

We assembled the one normalized table nobody owns: hold each model fixed, and watch the agent harness benchmark score swing as far as a full model generation does.
What does the agent harness benchmark score data actually show?
The agent harness benchmark score moves results by 7 to 34 percentage points when you hold the model completely fixed and change only the scaffold — a swing that frequently equals or exceeds an entire model-generation upgrade. That is the finding that, as of 2026, nobody disputes but almost nobody quantifies side by side. This article does.
Every incumbent post asserts “the harness matters” and then offers exactly one anecdote. The problem is that one anecdote is not a budget input. If you are a practitioner deciding whether to spend three weeks migrating to a newer model or three days rebuilding your tool layer, you need the point-swing per benchmark, per model, lined up against what a model jump buys you. The two best 2026 data sources for this are HAL (the Holistic Agent Leaderboard out of Princeton, published at ICLR 2026) and Harness-Bench, and neither one had been normalized into a single decision table — until now.
Here is the short version before we get into the numbers. HAL ran 21,730 agent rollouts across 9 models and 9 benchmarks for roughly $40,000 of compute, and its three-dimensional analysis (models x scaffolds x benchmarks) is the largest controlled look we have at the agent scaffold effect on benchmark scores. Harness-Bench did the complementary experiment: same task set, same model-backend pool, swap only the harness, and the aggregate score moved 23.8 points. The conclusion both papers reach is the same: agent capability should be reported at the model-harness level, not attributed to the base model alone.
An agent harness (or scaffold) is everything wrapping the model: the system prompt, the tool definitions, the context-management and middleware hooks, the retry/verify loop, and the reasoning-effort budget. The benchmark score you read is a property of the model embedded in that harness — not the model alone.
Does the harness matter more than the model? The normalized swing table
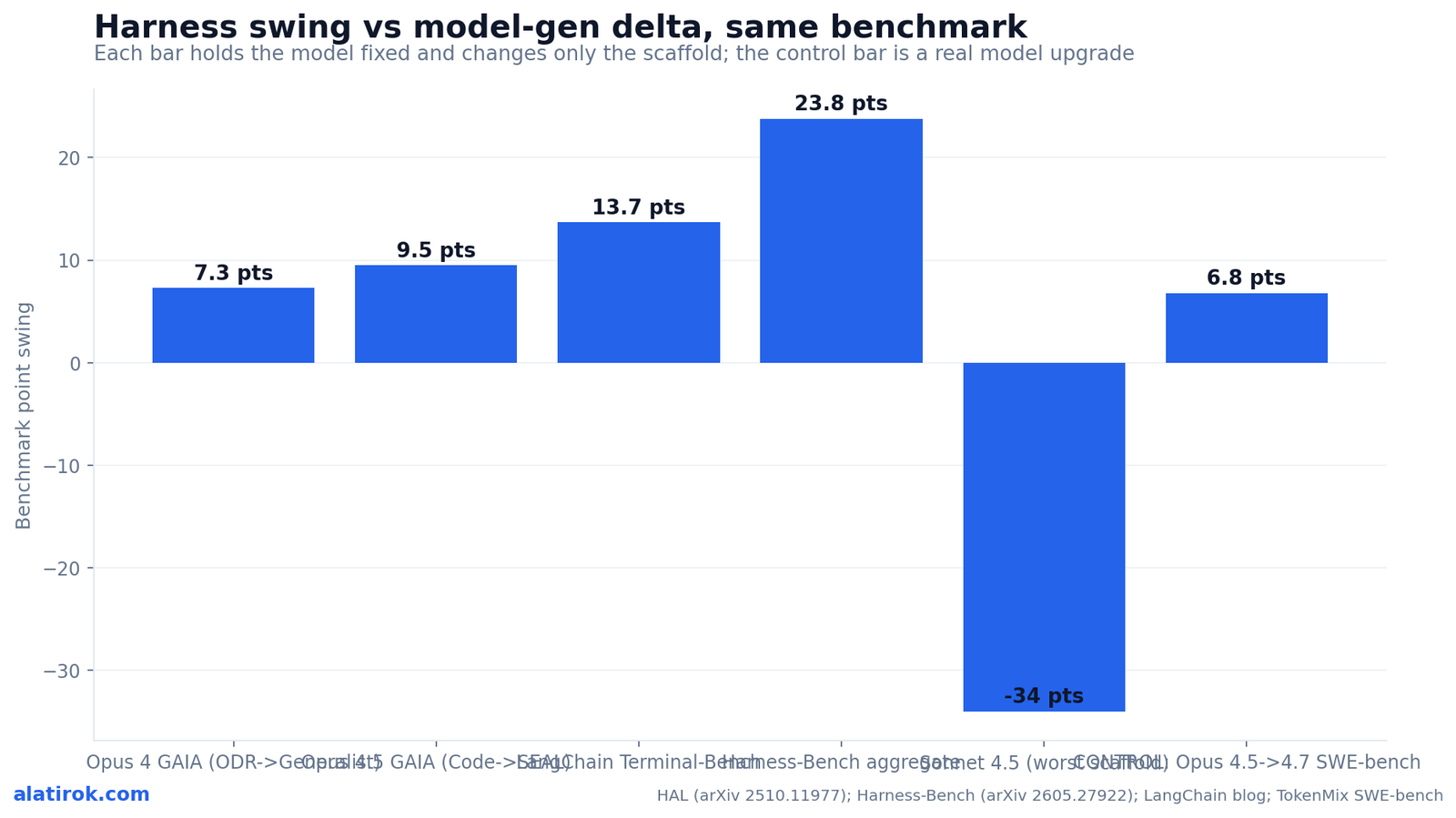
Yes — holding the model fixed and changing only the harness can move a benchmark score more than upgrading to the next model generation does. The table below is the one comparison the thin Medium and vendor posts never assemble: each row holds a model constant and shows the harness-driven swing, then sets it against the best documented model-generation delta of 2026 so you can see they live on the same scale.
