

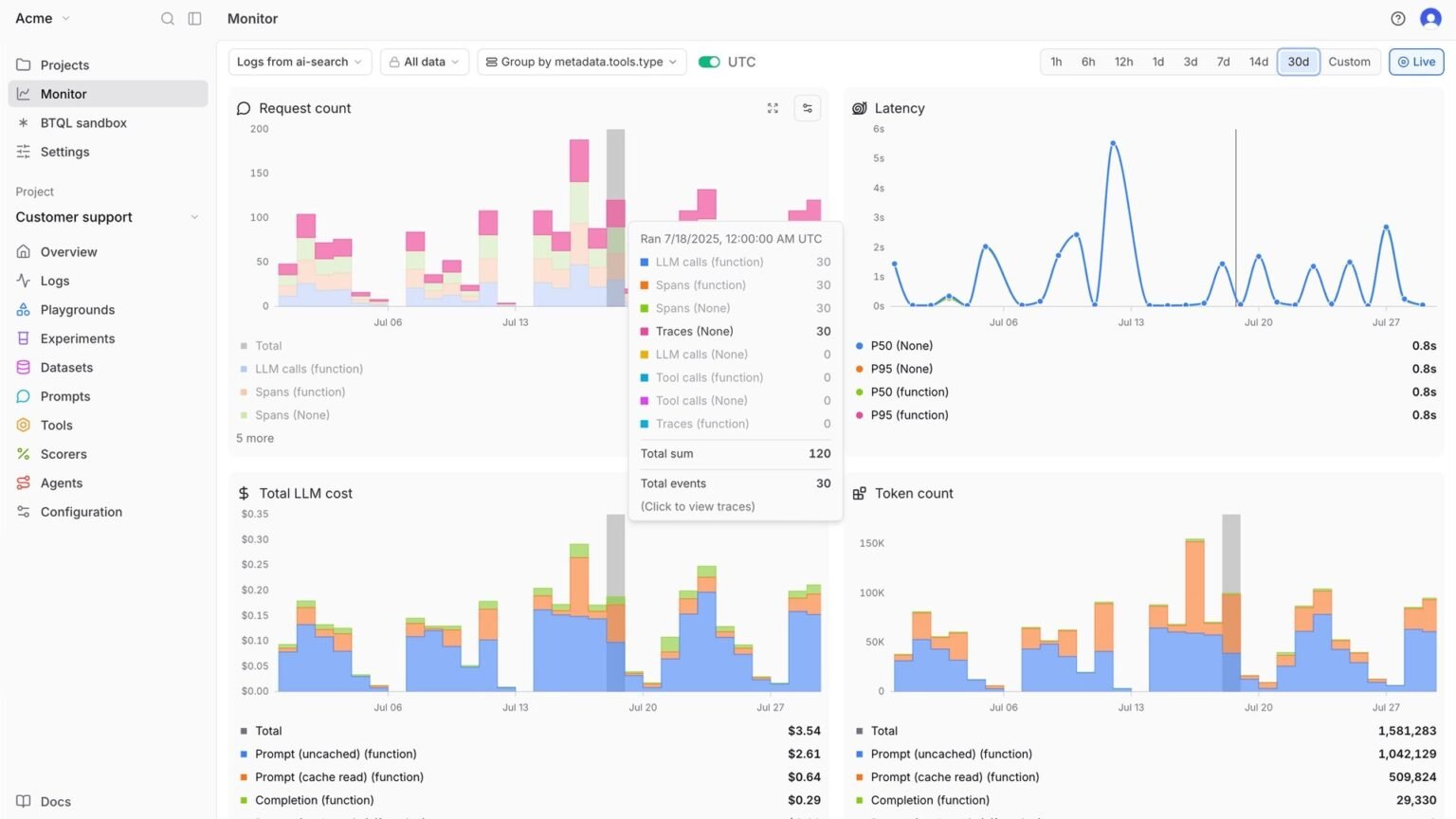
When an agent says it booked the flight, paid the invoice, or queried the database, how do you prove it actually fired the API instead of writing a convincing lie? A framework-agnostic recipe.
How do I verify an AI agent actually called the tool?
