

A vendor-neutral decision matrix for running untrusted LLM code: cold-start cost per loop turn, isolation grade, GPU-in-sandbox, and per-vCPU-hour numbers most vendor posts bury.
What is the best AI agent sandbox 2026?
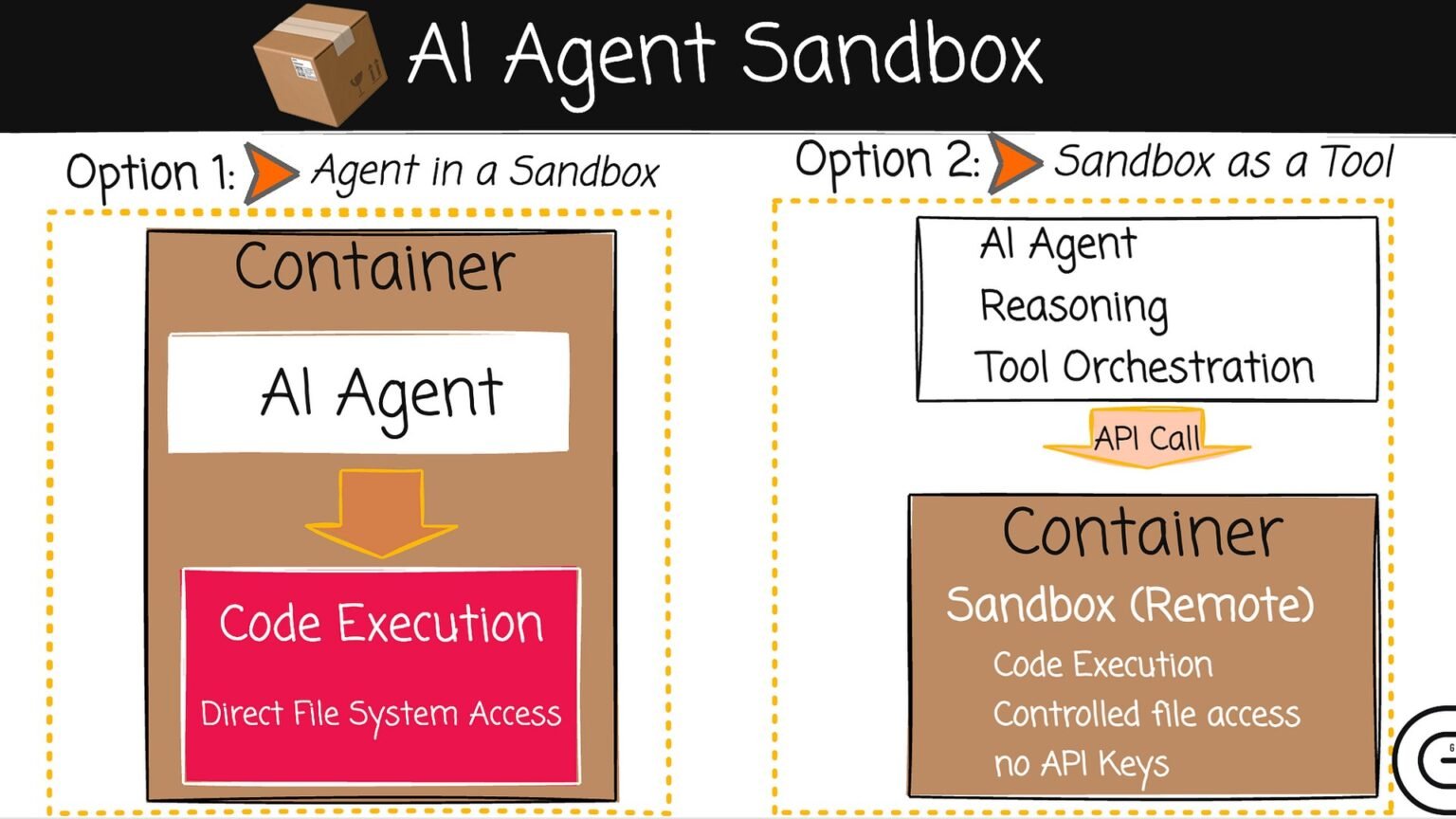
For most builders running untrusted LLM-generated code, the best AI agent sandbox 2026 has no single winner — it splits cleanly by workload: E2B for hardware-isolated Python loops, Daytona for latency-sensitive restart-heavy loops, Modal for any loop that needs a GPU inside the sandbox, and Northflank for unlimited-duration or your-own-cloud execution at the lowest per-core cost. The honest answer the vendor blogs avoid is that the “best” depends on your loop pattern, your trust level for the code, and whether a GPU lives on the sandbox side of the wire.
