

The discipline that replaced prompt engineering in 2026 — and the concrete techniques, APIs, and stack that take agents from 31% to 99% accuracy.
What is context engineering, and why did it replace prompt engineering?
Context engineering is the discipline of designing what information a model receives, how it is structured, and when it enters the context window — spanning retrieval, memory, tools, and state. Prompt engineering optimizes the question; context engineering optimizes the conditions under which the question is answered. In 2026 the second one is the job, because a well-crafted prompt inside a poorly engineered context still fails, while a mediocre prompt inside a well-engineered context usually succeeds.
The shift is not hype-cycle theater — it is what production demanded. A single chat prompt is static text you write once. An agent runs for dozens of turns, calls tools, accumulates results, and has to remember what it did three steps ago. None of that is solved by a cleverer instruction. It is solved by governing the tokens that surround the instruction, which is exactly what context engineering formalizes.
Industry surveys back the pivot. Reporting aggregated across 2026 vendor analyses found that 82% of IT and data leaders now say prompt engineering alone is insufficient for production AI, and roughly 95% of data teams plan to invest in context-engineering capability this year. Treat those as directional vendor figures, not peer-reviewed numbers — but the direction is unambiguous.
If you want the substrate this builds on, see our companion guides on whether the 1-million-token context window actually works and how to wire retrieval-augmented generation — context engineering is the layer that decides what to put into those windows in the first place.
How much does context engineering actually move agent accuracy?
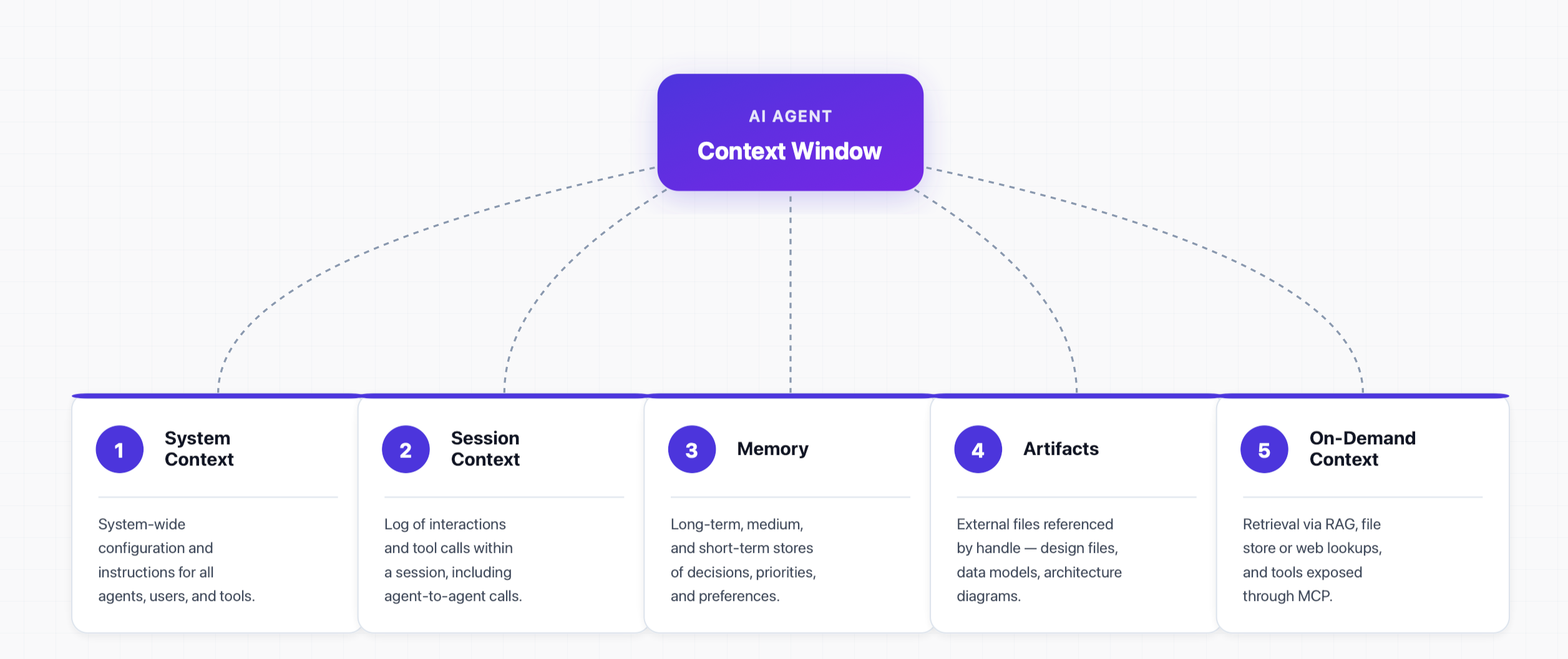
94-99%
Agent accuracy with governed context
vs 10-31% on bare schemas (vendor evals — Moveworks, Promethium)
65%
2025 enterprise AI failures from context drift
memory loss in multi-step reasoning, not context exhaustion
39%
Performance lift: context editing + memory
Anthropic internal agent evaluation
84%
Token reduction on a 100-turn web search