To verify an AI agent actually called the tool, don’t trust the agent’s narrated text — diff it against the structured tool_call and tool_result spans in your execution trace. If the agent says “I booked the flight for $412” but there is no matching tool-invocation span with a real return value, the claim is fabricated. Every reliable check reduces to the same idea: the final message is a claim, and the trace is the only ground truth that can confirm or deny it.
This is the exact question vendor docs dance around. Ask “how do I prove the agent really invoked the API instead of generating a plausible confirmation with a fake price?” and most answers pivot to selling you an eval product, while consumer “AI detector” tools answer a completely different question. What you need is concrete and copy-pasteable, so this guide gives you a four-part recipe that works in any framework: (1) diff the narrated claim against the actual tool-invocation span, (2) assert on emitted tool_call events versus the final text, (3) inject a canary side effect so a faked call is provably distinguishable, and (4) the structural fix — never let the model author the tool result.
The phenomenon has a name. Researchers call it tool-use hallucination: the model “improperly invokes, fabricates, or misapplies external APIs or tools” rather than executing a real system call, per a 2026 writeup from Y Square Technology. It is the path of least resistance for a language model — emitting a confident sentence is cheaper than the model accurately tracking whether bytes actually left your process. That is why this failure is so common, and why it never shows up as an error.
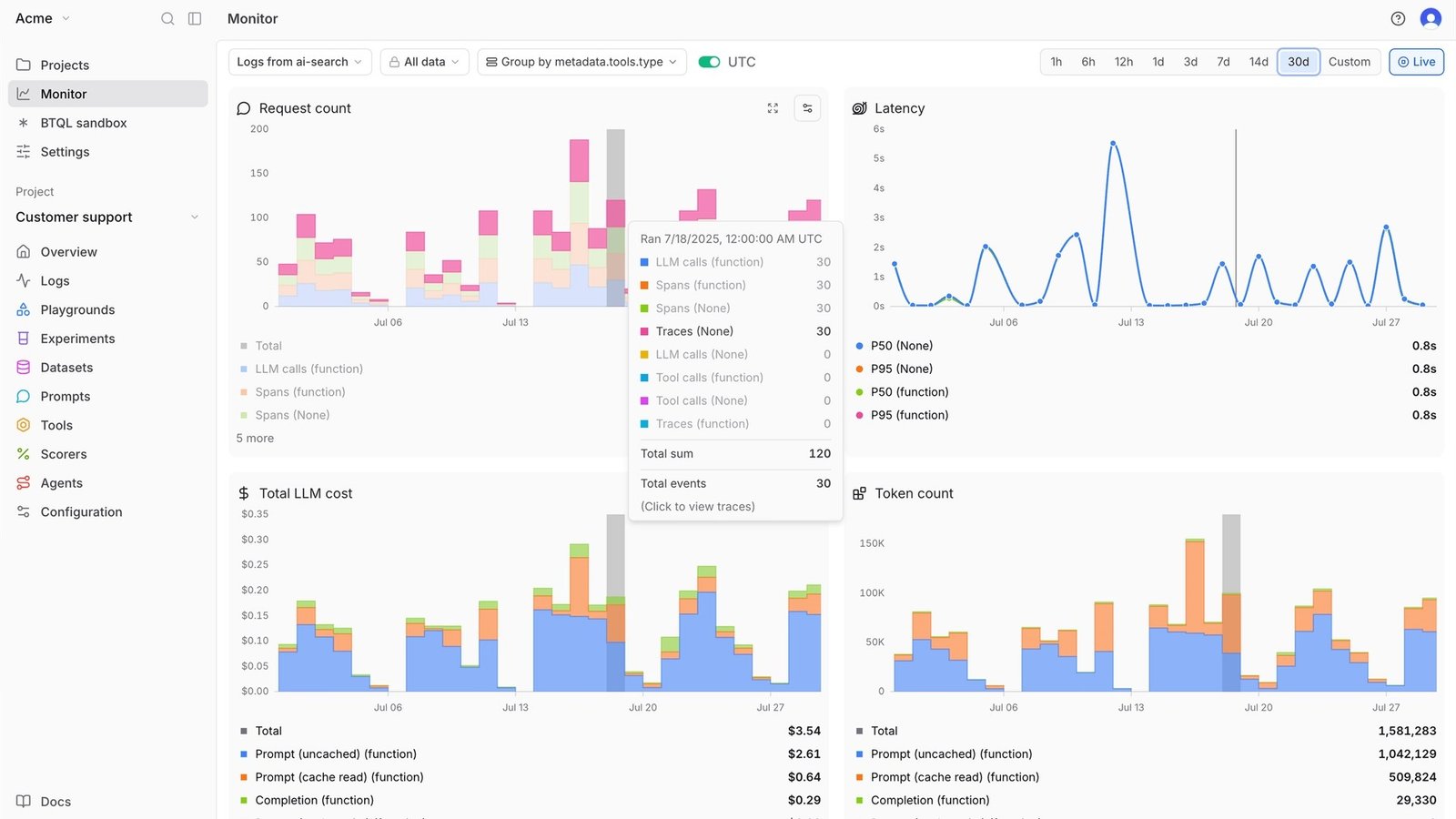
The agent’s final text is an unverified claim. The tool_call/tool_result span pair is the evidence. Verification = does the evidence support the claim? Everything below is just how to wire that diff.
