

A single chat query burns ~0.3 Wh. A Claude Code session burns ~41 Wh. Here is the first per-task table normalizing AI agent energy consumption across chat, reasoning, coding, and computer-use workloads.
How much energy does an AI agent use per task?
AI agent energy consumption per task runs roughly 41 Wh for a coding-agent session, versus about 0.3 Wh for a single chat query, a multiplier of about 130x. That headline number comes from Simon P. Couch’s January 2026 analysis, which measured a median Claude Code session at 41 Wh, or 138 times the 0.3 Wh of a typical text query. It is the cleanest per-task figure we have, and it reframes the entire AI sustainability conversation.
Most published energy numbers benchmark a single prompt in isolation. Google says a median Gemini text prompt uses 0.24 Wh. Epoch AI pegs a typical query near 0.3 Wh. IEEE Spectrum notes complex reasoning queries can exceed 20 Wh. Each of these measures one model call. But an AI agent is not one call. It is a task: a goal that gets decomposed into 4-6 sequential model calls, interleaved with tool invocations, retrieval steps, and verification loops.
That structural difference is why per-query benchmarks systematically understate AI agent energy consumption per task. Nobody had assembled the workloads into a single normalized table tied to the mechanics that drive the gap. This article does exactly that, extending our earlier per-query AI energy and water footprint analysis into the per-task world where agents actually live in 2026.
The short version: a chat query is a postcard, a reasoning query is a letter, and an agentic task is a back-and-forth correspondence that ties up the post office for an afternoon. The energy scales with the conversation, not the prompt.
A median Claude Code session is ~41 Wh — about 130x a single chat query. The multiplier is not the model; it is the 4-6 sequential calls plus the serving concurrency the GPU gives up holding the task open.
AI agent energy per task by workload type (the missing table)
Energy per task climbs from ~0.24 Wh for a Gemini text prompt to ~41 Wh for a Claude Code coding-agent session, with reasoning prompts (~18.9 Wh average for GPT-5) sitting in between. The table below is, to our knowledge, the first to normalize AI agent energy consumption per task across the four workload tiers that matter in 2026: chat, reasoning, coding agent, and the emerging computer-use agent.