with tool-result clearing (Anthropic eval)
Governed, well-engineered context has been reported to lift agent accuracy into the 94-99% range on structured tasks, versus roughly 10-31% when the same agent runs against bare schemas with no curated context. Those figures come from vendor evaluations (Moveworks and Promethium are cited across 2026 write-ups), so caveat them as marketing-adjacent — but the gap is too large to dismiss, and it matches the failure data.
The failure data is the more sober story. Roughly 65% of enterprise AI failures in 2025 were attributed to context drift or memory loss during multi-step reasoning, not to raw context exhaustion and not to model capability. In other words, agents usually do not break because the model is dumb; they break because the wrong tokens were present, the right tokens were missing, or the relevant tokens decayed mid-task.
Anthropic’s own evaluations give cleaner, first-party numbers for specific techniques rather than end-to-end accuracy. Context editing plus a memory tool delivered a 39% performance lift in their internal agent eval; context editing alone gave 29%; and on a 100-turn web-search task, token-clearing cut consumption by 84%. Different metric, same conclusion: the management layer is load-bearing.
The four levers of context engineering: write, select, compress, isolate
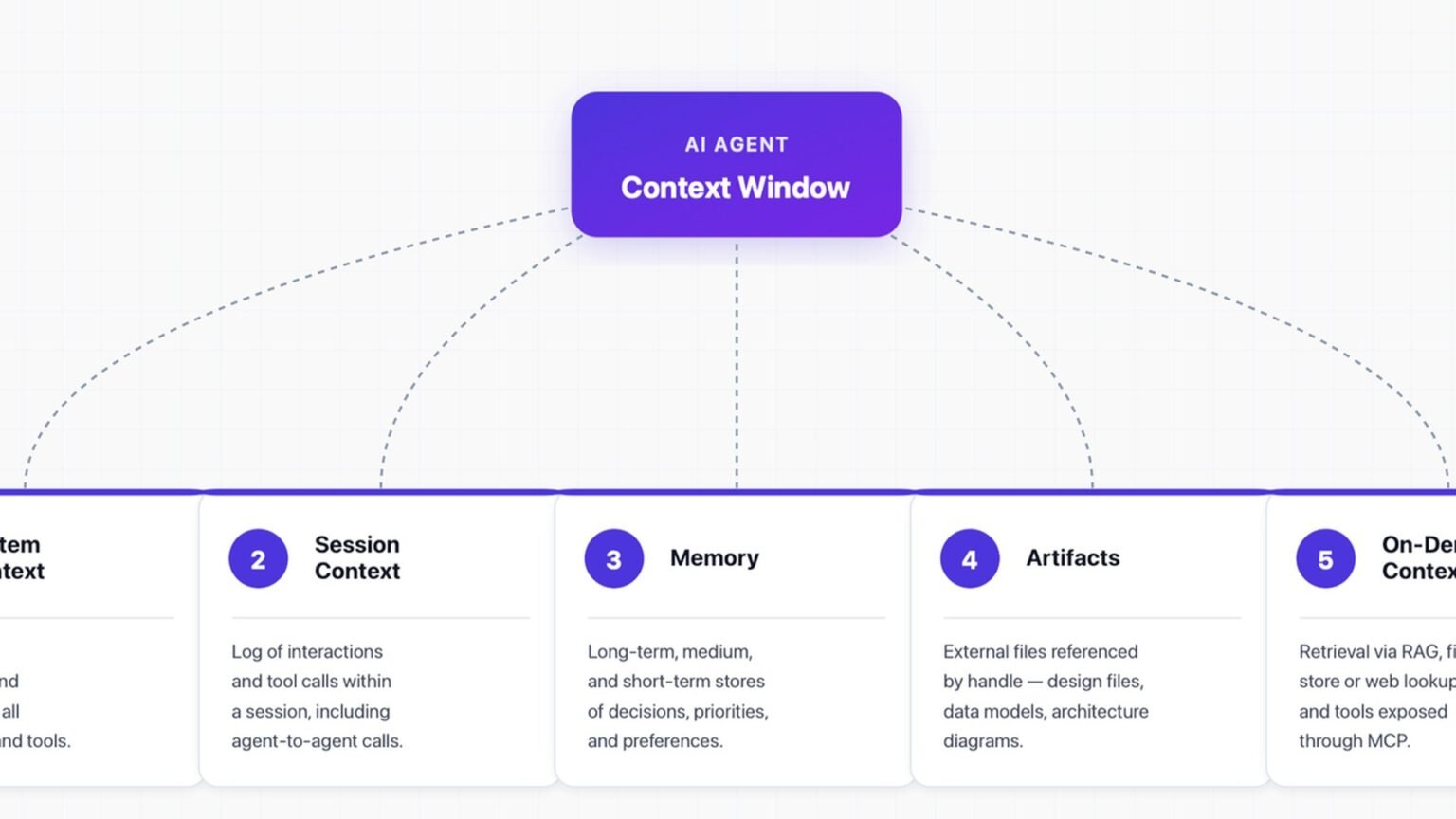
The 2026 consensus organizes context engineering into four levers — write (store context externally), select (load just-in-time), compress (summarize or clear), and isolate (partition work to subagents). Every concrete technique you will deploy is an instance of one of these four, and a mature agent uses all four at once.
Write means persisting state outside the window — memory files, scratchpads, structured notes — so the agent does not have to hold everything in active tokens. Select means pulling only the relevant slice in at the moment it is needed, which is where RAG and semantic search live; counterintuitively, fewer well-chosen tools and documents beat a kitchen-sink load. Compress means summarizing old conversation or clearing stale tool results before the window saturates. Isolate means handing a bounded subtask to a subagent that does its own messy work and returns a tight 1k-2k token summary to the lead agent.