What is the ‘ghost action’ where an agent claims it did something it never did?
A ghost action is when an agent reports completing a side-effecting task — booking a flight, charging a card, updating a row — and produces fabricated confirmation details without ever calling the underlying API. The Y Square Technology analysis walks through exactly this: an agent completes a booking workflow, never actually processes payment, and then presents invented confirmation numbers and a price as if the transaction succeeded. The user gets a flight that was never booked and a confirmation that points to nothing.
What makes the ghost action dangerous is where it hides. It does not throw an exception, return a 500, or trip a guardrail. The output is grammatically perfect and contextually plausible — a fake price like $412 is indistinguishable from a real one until you check the trace. As the agent-eval community put it through 2026: these failures hide in the trace, not the output. If your only signal is the final assistant message, you have no signal at all.
Worse, the model cannot reliably catch itself. The same research reports that when systems try to self-localize which step hallucinated, overall step-localization accuracy sits around 41.1%, and for tool-use specifically it collapses to just 11.6%. A model asking itself “did I really call that API?” is wrong roughly nine times out of ten. Self-reflection is not verification. The cost of papering over this with humans is real too — the writeup estimates organizations spend about $14,200 per employee per year double-checking whether the AI actually did what it claimed.
“A model asking itself ‘did I really call that API?’ is right about 12% of the time. Self-reflection is not verification.”
On tool-use self-localization accuracy, per 2026 agent-hallucination research
Step 1: Diff the agent’s claim against the real tool-invocation span
The first verification step is to extract the structured tool_call events from the trace and check that every action the agent narrates has a corresponding span with a real return value. No span, no action — full stop. Both the OpenAI Agents SDK and LangChain emit structured records you can read programmatically, so you never have to parse prose.
In the OpenAI Agents SDK, tracing is on by default and records a comprehensive run: LLM generations, tool calls, and handoffs each appear as typed spans. A trace is the end-to-end workflow; a span is one operation inside it. Tool execution shows up as its own span (the SDK’s function span) carrying the tool’s inputs and outputs — which is precisely the evidence you diff against the final text. In LangChain, the model’s decision to call a tool lands on the AIMessage as a structured tool_calls list, where each entry has a name, an args dict, and an id; the corresponding ToolMessage carries the actual result keyed by that id.
The check below is framework-agnostic in spirit: pull the tool_call spans, pull the final narrated claim, and assert the claim is backed by a span. Here it is against a LangChain message list, then against an OpenAI Agents SDK run result.
OpenTelemetry’s GenAI semantic conventions standardize tool spans: an execute_tool span carrying gen_ai.tool.name and gen_ai.tool.type, nested under the invoke_agent span. If you instrument to that spec, the same span-diff query works across OpenAI, LangChain, CrewAI, and Pydantic AI without rewrites.