We wrote this because the search results for this question are dominated by one vendor’s own blog (which, predictably, concludes that vendor wins) and a layer of thin listicles. Nobody runs the decision on the four axes buyers actually weigh. So this comparison is deliberately neutral: we name real per-vCPU-hr numbers, real cold-start figures, and the isolation grade of each platform, then point you to the right pick by loop pattern rather than crowning a universal champion.
The four platforms in scope — E2B, Daytona, Modal, and Northflank — represent the serious options for an agent that must execute code it did not write. There are lighter-weight choices (Vercel Sandbox, Cloudflare Sandboxes, Fly.io Sprites, Blaxel), and we reference their numbers where useful, but the core E2B vs Daytona vs Modal decision plus Northflank as the BYOC wildcard covers the vast majority of production agent loops in 2026.
E2B vs Daytona vs Modal vs Northflank: the comparison table
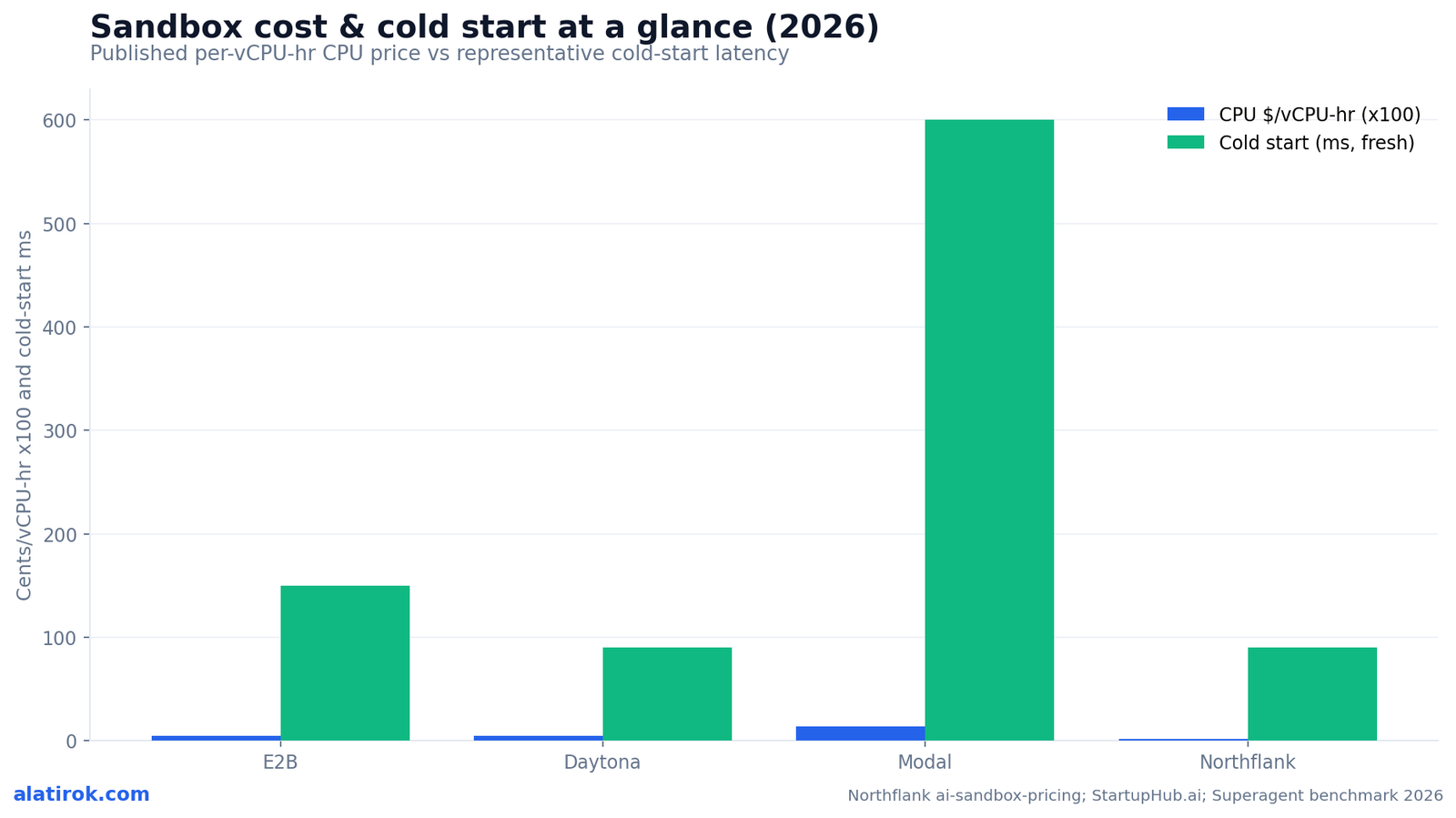
Across the four axes that decide an AI code execution sandbox comparison — cold start, isolation grade, GPU-in-sandbox, and per-vCPU-hr cost — E2B and Daytona share the cheapest published CPU rate ($0.0504/vCPU-hr), Modal is the only one that can put a GPU inside the sandbox, and Northflank undercuts everyone on per-core price with unlimited duration. The table below is the figure every vendor post buries, assembled from their own public pricing and third-party benchmarks.
Two clarifications on the table. First, cold-start numbers are representative figures from public benchmarks, not formally computed p50/p95 distributions — treat them as order-of-magnitude. Second, E2B’s effective cold start drops to 5-30ms once you use Firecracker snapshot-restore (resuming a paused microVM with memory and filesystem intact) rather than booting fresh, which is the single most important nuance for loop economics.