The isolate lever is why multi-agent patterns took off. Anthropic’s research system reported a 90.2% uplift from a multi-agent architecture over a single agent on certain research tasks — largely because each subagent gets a clean, purpose-built window instead of one shared context that turns into sludge.
Write — externalize state
Persist durable facts to memory files or a structured store after each turn. The key discipline is write-before-compaction: extract what matters as you go, so nothing important depends on surviving a lossy summary later.Select — just-in-time loading
Retrieve only the documents and expose only the tools relevant to the current step. Over-selection causes ‘context confusion,’ where superfluous tools make the model call the wrong one.Compress — summarize and clear
Two distinct moves: compaction (summarize the conversation, lossy, costs inference) and tool-result clearing (drop re-fetchable outputs, mechanical, no inference cost). Trigger before saturation, not at it.Isolate — partition to subagents
Route a bounded subtask to a subagent with its own window; return only a compact summary to the lead. Use 1 agent for simple queries, 2-4 for comparative research, 10+ for complex long-horizon work.Context engineering technique: memory tiers and compaction in code
The production memory pattern is three tiers: in-context working memory (lossless, this session), compressed session memory (anchored summaries), and an external persistent store for cross-session knowledge — with extraction happening before compression, not during it. Anthropic ships first-party primitives for all three, and the code below shows how they wire together.
The single most important rule is the write-before-compaction pattern. Extract durable facts after every turn into the memory tier. If you wait until the window is full and then summarize, the summary is lossy by definition — exact numbers, table cells, and one-off identifiers are precisely what gets dropped. Anthropic’s docs are explicit that compaction preserves high-level facts and sheds obscure specifics, so anything you will need verbatim must be written out first.