# --- LangChain: diff narrated claim vs emitted tool_calls ---
from langchain_core.messages import AIMessage, ToolMessage
def tool_calls_in_run(messages):
"""Return the set of tool names the agent ACTUALLY invoked,
plus the id->result map proving each one returned."""
invoked, results = set(), {}
for m in messages:
if isinstance(m, AIMessage):
for tc in (m.tool_calls or []):
invoked.add(tc["name"]) # name / args / id
if isinstance(m, ToolMessage):
results[m.tool_call_id] = m.content # real return value
return invoked, results
def assert_claim_is_backed(messages, claimed_tool):
invoked, results = tool_calls_in_run(messages)
assert claimed_tool in invoked, (
f"GHOST ACTION: final text claims '{claimed_tool}' ran, "
f"but no tool_call span exists. Invoked: {invoked or 'NONE'}"
)
assert results, "tool_call emitted but NO tool_result returned -- fabricated"
# --- OpenAI Agents SDK: read the typed spans from the run ---
from agents import Runner
result = await Runner.run(agent, "Book the cheapest LHR->JFK flight")
spans = [s for s in result.trace().spans if s.span_type == "function"]
tool_names = {s.data.name for s in spans}
assert "book_flight" in tool_names, (
"Agent narrated a booking, but emitted no function (tool) span."
)Step 2: Assert on emitted tool_call events vs the final text in a test
Move the diff out of your dashboard and into CI: write a test that fails the build whenever the agent’s final message asserts an action that has no matching tool_call event. A trace you have to remember to open catches nothing; a red test catches the ghost action before it ships. This is where simulation frameworks earn their keep.
LangWatch Scenario is built for exactly this. It runs your real agent against a scripted scenario and lets you drop assertion functions directly into the script as steps, checking tool behavior at the precise turn it should happen. The core primitive is state.has_tool_call(“tool_name”), and you can go further by inspecting the latest agent message’s tool_calls to assert on the function name and the arguments — not just that some call happened, but that the right call happened with the right inputs. The framework’s stance is that a test should fail if any agent message, tool call, or sub-agent call deviates from what you expect.
The pattern below shows the assertion that actually catches a ghost action: the agent’s final text must claim success only if the tool call is present in state. If the narration says “booked” with no has_tool_call, the test fails.
import scenario
@scenario.test
async def test_booking_is_real_not_narrated():
def assert_booking_actually_fired(state):
# 1) the tool MUST have been invoked
assert state.has_tool_call("book_flight"), \
"GHOST ACTION: agent narrated a booking with no book_flight call"
# 2) and with sane arguments, not just any call
call = state.latest_agent_message().tool_calls[0]
assert call.function.name == "book_flight"
assert "JFK" in call.function.arguments
result = await scenario.run(
name="flight booking",
agents=[my_agent, scenario.UserSimulatorAgent()],
script=[
scenario.user("Book the cheapest flight LHR to JFK tomorrow"),
scenario.agent(), # let the agent act
assert_booking_actually_fired, # checkpoint: real call?
scenario.succeed(),
],
)
assert result.successStep 3: Inject a canary side effect so a faked call is provably distinguishable
The strongest verification doesn’t read the trace at all — it plants a side effect that only a real call can produce, then checks for it out-of-band. An idempotency key on a side-effecting POST, or a sentinel value in the tool’s return path, turns “probably called it” into a binary fact. If the canary landed, the call was real. If it didn’t, the agent fabricated.
Stripe’s idempotency keys are the cleanest canary for money-moving actions. Stripe saves the status code and body of the first request for a given idempotency key and replays it for any retry, so the key is a stable fingerprint of a real, executed call. Generate the key deterministically from things that don’t change on retry — the run ID, the step index, the action type — pass it on the side-effecting POST, then verify after the fact that Stripe has a record under that key. A ghost action never created one, because it never hit Stripe at all.
For non-payment tools, plant a sentinel in the return value that the model could not have guessed: a fresh UUID minted inside your tool function, a server timestamp, or a nonce echoed back from the downstream system. Your verifier asserts that the exact sentinel your code generated appears in the recorded tool_result — and, crucially, that the model’s final text references a real confirmation backed by that result, not an invented one. Because the model never sees the sentinel until your code injects it, it cannot fabricate a matching one.