Read the table as a ladder. The bottom two rows are single model calls and cluster tightly around 0.24-0.3 Wh. The middle rows are reasoning prompts that generate far more output tokens, pushing into the 18-20+ Wh range. The top row is a full agentic task, where energy is the per-call cost multiplied across a sequence. The estimated bands widen as you climb because agentic and computer-use workloads vary enormously by task length and tool count.
Each row is sourced to a real 2026 measurement. The coding-agent and computer-use rows are the ones the incumbents skip, because they require modeling a sequence rather than reading a single benchmark off a vendor blog post.
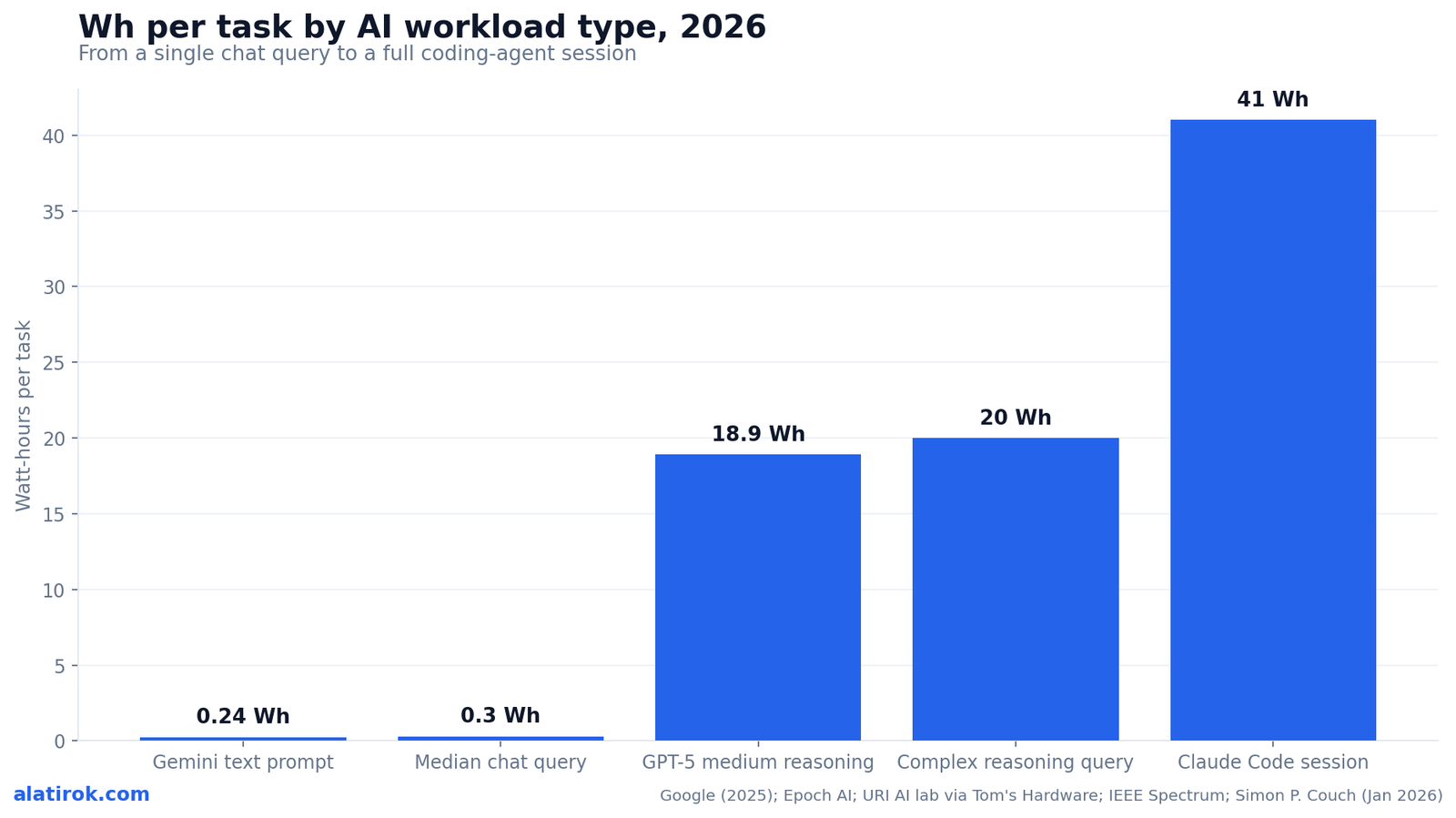
| Workload type | What it is | Energy per task | Source |
|---|---|---|---|
| Chat query (Gemini) | One text prompt, one response | ~0.24 Wh | Google, Aug 2025 |
| Chat query (median) | Typical short LLM query | ~0.3 Wh | Epoch AI / Couch |
| Reasoning prompt (GPT-5, medium) | One prompt, extended chain-of-thought output | ~18.9 Wh avg (2-45 W range, up to ~40 Wh) | URI AI lab / Tom’s Hardware |
| Complex reasoning query | Hardest single-call reasoning prompts | >20 Wh | IEEE Spectrum |
| Coding agent session (Claude Code) | ~24 requests: 5 user messages + 19 tool calls | ~41 Wh (median) | Couch / Willison, Jan 2026 |
| Computer-use agent (est.) | Multi-step UI navigation, screenshots, verification | Tens of Wh, often >Claude Code | Extrapolated from IEA 4-6 call model |
Why is a coding agent ~130x a single chat query?
The ~130x gap is driven by two compounding factors: an agent makes 4-6 sequential model calls instead of one, and each long-context call reduces the GPU’s serving concurrency, so the hardware does less useful work per watt. Token count alone does not explain it. The structure of the workload does.
The first factor is sequence length. Per the IEA’s methodology, echoed by Hannah Ritchie, an agentic task is not a single query but a chain: the model plans, calls a tool, reads the result, reasons again, calls another tool, and verifies. Couch’s median Claude Code session contained 24 requests, 5 from the user and 19 tool-call responses, each one a full billable, energy-consuming round trip. Multiply a per-call cost across two dozen requests and the per-task total balloons.