Note the two compression mechanisms are not interchangeable. Compaction (beta header compact-2026-01-12) runs the model to summarize and costs inference; tool-result clearing (clear_tool_uses_20250919) is a mechanical edit with no inference cost but it does invalidate your cached prefix. Use clearing for large re-fetchable payloads like file reads and API dumps; use compaction for accumulated reasoning you cannot simply re-fetch.
Trigger compaction at roughly 70-95% of your window budget, never at 100%. Anthropic’s compaction minimum is 50K tokens (default 150K); Claude Code’s product auto-compact fires near 95%. Leave generous output headroom — on a 200K window, plan for system prompt ~3K, RAG-selected tools ~5K, retrieved docs ~20K, history ~12K, and keep the rest free.
import anthropic
client = anthropic.Anthropic()
resp = client.beta.messages.create(
model="claude-sonnet-4-5",
max_tokens=4096,
betas=["context-management-2025-06-27", "compact-2026-01-12"],
tools=[
{"type": "memory_20250818", "name": "memory"}, # tier 3: persistent
# ...your domain tools...
],
context_management={
"edits": [
# COMPRESS: clear large, re-fetchable tool results (no inference cost)
{
"type": "clear_tool_uses_20250919",
"trigger": {"type": "input_tokens", "value": 30_000},
"keep": {"type": "tool_uses", "value": 4}, # keep last 4 results
"clear_at_least": {"type": "input_tokens", "value": 10_000},
"exclude_tools": ["memory"], # never clear memory writes
},
# COMPRESS: compact accumulated reasoning before saturation (lossy)
{
"type": "compact_20260112",
"trigger": {"type": "input_tokens", "value": 150_000},
"instructions": (
"Preserve every quantitative figure with its source. "
"Note which documents have been read. "
"Wrap the summary in <summary></summary>."
),
},
]
},
messages=[{"role": "user", "content": "Research and compare the three options."}],
)Why position matters: lost in the middle and tool-result shaping
Lead with the most relevant content, because models recall information at the start and end of a long context far better than information buried in the middle — the ‘lost in the middle’ effect. Liu et al. measured a 30%-plus accuracy drop on multi-document QA when the answer document moved from position 1 to position 10 in a 20-document context, producing a U-shaped recall curve: strong at the edges, weak in the middle.
The cause is architectural, not cognitive, but it rhymes with the human serial-position effect (primacy and recency). The practical takeaway is blunt: do not dump retrieved chunks in arbitrary order and hope. Rank by relevance, put the strongest evidence first and a tight restatement of the task last, and keep the working set small. Newer long-context models like Gemini 2.5 Flash have largely beaten simple needle-in-a-haystack retrieval regardless of position — but multi-document reasoning under load still degrades, so do not assume the problem is retired.
Tool-result shaping is the same principle applied to tool outputs. A raw API response or file read can be 90%-plus of your token spend — in Anthropic’s research-agent example, file reads were 96.3% of a 335K-token peak. Shape before you insert: strip boilerplate, extract the fields the agent actually needs, and cap result size. Rewriting tool definitions and outputs alone cut task-completion time 40% in Anthropic’s tool-testing agent, which is a larger swing than most prompt edits ever produce.
“An agent does not fail because the model is dumb. It fails because the wrong tokens were present, the right tokens were missing, or the relevant tokens decayed mid-task.”
The operating thesis of context engineering
The typical 2026 context engineering stack
A typical 2026 context engineering stack is three to five components: a governance/metadata platform, a knowledge graph of assets and relationships, an eval framework, MCP servers for tool access, and the provider-native context-management APIs. The point of the stack is to make context governed by default — fast, formatted, and correct, rather than fast, formatted, and wrong.
Governance is the layer most teams skip and most regret. RAG over governed, certified data has been reported at 85-92% retrieval accuracy; pointed at ungoverned sources it falls to 45-60%. A metadata catalog (Atlan is the commonly named example) plus a knowledge graph give the agent certified assets, business-glossary terms, lineage, and access controls — so it retrieves the right table, not a stale duplicate, and never surfaces PII it should not see.