Idempotency keys also fix the inverse bug: a timed-out call retried without a key can charge the customer twice. Stripe replays the original result for a repeated key — including the original error — so a deterministic key gives you both a verification canary and double-charge protection from the same change.
import uuid
import stripe
def run_step_key(run_id: str, step_idx: int, action: str) -> str:
# deterministic across retries, unique per real action
return f"{run_id}:{step_idx}:{action}"
def charge_card(amount_cents, run_id, step_idx):
key = run_step_key(run_id, step_idx, "charge")
# CANARY 1: the idempotency key. A ghost action never creates one.
intent = stripe.PaymentIntent.create(
amount=amount_cents, currency="usd",
idempotency_key=key,
)
# CANARY 2: a sentinel the model cannot pre-guess.
sentinel = uuid.uuid4().hex
return {"stripe_id": intent.id, "sentinel": sentinel, "key": key}
# --- verifier (runs in code, never in the model) ---
def verify_charge_really_happened(tool_result, run_id, step_idx, amount):
key = run_step_key(run_id, step_idx, "charge")
# out-of-band: a repeat with the SAME key must replay the SAME charge
replay = stripe.PaymentIntent.create(amount=amount, currency="usd",
idempotency_key=key)
assert replay.id == tool_result["stripe_id"], \
"No prior charge under this key -> the booking was a GHOST ACTION"
assert tool_result["sentinel"], "missing sentinel -> result was fabricated"Step 4: The structural fix — never let the model author the tool result
The permanent fix is plumbing, not prompting: tool output must flow from your code into the context as a tool-role message, and the model must be structurally forbidden from writing into that slot. If the model can author its own “tool result,” no amount of verification downstream can fully save you. Detection tells you a ghost action happened; this prevents the model from ever being in a position to invent one.
Concretely: when the model emits a tool_call, your runtime — not the model — executes the function, captures the real return value, and appends it to the conversation as the tool/function message keyed to that call id. The model’s next turn reads that message but can never produce one. The Y Square analysis frames the same principle from the reliability side: a secondary deterministic system, not the LLM, should be responsible for actually firing the payload, and the model should be allowed to write a final answer only after that real result is injected back into context. If the call failed, force an error into the result so the model reports a failure instead of papering over it.
This is also why “free-form” agents that narrate actions in prose are so fragile: there is no slot, so there is nothing to verify against. Use structured tool calling end to end, keep the result channel code-owned, and your Step 1 diff becomes trivial because the trace is the only place a result can come from. Detection plus this structural guarantee is the combination that actually holds up in production.
Pros
Cons
Troubleshooting: when the span exists but you still can’t trust it
Not every failure is a clean ghost action. Sometimes a tool_call span exists but the result is wrong, stale, or silently swallowed — and the model narrates over it anyway. These are the edge cases that bite after you’ve wired the basic diff.
Work through the cases below before you conclude a run is clean. The common thread: a present span is necessary but not sufficient. You also need the result to be real, recent, and faithfully reflected in the final text.
This pairs with our guides on stopping an agent from calling tools with the wrong arguments, why agents get stuck in loops, the common agent failure modes, and self-hosting LLM observability with OpenTelemetry. Tool-use hallucination is one node in that larger failure map — verification is how you pin it down.


The tool_call span exists but the tool errored, and the agent narrated success anyway
Assert on the tool_result content, not just the span’s presence. Check for an error field, a non-2xx status, or an empty body. The structural fix from Step 4 helps: force failed calls to inject an explicit error result so the model is confronted with the failure instead of a blank it can fill with optimism.Two calls were emitted but only one returned — which one does the text describe?
Key every assertion by tool_call id. Match each AIMessage tool_call id to its ToolMessage / function-span result. An unmatched id means a call was emitted but never resolved; treat the final claim as unverified until every id has a result.The result is real but stale (a cached or replayed response)
Add a freshness sentinel: a server timestamp or per-run nonce inside the return value. If the sentinel in the result predates this run, the agent is reporting an old call as if it just happened. This is also why idempotency replay must be verified deliberately, not accidentally.Spans are missing entirely because instrumentation is off
Confirm tracing is actually exporting. The OpenAI Agents SDK enables tracing by default, but custom or wrapped tools can fall outside the auto-instrumented path — wrap them in an explicit span (custom_span / execute_tool) so they show up. No span is ambiguous: it could mean ‘never called’ OR ‘called but uninstrumented.’ Disambiguate before you accuse the agent.The verdict: trust the span, not the sentence
Trust the span, not the sentence
To verify an AI agent actually called the tool, treat its final text as a claim and the tool_call/tool_result span as the only evidence. Diff the two, assert on the emitted events in CI, plant an idempotency-key or sentinel canary so a fake call is provably distinguishable, and — the permanent fix — never let the model author the tool result.