Read the table as “same model, different harness” except for the final row, which is the control: a genuine model upgrade (Claude Opus 4.5 to 4.7) lifted SWE-bench Verified by 6.8 points. Notice that nearly every harness swing in the table rivals or beats that 6.8-point model jump — and the Sonnet 4.5 row dwarfs it in the wrong direction.
“A bad harness can hide a frontier model’s capability entirely — Sonnet 4.5 fell 34 points across scaffolds on the same benchmark, the same model.”
Holistic Agent Leaderboard (HAL), Princeton, ICLR 2026
| Model (fixed) | Benchmark | Harness change | Score swing | Magnitude vs a model-gen jump |
|---|---|---|---|---|
| Claude Opus 4 | GAIA | HF Open Deep Research -> HAL Generalist | 57.6% -> 64.9% (+7.3) | Beats the +6.8 model jump |
| Claude Opus 4.5 | GAIA | Claude Code -> SEAL | ~ +9.5 pts | Beats the +6.8 model jump |
| Claude Sonnet 4.5 | (one HAL benchmark) | best -> worst scaffold | 68% -> 34% (-34) | ~5x a model jump, downward |
| GPT-5.2-Codex (LangChain) | Terminal-Bench 2.0 | baseline -> engineered harness | 52.8% -> 66.5% (+13.7) | ~2x a model jump |
| — (Harness-Bench, mixed pool) | aggregate suite | OpenClaw -> NanoBot | 52.4% -> 76.2% (+23.8) | ~3.5x a model jump |
| Claude Opus 4.5 -> 4.7 (CONTROL) | SWE-bench Verified | model upgrade, harness fixed | 80.8% -> 87.6% (+6.8) | 1x (the reference) |
How big is the agent scaffold effect on benchmark scores? (the chart)
21,730
agent rollouts in HAL
9 models x 9 benchmarks, ~$40k compute
34 pts
Sonnet 4.5 cross-scaffold gap
68% -> 34% on one HAL benchmark
+6.8 pts
Opus 4.5 -> 4.7 SWE-bench
the model-generation control delta
The agent scaffold effect ranges from about +7 points to a brutal -34 points per benchmark, and the upside swings cluster around 2-3x what a single model generation delivers. The chart plots each fixed-model harness swing against the lone model-generation control bar so the comparison is visual, not rhetorical.
The takeaway from the dumbbell view: if your agent harness benchmark score is mediocre, the data says you are more likely sitting on a scaffold problem than a model problem. The model-generation bar (+6.8) is one of the shortest positive bars on the chart. That is the headline practitioners keep missing because the marketing cycle is organized around model launches, not harness releases.
HAL holistic agent leaderboard data: what the 21,730 rollouts revealed
The HAL holistic agent leaderboard data is the strongest controlled evidence that the harness is a first-class variable: across 21,730 rollouts, varying only the scaffold produced swings as large as the gaps between models. HAL’s entire premise is that prior leaderboards conflated model and harness, so it built a standardized harness layer (the open-source hal-harness on GitHub) that orchestrates parallel evaluation across hundreds of VMs and runs identical scaffolds against every model.