At 200 concurrent sandboxes on identical specs, Northflank’s own pricing analysis puts PaaS at $7,200/mo and BYOC at ~$2,060/mo, versus $16,819 on both E2B and Daytona and $24,491 on Modal. The ordering is real even discounting the vendor’s framing — but it ignores cold-start tax per loop turn and GPU-in-sandbox, which is exactly why a single “cheapest” headline misleads.
| Axis | E2B | Daytona | Modal | Northflank |
|---|---|---|---|---|
| Isolation | Firecracker microVM (dedicated kernel) | Container default; optional Kata/Sysbox | gVisor (shared kernel + syscall filter) | Kata + Cloud Hypervisor microVM; gVisor fallback |
| Cold start | ~150ms fresh; 5-30ms snapshot-restore | ~90ms (optimized configs ~27ms) | Sub-second | microVM-class (varies by host) |
| CPU price | $0.0504/vCPU-hr | $0.0504/vCPU-hr | $0.1419/physical core-hr (~3x sandbox premium) | $0.01667/vCPU-hr PaaS; lower on BYOC |
| RAM price | $0.0162/GiB-hr | $0.0162/GiB-hr | $0.0242/GiB-hr | $0.00833/GB-hr PaaS |
| Max session | 24h on Pro ($150/mo) | Unlimited | Unlimited | Unlimited |
| GPU in sandbox | No | GPU-capable (not in the sandbox process) | Yes — T4 / A10G in the sandbox | Yes (BYOC GPUs, ~62% cheaper than Modal) |
| BYOC (your cloud) | No | No | No | Yes — AWS/GCP/Azure/bare-metal |
Cold start cost per agent loop turn: the metric nobody prices
The cost that actually hurts in an agent loop is not the per-hour rate — it is the cold-start tax paid every iteration when you spin a fresh sandbox per turn. A coding agent that runs 30 tool calls per task, each in a brand-new environment, pays that startup latency 30 times. This is the figure no vendor leads with because it reframes the whole comparison around your loop pattern, not their price list.
There are two loop patterns, and they invert the ranking. In the fresh-per-turn pattern (each tool call gets a clean environment for maximum isolation), cold start dominates wall-clock time and Daytona’s ~90ms — or E2B’s 5-30ms snapshot-restore — is the deciding factor. In the persistent-session pattern (one sandbox stays alive across the whole loop, accumulating state), cold start is paid once and becomes irrelevant; what matters then is per-vCPU-hr over the session’s full duration and the session cap.