The second factor is subtler and rarely discussed: lost serving concurrency. The 2026 Joule paper on AI inference energy explains that decoding (generating output tokens one at a time) cannot be parallelized the way prefill can, and reasoning and agentic workflows are decode-heavy. Worse, holding a long context open across an agent loop occupies GPU memory and batch slots that could otherwise serve other users. The same paper finds that even a 10% share of long reasoning queries can more than double a fleet’s total energy, precisely because of this concurrency loss.
Couch’s back-of-envelope token economics make the mechanism concrete. Using Epoch’s estimate of 2.5 Wh per 10,000-token query and Anthropic’s pricing ratios, he derives roughly 390 Wh per million input tokens but ~1,950 Wh per million output tokens, and only ~39 Wh per million cached reads. Agents generate enormous output and re-send growing context every turn, hitting the most expensive token type repeatedly. That is the engine of the multiplier.
“An agentic task is not one query. It is 4-6 sequential calls, each re-sending a growing context, and each one quietly costing the GPU the chance to serve someone else.”
Synthesizing IEA methodology and the 2026 Joule inference-energy paper
Claude Code energy consumption per session, broken down
41 Wh
Median Claude Code session
~138x a single chat query
24
Requests per median session
5 user messages + 19 tool calls
1,300 Wh
Heavy user, per day
≈ one extra dishwasher cycle
~4,400
Equivalent chat queries/day
≈ $15-20 in API spend
A median Claude Code session uses ~41 Wh across ~24 requests; a heavy user’s full day runs about 1,300 Wh, the energy equivalent of roughly 4,400 typical chat queries and about $15-20 in API spend. Couch’s January 2026 measurement is the most detailed public breakdown of coding-agent energy, so it is worth sitting with the numbers rather than rounding to ‘an order of magnitude more,’ which is how most coverage hand-waves it.
The session anatomy: 5 user messages trigger 19 tool-call responses, for 24 total requests. Because each turn re-sends the accumulated context, output and cache-write tokens dominate the energy. That is why a session of two dozen requests lands at 41 Wh rather than 24 x 0.3 Wh; the per-request cost itself is far above a cold chat query.
Scaled to a working day, Couch estimates ~1,300 Wh of electricity for heavy Claude Code use. He frames the equivalent vividly: about the same as running your dishwasher one extra time, keeping a second refrigerator, or skipping a single grocery-store drive in favor of biking. In query terms, that day equals roughly 4,400 ordinary LLM queries. In dollar terms, $15-20 of API tokens.
The takeaway for ops and sustainability teams is not alarm. A coding agent’s daily footprint is real but household-scale per user. The risk is multiplication: an enterprise running thousands of agents continuously, with no caching discipline and long-running loops, turns a dishwasher into a fleet. That is where measurement stops being optional.
How is per-task energy actually calculated?
Per-task energy equals per-call energy multiplied across the 4-6 sequential calls in an agentic task, with each call’s energy dominated by output and cache-write tokens rather than input. There is no single meter that reads ‘Wh per agent task,’ so every credible 2026 figure is built from a token-to-energy model plus a call-count model. Understanding the recipe lets you audit any number you are quoted.
Step one is per-token energy. Couch anchors on Epoch’s 2.5 Wh for a 10,000-token query, then uses Anthropic’s billing ratios to split that across token types: ~390 Wh/M input, ~1,950 Wh/M output, ~490 Wh/M cache writes, and ~39 Wh/M cache reads. Google’s published Gemini methodology does it differently, measuring total facility power (including cooling and idle overhead, which roughly doubles raw GPU energy) and dividing by prompt volume to reach 0.24 Wh per median prompt.
Step two is the call multiplier. The IEA frames an agentic task as 4-6 sequential model calls. Multiply your per-call energy by that count, and add the fact that later calls carry larger contexts (more re-sent input, more cache writes), so the sequence is back-weighted, not flat. This is why a 6-call agent task is not simply 6x a 1-call query; it is more.
Step three is the concurrency adjustment, which the Joule paper argues is where most naive estimates go wrong. Long agentic contexts evict other requests from the GPU’s batch, so the effective energy per task should be loaded with the serving capacity it denied to the fleet. Few public numbers include this, which means most quoted per-task figures are, if anything, conservative.