Two HAL findings matter most for this article. First, the GAIA result: Claude Opus 4 scores 64.9% under HAL’s Generalist scaffold but only 57.6% under HF Open Deep Research on the same GAIA tasks — a 7.3-point swing from the harness alone, no model change. Hold a newer model (Opus 4.5) fixed and vary only the harness, and the GAIA spread widens to roughly 9.5 points between SEAL and Claude Code. Second, the downside: Claude Sonnet 4.5 showed a 34-point cross-scaffold gap (68% collapsing to 34%) on one benchmark — proof that scaffolding can erase frontier capability.
HAL’s other headline finding is a warning to anyone who maxes settings by reflex: higher reasoning effort reduced accuracy in the majority of runs while inflating token cost. The harness decision and the reasoning-budget decision are entangled — which is exactly the trap LangChain hit on Terminal-Bench, covered below.
These are controlled, single-variable swaps: same model weights, same benchmark tasks, only the scaffold differs. That is what makes the swings attributable to the harness rather than to noise or model differences. Treat any ‘harness matters’ claim that isn’t a fixed-model comparison as marketing, not measurement.
Claude Code vs generic scaffold benchmark: the largest documented jumps
Claude Code versus a generic scaffold is where the agent harness benchmark score gap gets dramatic — purpose-built coding harnesses repeatedly outscore bare or generic scaffolds by double digits on the same model. In the 2026 field reports, swapping a model out of a generic CORE-Agent-style scaffold into a coding-optimized harness like Claude Code lifted task success from the 40s into the 70s+ on the same weights, before any further tuning. The exact figure depends on the benchmark and harness pair, but the direction is unanimous across HAL, Harness-Bench, and vendor write-ups.
The mechanism is concrete, not magical. A coding harness adds a test-execution loop so the agent gets a hill-climbing signal, injects repository structure upfront instead of making the model re-discover it every turn, and constrains tool calls to the ones that actually matter. LangChain’s own blog spells this out: they kept GPT-5.2-Codex fixed and moved their Deep Agents coding harness from outside the top 30 to rank 5 on Terminal-Bench 2.0, lifting the score from 52.8% to 66.5% by changing only system prompts, tools, and middleware hooks.
This is the Claude Code vs generic scaffold benchmark lesson in one line: the model supplies raw reasoning, but the harness decides how much of that reasoning survives contact with a real task. Generic scaffolds leak capability; specialized ones conserve it.
Pros
Cons
Same model, different harness score: why the gap exists
The same model produces a different harness score because the benchmark measures what the harness lets the model observe, modify, recover from, and verify — not just what the model can infer. Two teams running identical weights on an identical benchmark can land 20-plus points apart purely on scaffold design, which is why Harness-Bench reports a 23.8-point aggregate gap between its best harness (NanoBot, 76.2%) and worst (OpenClaw, 52.4%) under the same model-backend pool.
Break the gap into its components and it stops looking mysterious. Harness-Bench decomposed the 23.8-point aggregate swing into completion score (NanoBot 81.6% vs OpenClaw 60.0%, a 21.6-point gap), process quality (93.8% vs 79.5%, 14.3 points), and tool-use appropriateness (91.7% vs 70.9%, 20.8 points). The worse harness wasn’t running a worse model — it was wasting tool calls, recovering poorly from errors, and completing fewer tasks end to end.
If you only remember one operational takeaway from the same-model-different-harness data, make it this: instrument your harness like production code. Log tool-call appropriateness and recovery rate, not just the final score. The aggregate benchmark number hides exactly the levers you can move fastest.
A benchmark score is a model-harness configuration result. Report it as ‘Opus 4.7 + Claude Code on SWE-bench Verified,’ never as ‘Opus 4.7 scores 87.6%.’ The bare number isn’t reproducible — and in 20Harness-Bench results 2026 and how to act on them
Fix the harness before you upgrade the model
The harness-bench results in 2026 close the loop HAL opened: across realistic multi-step workflows, the configurable harness alone explains a ~24-point band of performance, which should reorder how you spend engineering budget. Put HAL and Harness-Bench together and the practitioner playbook is clear. Before you buy a model upgrade, exhaust your harness first.
Concretely: (1) Pin a known-good baseline harness — Claude Code for coding, NanoBot or a HAL Generalist-style scaffold for general agents — and measure your current scaffold against it on your own tasks. (2) Cap reasoning effort per task type rather than maxing it; HAL and LangChain both found high beats xhigh once timeouts enter. (3) Add a verify/test loop so the agent has a signal to hill-climb. (4) Only after the harness plateaus should a model-generation jump (the +6.8-point class of move) be on the table.