This is why E2B’s Firecracker snapshot-restore matters more than its ~150ms fresh-boot number. Firecracker can pause a microVM and resume it — memory and block-device filesystem intact — in 5-30ms, per Spheron’s setup guide. For a fresh-per-turn loop that wants microVM isolation, that turns the cold-start tax from a 150ms penalty into a near-rounding-error, while still giving each turn a dedicated kernel. Daytona wins the raw fresh-boot race (~27ms optimized), but it does so with a shared-kernel container unless you opt into Kata.
Concretely: if your loop is fresh-per-turn and the code is trusted-ish, Daytona’s container speed is hard to beat. If it’s fresh-per-turn and the code is hostile, E2B snapshot-restore gives you near-Daytona speed with a real kernel boundary. If it’s persistent-session, cold start drops out of the decision entirely and you should optimize for price and duration — where Northflank’s $0.01667/vCPU-hr and unlimited session pull ahead.
Firecracker vs gVisor sandbox isolation: how strong is each grade?
For untrusted, attacker-influenced code, a Firecracker microVM (dedicated kernel, hardware virtualization via KVM) is the strongest grade among these four; gVisor (a user-space kernel intercepting syscalls on a shared host kernel) is a meaningful middle tier; and a plain container with a shared kernel is the weakest. The Firecracker vs gVisor sandbox isolation question is the second axis buyers must weigh, and it maps directly onto how adversarial your code really is.
The mechanics: Firecracker, the ~50K-line Rust VMM behind E2B, gives every sandbox its own guest kernel, so a kernel-level exploit in the guest does not reach the host kernel. gVisor — Modal’s isolation layer — runs a user-space “Sentry” kernel that intercepts and reimplements syscalls, which shrinks the host kernel attack surface but still shares it, at a roughly 10-15% CPU overhead per Spheron’s measurements. A bare container shares the host kernel directly with only seccomp/namespace controls, which is why Daytona’s container default is the weakest grade unless you turn on Kata or Sysbox.
Northflank sits in a hybrid spot worth understanding: it uses Kata Containers backed by Cloud Hypervisor as the primary VMM for microVM-grade isolation, and falls back to gVisor where syscall interception suffices or nested virtualization is unavailable on the host. That gives it microVM isolation comparable to E2B’s when the host supports it. Daytona’s tiered model (Docker+Seccomp for speed, Kata+Cloud Hypervisor for max isolation, Sysbox for rootless) means your security grade depends entirely on your configuration choice — a real footgun if you assume the default is microVM-strong.
“gVisor is fine for semi-trusted code you mostly wrote. It is not what I’d put between a jailbroken prompt and my host kernel.”
Surya Koritala, founder of Cyntr
Modal sandbox GPU for agents: the only one that holds a GPU
Modal is the only platform of the four where a sandbox can hold a GPU — a T4 or A10G — inside the same isolated process that runs the agent’s tool calls, making it the default pick for any loop that does inference, fine-tuning, or image work on the sandbox side. If your agent needs a GPU mid-loop, the Modal sandbox GPU story ends the comparison: the other three force a second network hop to a separate GPU service.
The catch is price. Modal Sandboxes bill at a non-preemptible rate — roughly $0.1419 per physical core-hr (a 2-vCPU core), which the StartupHub comparison frames as about a 3x premium over Modal’s base function rate. GPU rates are competitive on paper (A10G and T4 around $1.10/hr class), but the CPU premium and gVisor isolation are the trade-offs you accept for GPU-in-sandbox convenience.
Northflank is the spoiler here: it also supports GPUs (H100, A100, L4 and more) and, per its own benchmarks, runs roughly 62% cheaper on GPU and ~65% cheaper on CPU than Modal because it bills compute all-inclusive rather than stacking separate GPU/CPU/RAM line items. The difference is that Modal’s GPU lives inside the sandbox primitive itself with a polished Python SDK, whereas Northflank gives you GPU workloads in your own infrastructure. For a tightly-coupled inference-in-the-loop agent, Modal’s ergonomics often win; for batch or cost-sensitive GPU work, Northflank’s pricing does.