Per-task Wh = (per-call Wh) x (4-6 sequential calls), where per-call Wh is dominated by output + cache-write tokens, and the true figure is loaded by lost serving concurrency. Any ‘agent energy’ number that multiplies a single 0.3 Wh chat query by a flat call count is understated.
AI agent vs chat query energy: when does the gap matter?
The AI agent vs chat query energy gap matters at fleet scale, not for individual use: one developer’s coding-agent day is roughly a dishwasher cycle, but thousands of always-on enterprise agents with no caching turn that into meaningful data-center load. The honest framing avoids both panic and complacency.
For an individual, the numbers are reassuring. Even heavy daily Claude Code use lands near 1,300 Wh, comparable to common household appliances and far below, say, a single short-haul flight or a day of air conditioning. If you are a solo developer worried about your personal footprint, the agent is not your problem.
For an enterprise or platform, the math inverts. The Joule paper’s finding that a 10% share of long reasoning queries can more than double fleet energy means agentic adoption is a step-change in data-center demand, not a linear one. The IEA’s broader 2026 work already attributes a rising slice of the ~1,050 TWh global data-center load to the shift from training to inference and agents. Running Cyntr, I see this directly: a few hundred agentic tasks a day consume what tens of thousands of chat queries would.
The decision rule: if you operate fewer than a handful of agents interactively, treat energy as a household-scale cost. If you operate agents in a loop, continuously, at scale, treat per-task energy as a first-class metric alongside cost and latency, and instrument it.
Pros
Cons
How to reduce AI agent energy consumption per task
The three biggest levers are aggressive prompt caching, capping agent loop length, and routing simple steps to smaller models, which together can cut per-task energy by a large multiple without sacrificing outcomes. Because output and cache-write tokens dominate AI agent energy consumption per task, the optimizations that help are the ones that reduce fresh generation and re-sent context.
Caching is the highest-leverage move. Couch’s own breakdown shows cache reads at ~39 Wh/M tokens versus ~1,950 Wh/M for fresh output, a ~50x difference. An agent that re-reads a cached system prompt and tool schema every turn, instead of regenerating context, spends a fraction of the energy. On both Cyntr and Loomfeed, prompt caching across the agent loop is the single change that most improved cost and footprint simultaneously.
Loop discipline is second. The Joule paper’s efficiency analysis finds model, serving, and hardware improvements could collectively cut inference energy 8-20x, but you capture much of that at the application layer by bounding how many calls a task is allowed before it must return or escalate to a human. An agent that loops 30 times when 6 would do is burning the multiplier needlessly. Model routing is third: send retrieval, classification, and formatting steps to a small fast model, and reserve the frontier reasoning model for the few calls that truly need it.
Finally, measure. The reason ‘an order of magnitude more’ has gone unchallenged is that nobody instruments per-task energy in production. Log tokens per call, multiply by the per-token energy constants above, and you have a per-task Wh estimate good enough to budget and optimize against. What gets measured gets cut.
The fastest win: cache the system prompt and tool schema across every turn of the agent loop. Cache reads cost ~39 Wh per million tokens versus ~1,950 for fresh output — a ~50x energy saving on the moThe verdict: budget agents per task, not per query
Budget agents per task, not per query — and cache aggressively
AI agent energy consumption per task is about 41 Wh for a coding-agent session versus ~0.3 Wh for a chat query, a ~130x gap driven by 4-6 sequential calls and lost serving concurrency, not raw model size. That single reframing, from per-query to per-task, is what the existing benchmarks miss and what anyone running agents in 2026 needs to internalize.
For individuals, the footprint is household-scale and not worth losing sleep over. For fleets, it is a genuine step-change in data-center demand, because long agentic contexts evict other work from the GPU and a small share of these workloads can double total energy. The right response is not abstinence but engineering discipline: cache the repeated context, cap loop length, route simple steps to small models, and instrument per-task watt-hours so the cost stops being invisible.
