budget reviewer hours alongside token spend. Finally, sanity-check against your own samples — GDPval is a national-economy average across 44 occupations, and your specific occupation may diverge sharply from the headline.
That is the entire decision the raw leaderboards skip. Elo tells you who’s best; cost-per-task tells you who’s affordable; win rate tells you how much human review you still owe; and the AA/MM split tells you whether the leaderboard even applies to your work. Run all four and the GDPval benchmark 2026 stops being a scoreboard and becomes a procurement tool.
Builder’s take
I run model selection for two production AI products, and GDPval is the first benchmark I actually trust for the question that matters: can this model produce a deliverable a human would accept? But I have watched teams misread it badly. Three things I tell everyone:
- The leader is almost never the right default. Opus 4.8 at 1,890 Elo is genuinely best, but on a high-volume pipeline the model that lands within 10% of the leader at a third of the cost wins on annual spend, not the trophy holder.
- Win rate vs human experts is a staffing number, not a quality number. A 47% tie-or-win rate means roughly half your deliverables still need a human reviewer — so budget for review, not replacement.
- GDPval-AA and GDPval-MM are not interchangeable. If your work is slides, spreadsheets and screenshots, the text-only Elo will mislead you. Pick the track that matches your actual deliverable type.
Frequently asked questions
GDPval is OpenAI’s benchmark measuring whether AI models can produce real, economically valuable work deliverables — documents, spreadsheets, slides, legal reviews — at expert-acceptable quality. It covers 1,320 tasks across 44 occupations in the nine largest U.S. economic sectors, graded by blind pairwise expert comparison against human-produced work.
Claude Opus 4.8 leads the GDPval-AA (text) leaderboard at 1,890 Elo as of June 2026, ahead of GPT-5.5 xhigh (1,769) and GPT-5.5 high (1,753), per Artificial Analysis. On the GDPval-MM (multimodal) track, GPT-5.5 leads at 0.849. The two tracks crown different winners.
It’s the share of blind comparisons where the model’s deliverable was judged better than or equal to a human expert’s. Top models reach roughly 47% win-or-tie. For staffing, that means about half of generated deliverables still need human review — so it sizes your review queue rather than signaling full replacement.
No vendor publishes a native per-deliverable figure, but OpenAI reports frontier models complete GDPval tasks roughly 100x cheaper than the ~$361 human-expert baseline. Derived from public per-token pricing (Opus 4.8 at $5/$25, GPT-5.5 at ~$5/$30 per million tokens), a typical multi-step deliverable lands in the low single-digit dollars.
GDPval-AA scores text-centric deliverables (documents, spreadsheets, code-adjacent work) and is led by Claude Opus 4.8. GDPval-MM scores multimodal deliverables (slides, diagrams, visual artifacts) and is led by GPT-5.5. Pick the track matching your actual output type; using the wrong one points you at the wrong model.
It depends on the work. SWE-bench measures whether a model can resolve verified GitHub issues (binary pass/fail) and predicts coding-agent reliability. GDPval grades subjective professional deliverables across many occupations and predicts knowledge-work value. Use SWE-bench for coding agents and GDPval for document, analysis, and client-deliverable workloads.
Primary sources
- GDPval-AA Leaderboard — Artificial Analysis
- GPT-5.5 is the new leading AI model — Artificial Analysis
- GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks — arXiv (OpenAI)
- Measuring the performance of our models on real-world tasks — OpenAI
- OpenAI Releases GPT-5.5, scores 82.7% on Terminal-Bench 2.0 and 84.9% on GDPval — MarkTechPost
- Claude Opus 4.8 Pricing 2026 — Finout
- GPT-5.2 & ARC-AGI-2: A Benchmark Analysis — IntuitionLabs
- Claude Opus 4.8 Beats GPT-5.5 On GDPval-AA — OfficeChai
Last updated: June 6, 2026. Related: Observability.