Northflank vs E2B pricing and session caps: the long-loop wildcard
On the Northflank vs E2B pricing question, Northflank is roughly 3x cheaper per vCPU-hr ($0.01667 vs $0.0504) and offers unlimited session duration plus BYOC, while E2B caps Pro sessions at 24 hours and runs only on its managed cloud — so Northflank wins long-lived or compliance-bound agents, E2B wins fast microVM isolation with the largest template catalog. This is the fourth axis: session/duration caps and where the code physically runs.
Session caps bite in specific ways. E2B’s free Hobby tier limits sessions to 1 hour with 20 concurrent sandboxes and a one-time $100 credit; Pro ($150/mo) lifts that to 24-hour sessions with more concurrency and customizable CPU/RAM. Vercel Sandbox is even tighter (45 minutes to 5 hours). Daytona, Modal, and Northflank all support effectively unlimited duration — which matters for a research agent that runs for days or a stateful workspace an agent returns to repeatedly.
BYOC is Northflank’s structural moat: it is the only one of the four that runs sandboxes inside your own AWS, GCP, Azure, Oracle, CoreWeave, Civo, or bare-metal account, so data never leaves your VPC. For regulated workloads — finance, healthcare, anything with data-residency rules — that often outweighs raw per-core price, and it is the single reason a buyer might pick Northflank even where E2B’s isolation or Modal’s GPU would otherwise win.
Pros
Cons
Which sandbox for your loop pattern? A decision flowchart
Pick by answering four questions in order: (1) Does a GPU run inside the loop? If yes, Modal (or Northflank BYOC for cost). (2) Must the code run in your own cloud? If yes, Northflank. (3) Is the code genuinely hostile? If yes, E2B microVM (use snapshot-restore for fresh-per-turn). (4) Otherwise, is it a restart-heavy loop where raw cold start dominates? If yes, Daytona; if it’s a long persistent session, Northflank on price. That ordering resolves the E2B vs Daytona vs Modal decision for almost every agent without a universal-winner cop-out.
Worked examples make it concrete. A coding agent that compiles and tests untrusted patches in a fresh environment each turn: E2B with snapshot-restore — microVM isolation at near-container speed. A data-analysis agent that loads a model and crunches numbers on a GPU mid-loop: Modal, because the GPU lives in the sandbox. A long-running research agent in a regulated bank that must keep data in-VPC for days: Northflank BYOC. A latency-sensitive REPL loop running mostly-trusted code with frequent restarts: Daytona’s ~27ms optimized cold start.
The meta-point the vendor blogs miss: these are not competitors for a single crown, they are answers to different questions. The mistake buyers make is reading a Northflank post (Northflank wins), a Modal post (Modal wins), or a thin listicle (whatever’s #1 on the affiliate sheet) and generalizing. Match the platform to your loop pattern and trust level, and the right pick is usually unambiguous.
Default starting point if you are unsure: prototype on E2B (free Hobby tier, microVM isolation, no card) to validate your loop, then move to Northflank BYOC if cost or data-residency bites, Modal if yBuilder’s take
I run agent loops in production at Cyntr, where every orchestration turn can spawn a fresh execution environment. The sandbox decision is not abstract for me — it shows up on the bill and in the p95. Here is how I actually reason about it, separate from any vendor’s framing.
- The number nobody quotes is cost-per-loop-turn. A coding agent that spins a new sandbox each iteration pays the cold-start tax dozens of times per task. That is where Firecracker snapshot-restore (5-30ms) quietly beats a 200ms cold container, and where it stops mattering if you keep one sandbox alive across the whole loop.
- Isolation grade is a real axis, not marketing. If the code is genuinely adversarial — arbitrary npm installs, attacker-influenced prompts — I want a dedicated kernel (microVM), not a shared one with syscall filtering. gVisor is fine for semi-trusted code you mostly wrote; it is not what I’d put between a jailbroken prompt and my host.
- GPU-in-sandbox is a hard fork in the road. Only Modal lets the same isolated process that runs the model’s tool calls also hold a T4 or A10G. If your agent does inference or image work inside the loop, the other three force a second hop, and that hop usually erases their pricing advantage.