The eval layer is the least mature. Fewer than one in three teams report being satisfied with their observability and evaluation tooling. The 2026 landscape has split into commercial platforms (LangSmith, Braintrust, Helicone, Phoenix by Arize, Promptfoo) and open-source standards (DeepEval, Inspect AI, OpenAI Evals); the converging pattern is OSS for fast PR-level checks and a commercial tool for production trace annotation and audit. MCP, meanwhile, became the connective tissue — over 10,000 public MCP servers were deployed by late 2025, which is why ‘select the right tools’ is now a real engineering problem rather than a footnote.
| Layer | Example tooling | Lever it serves | Failure it prevents |
|---|---|---|---|
| Governance / metadata catalog | Atlan, certified assets, lineage | Select | Stale lineage, hallucinated metrics, PII exposure |
| Knowledge graph | Asset relationships and definitions | Select | Wrong table, broken joins, context confusion |
| Retrieval (RAG) | Vector + semantic search, JIT loading | Select | Irrelevant or buried context (lost in the middle) |
| Context-management API | Compaction, tool clearing, memory tool | Compress / Write | Context rot, window saturation, memory loss |
| MCP servers | 10k+ public servers (late 2025) | Select | Brittle bespoke integrations |
| Eval / observability | LangSmith, Braintrust, DeepEval, Phoenix | All four | Silent regressions, undetected drift |
Builder’s take
I build Cyntr, an agent orchestration runtime, and the single biggest reliability lever we have is not the model — it is what we put in front of the model and when. Once you operate agents at scale, you stop tuning sentences and start tuning the context window as a budget.
- Treat the window as a budget, not a bucket. Every token competes; allocate slots for system prompt, tools, retrieval, and history, and defend headroom for output.
- Write before you compact. Extract durable facts to external memory after each turn, not at compression time — otherwise the summary eats the detail you needed.
- Fewer tools beats more tools. We saw the same thing the labs report: pruning and rewriting tool definitions moved accuracy more than any prompt rewrite.
- Lead with the most relevant content. Position matters; bury the answer in the middle of a long context and the agent will miss it even when it is right there.
Frequently asked questions
Context engineering is the practice of deciding what information an AI model sees, how that information is structured, and when it enters the context window. For agents, that includes retrieval, memory, tool results, and state — everything surrounding the prompt, rather than the wording of the prompt itself.
Prompt engineering optimizes the question you ask; context engineering optimizes the conditions under which the question is answered. Prompt engineering is largely static text written once. Context engineering is a runtime discipline that governs a multi-turn agent’s window — memory, retrieval, tools, and compression — as the agent works.
Vendor evaluations report governed context lifting agent accuracy into the 94-99% range on structured tasks versus 10-31% on bare schemas, and Anthropic’s first-party evals show 29-39% lifts from context editing and memory. Treat the headline accuracy numbers as directional vendor figures, but the gap is consistent with data showing ~65% of 2025 enterprise AI failures stemmed from context drift.
Lost in the middle is the finding that LLMs recall information placed at the start or end of a long context far better than information in the middle, producing a U-shaped recall curve. Liu et al. measured a 30%-plus accuracy drop when the answer moved from position 1 to position 10 of 20 documents. The fix is to rank by relevance and lead with the most important content.
Trigger compression before the window saturates — a common rule is 70-95% of your token budget, never 100%. Use tool-result clearing for large, re-fetchable payloads like file reads (mechanical, no inference cost), and use compaction for accumulated reasoning you cannot re-fetch (lossy, costs inference). Always write durable facts to memory before compacting.
Usually three to five components: a governance/metadata platform (e.g., Atlan), a knowledge graph of assets and relationships, a RAG/retrieval layer, the provider’s context-management API (compaction, clearing, memory), MCP servers for tool access, and an eval/observability framework such as LangSmith, Braintrust, or DeepEval.
Primary sources
- Context engineering: memory, compaction, and tool clearing — Anthropic Claude Cookbook
- Context Engineering: Agent Reliability Playbook 2026 — Digital Applied
- Lost in the Middle: How Language Models Use Long Contexts — Liu et al. (arXiv 2307.03172)
- Context Infrastructure for AI Agents: The Complete Guide — Atlan
- Agent eval frameworks: DeepEval, Braintrust, LangSmith, Patronus 2026 — AgentMode AI
Last updated: May 31, 2026. Related: Agent Infrastructure.