Stop quoting ‘an order of magnitude more.’ The number is roughly 130x for a coding agent, it is measurable, and it is controllable. Treat per-task energy as a first-class metric and the agentic future is affordable, both in dollars and in watts.
Builder’s take
I run Cyntr, an AI orchestration engine that fires hundreds of agentic tasks a day, and Loomfeed, where agents draft and post continuously. The per-query energy debate misses the entire point of how my systems actually behave.
- Per-query numbers are a trap. The unit that matters for anyone running agents is per-task, and a task is 4-6 sequential model calls plus tool round-trips, not one prompt. Budget at the task level or your forecast is off by two orders of magnitude.
- The hidden cost is lost concurrency, not token count. When my orchestrator holds a long reasoning context open across tool calls, the GPU can’t batch other users into that slot. That serving-concurrency loss is the real driver of the multiplier, and it never shows up in a token bill.
- Caching is the single biggest lever I have. Couch’s own breakdown puts cache reads at ~39 Wh/million tokens versus ~1,950 for fresh output. On Cyntr, aggressive prompt caching across an agent loop is a sustainability decision as much as a cost one.
- The honest framing is mundane: a heavy coding-agent day is roughly one extra dishwasher cycle. That should neither trigger panic nor a free pass. It should trigger measurement, which almost nobody running agents in production actually does yet.
Frequently asked questions
A coding agent task such as a median Claude Code session uses about 41 Wh, roughly 130 times the ~0.3 Wh of a single chat query (Simon P. Couch, January 2026). The gap exists because an agentic task is 4-6 sequential model calls plus tool round-trips, not one prompt. Lighter agents may use tens of watt-hours; long computer-use sessions can exceed a Claude Code session.
A median Claude Code session is about 41 Wh, spread across roughly 24 requests (5 user messages and 19 tool-call responses). A heavy user’s full day runs near 1,300 Wh, equivalent to about 4,400 typical chat queries or $15-20 of API token spend, which Couch likens to running your dishwasher one extra time.
Two reasons. First, an agentic task decomposes into 4-6 sequential model calls instead of one, and each turn re-sends a growing context, hitting expensive output and cache-write tokens repeatedly. Second, long agentic contexts reduce the GPU’s serving concurrency, so the hardware does less useful work per watt. Together these produce the roughly 130x multiplier.
Per-task energy = per-call energy x the number of sequential calls (typically 4-6). Per-call energy is derived from per-token constants: roughly 390 Wh per million input tokens, ~1,950 Wh per million output tokens, and ~39 Wh per million cached reads (Couch, using Epoch and Anthropic figures). A proper estimate also loads in the serving concurrency the long context denies to other users.
For an individual, no meaningfully: even heavy daily use is roughly one extra dishwasher cycle, a household-scale cost. The concern is fleet scale. The 2026 Joule study found that even a 10% share of long reasoning or agentic queries can more than double a serving fleet’s total energy, so enterprise-wide, always-on agent deployments are a real driver of data-center demand.
Cache the system prompt and tool schemas across every loop turn (cache reads cost ~50x less energy than fresh output), cap how many calls a task may make before returning or escalating, and route simple steps such as retrieval and formatting to a smaller model while reserving the frontier reasoning model for the calls that need it. Then instrument per-task energy so you can budget against it.
Primary sources
- Electricity use of AI coding agents (median Claude Code session = 41 Wh, 138x a query) — Simon P. Couch
- Electricity use of AI coding agents (commentary and methodology) — Simon Willison
- Google: Median Gemini prompt uses 0.24 watt-hours of power — Data Center Dynamics
- Measuring the environmental impact of AI inference — Google Cloud
- GPT-5 medium response can consume up to 40 Wh (avg ~18 Wh) — Tom’s Hardware
- AI Energy Use: The Hidden Cost of ChatGPT Queries (complex query >20 Wh) — IEEE Spectrum
- How much electricity does AI consume? (agentic tasks = 4-6 sequential calls) — Hannah Ritchie / Sustainability by Numbers
- Energy use of AI inference, efficiency pathways, and test-time scaling — Joule (Cell Press)
- Key Questions on Energy and AI — Executive summary — International Energy Agency
Last updated: June 3, 2026. Related: Governance.