For context on where the model ceiling actually is in mid-2026: SWE-bench Verified leaders now sit near 88-89% (Claude Opus 4.8 at 88.6%, GPT-5.5 at 88.7%), and Claude Opus 4.7 holds 87.6%. The frontier models are bunched within ~2 points of each other on this benchmark. When the models are that close, the harness is no longer the tiebreaker — it is the whole game. If you want to go deeper on which benchmarks even predict production value, read our companion pieces on agentic AI benchmarks for 2026, why SWE-bench doesn’t predict engineering value, and the effective context-length scoreboard.
Builder’s take
I run evals on Cyntr and Loomfeed constantly, and the single most expensive mistake I see teams make is attributing a score to a model when they’re really measuring their scaffold. Here is what the 2026 data actually changed in how I budget engineering time.
- Stop benchmarking models. Benchmark model-plus-harness configurations, and report them as one unit — a bare model number is not falsifiable in production.
- Before you pay for a model upgrade, A/B your harness against a known-good one (Claude Code, NanoBot). A harness swap is usually cheaper than a model migration and the HAL/Harness-Bench data says it often moves the score more.
- Reasoning effort is not free. HAL found higher reasoning effort hurt accuracy in most runs and burned tokens — I cap it per task type rather than maxing it globally, which is exactly what sank LangChain’s xhigh config.
- The scary number is the downside swing. Sonnet 4.5 dropping from 68% to 34% on one benchmark across scaffolds means a bad harness can hide a frontier model’s capability entirely. Instrument the harness, not just the model.
Frequently asked questions
Often, yes. In 2026 controlled data (HAL and Harness-Bench), changing only the harness while holding the model fixed swings benchmark scores 7-34 points — frequently more than the +6.8-point gain of a full model-generation upgrade (Claude Opus 4.5 to 4.7 on SWE-bench Verified). The harness matters most when frontier models are bunched within a couple of points, as they are now.
It is the benchmark result of a model running inside a specific scaffold — the system prompt, tools, context management, verify/retry loop, and reasoning budget. Because the harness determines what the model can observe, modify, recover from, and verify, the score is a property of the model-harness configuration, not the model alone. Always report both.
HAL found Claude Opus 4 swings 7.3 points on GAIA (57.6% to 64.9%) just from the harness, and Claude Sonnet 4.5 fell 34 points (68% to 34%) across scaffolds on one benchmark. Harness-Bench reported a 23.8-point aggregate gap (52.4% to 76.2%) between its worst and best harness on the same model pool.
HAL (Holistic Agent Leaderboard) is a Princeton project published at ICLR 2026 (arXiv 2510.11977). It ran 21,730 agent rollouts across 9 models and 9 benchmarks for about $40,000, using a standardized open-source harness so model, scaffold, and benchmark can be analyzed as separate variables. It is the largest controlled look at the agent scaffold effect to date.
LangChain kept GPT-5.2-Codex fixed and rebuilt only the harness — system prompts, tools, and middleware hooks — moving their Deep Agents coding agent from outside the top 30 to rank 5 on Terminal-Bench 2.0, lifting the score from 52.8% to 66.5% (+13.7 points). They also found a high reasoning budget beat xhigh, which lost time to timeouts.
Improve the harness first. It ships in days instead of weeks, the gains often exceed a model generation, and a better scaffold lifts every model you run through it. Pin a known-good baseline (Claude Code for coding, NanoBot/HAL Generalist for general agents), cap reasoning effort per task, add a verify loop, and only pursue a model jump once the harness plateaus.
Primary sources
- Holistic Agent Leaderboard: The Missing Infrastructure for AI Agent Evaluation (arXiv 2510.11977) — arXiv / Princeton
- HAL: Holistic Agent Leaderboard — Princeton
- Harness-Bench: Measuring Harness Effects across Models in Realistic Agent Workflows (arXiv 2605.27922) — arXiv
- Improving Deep Agents with harness engineering — LangChain
- Agent Benchmark Scores Are Measuring the Harness, Not the Model — Focused Labs
- SWE-Bench 2026: Claude Opus 4.7 Wins 87.6% — TokenMix
- Claude Opus 4.8 Benchmarks Explained — Vellum
- princeton-pli/hal-harness — GitHub
Last updated: June 6, 2026. Related: Observability.