- I treat the headline per-vCPU-hr as table stakes and the session cap and BYOC story as the tiebreaker. E2B’s 24h cap on Pro is fine for tasks; for a long-lived agent or a compliance-bound workload, unlimited duration and your-own-VPC execution are worth more than a few cents per core-hour.
Frequently asked questions
There is no single best AI agent sandbox in 2026 — it depends on your loop pattern. E2B (Firecracker microVM) is best for hardware-isolated untrusted code; Daytona is best for restart-heavy, latency-sensitive loops; Modal is the only one that can hold a GPU inside the sandbox; and Northflank is cheapest per vCPU-hr with unlimited duration and bring-your-own-cloud. Match the platform to whether a GPU runs in the loop, whether code must stay in your VPC, how hostile the code is, and whether you restart per turn or keep one session alive.
Yes, on a fresh boot. Daytona markets sub-90ms cold starts with optimized configs around 27ms, versus E2B’s roughly 150ms fresh Firecracker boot. But E2B’s snapshot-restore resumes a paused microVM with memory and filesystem intact in 5-30ms, which narrows the gap dramatically while keeping a dedicated kernel. Daytona achieves its speed with a shared-kernel container by default, so the fair comparison is Daytona container speed vs E2B microVM safety.
Modal is the only one of the four where a sandbox can hold a GPU (such as a T4 or A10G) inside the same isolated process that runs the agent’s tool calls. E2B has no GPU. Daytona is GPU-capable but not inside the sandbox process the way Modal is. Northflank supports GPUs (H100, A100, L4) in your own cloud and, per its benchmarks, runs roughly 62% cheaper on GPU than Modal, but Modal’s GPU-in-sandbox ergonomics are the most tightly integrated.
Firecracker is the stronger isolation grade for genuinely untrusted code because it gives each sandbox a dedicated guest kernel via hardware virtualization (KVM), so a kernel exploit in the guest does not reach the host kernel. gVisor runs a user-space kernel that intercepts syscalls on a shared host kernel — a smaller attack surface than a plain container but still shared, at roughly 10-15% CPU overhead. E2B and Northflank (Kata + Cloud Hypervisor) use microVM isolation; Modal uses gVisor; Daytona uses a shared-kernel container unless you enable Kata or Sysbox.
As of 2026, E2B and Daytona both publish $0.0504 per vCPU-hour plus about $0.0162 per GiB-hour of RAM. Modal Sandboxes bill around $0.1419 per physical core-hr (a roughly 3x premium over its base function rate). Northflank is cheapest at $0.01667 per vCPU-hr on PaaS and lower on BYOC. At 200 concurrent sandboxes, Northflank’s analysis puts monthly cost at $7,200 PaaS (about $2,060 BYOC) versus $16,819 on E2B and Daytona and $24,491 on Modal.
The strongest E2B alternatives in 2026 are Daytona (faster fresh cold start, unlimited duration, flexible Kata/Sysbox isolation), Modal (GPU inside the sandbox), and Northflank (cheaper per vCPU-hr, unlimited duration, bring-your-own-cloud). Lighter options include Vercel Sandbox, Cloudflare Sandboxes, Fly.io Sprites, and Blaxel (which benchmarks around 25ms cold start). Choose based on GPU need, where code must run, isolation grade, and your loop’s restart pattern rather than a single ranking.
Primary sources
- Daytona vs E2B in 2026: which sandbox for AI code execution? — Northflank
- AI Sandbox pricing comparison (2026) — Northflank
- Daytona vs E2B vs Modal vs Vercel Sandbox: A 2026 Comparison — StartupHub.ai
- AI Agent Code Execution Sandboxes on GPU Cloud: E2B, Daytona, and Firecracker Setup Guide (2026) — Spheron
- AI Code Sandbox Benchmark 2026 – Modal vs E2B vs Daytona — Superagent
- Cloud Hypervisor vs gVisor — Northflank
- Plan Pricing — Modal
- Pricing — E2B
- Sandboxes documentation — Daytona
- E2B, Daytona, Modal, and Sprites.dev – Choosing the Right AI Agent Sandbox Platform — SoftwareSeni
Last updated: June 2, 2026. Related: Agent Infrastructure.