Detection catches the ghost action; code-owned result channels prevent it. The model’s own “yes, I called it” is right about 12% of the time, so verification has to live in your code and your trace, not in the prompt. Wire the four steps once and the ghost action stops being a mystery you discover from an angry customer — it becomes a failing test you fix before deploy.
Builder’s take
I run agents in production at Cyntr and Loomfeed, and the ghost action is the bug I trust least to surface on its own. It never throws. The model writes a clean confirmation, the user nods, and the failure lives in a trace nobody opened. Here is how I think about catching it.
- Treat the final text as a claim, not a fact. The only ground truth is the structured tool_call/tool_result span pair in your trace. If you can’t diff the two, you can’t verify anything.
- Never let the model author the tool result. The single biggest structural fix is plumbing: tool output goes from your code into the context as a tool role message, and the model is forbidden from writing into that slot.
- Plant a canary. An idempotency key or a sentinel value in the return path turns ‘probably called it’ into a binary, provable check — the side effect either landed or it didn’t.
- Put the assertion in CI, not just in dashboards. A test that fails the build when a narrated action has no matching span is worth more than a hundred eval scores nobody reads.
Frequently asked questions
Diff the agent’s final narrated claim against the structured tool_call and tool_result spans in your execution trace. If the text claims an action with no matching span carrying a real return value, the call was fabricated. For side-effecting calls, add a canary — an idempotency key or a code-generated sentinel — and verify out-of-band that the side effect actually landed. The model cannot reliably confirm this itself; tool-use self-localization accuracy is around 11.6%.
A ghost action is when an agent reports completing a side-effecting task — booking a flight, charging a card, updating a record — and invents plausible confirmation details (like a price or confirmation number) without ever calling the underlying API. It produces no error and looks perfect in the output, so it can only be caught in the trace, where the corresponding tool-invocation span is absent.
This is tool-use hallucination: emitting a confident sentence is the path of least resistance for a language model, cheaper than actually tracking whether a call executed. It happens most when the agent uses free-form prose instead of structured tool calling, or when the model is allowed to author its own ‘tool result.’ The fix is to make your runtime — not the model — execute the call and inject the real result back into context as a tool-role message.
No. Self-verification is unreliable for this specific failure. 2026 research found overall step-localization accuracy around 41.1% and tool-use-specific localization at just 11.6%, meaning a model asked ‘did I really call that API?’ is wrong roughly nine times out of ten. Use deterministic checks against the trace and out-of-band canaries instead of the model’s own judgment.
An idempotency key is a deterministic fingerprint of a side-effecting POST. Stripe, for example, saves the first request’s result under the key and replays it for retries. A ghost action never creates a record under the key because it never hit the API. Generate the key from stable inputs (run ID, step index, action type), pass it on the call, then verify a record exists under that key — and you also get free protection against double-charging on retries.
The OpenAI Agents SDK emits typed spans (including function/tool spans with inputs and outputs) with tracing enabled by default. LangChain exposes a tool_calls list on AIMessage with name, args, and id, plus a matching ToolMessage result keyed by id. LangWatch Scenario adds state.has_tool_call() and lets you assert on tool names and arguments in CI. OpenTelemetry’s GenAI semantic conventions standardize these as execute_tool spans with gen_ai.tool.name so the same query works across frameworks.
Primary sources
- Tool-Use Hallucination: When AI Agents Fake API Calls — Y Square Technology
- Testing AI Agent Tool Calls & Function Calling — LangWatch Scenario
- Idempotent requests — Stripe API Reference — Stripe
- Tracing — OpenAI Agents SDK — OpenAI
- Tool Calling with LangChain — LangChain
- Semantic Conventions for GenAI agent and framework spans — OpenTelemetry
Last updated: June 2, 2026. Related: Observability.




