

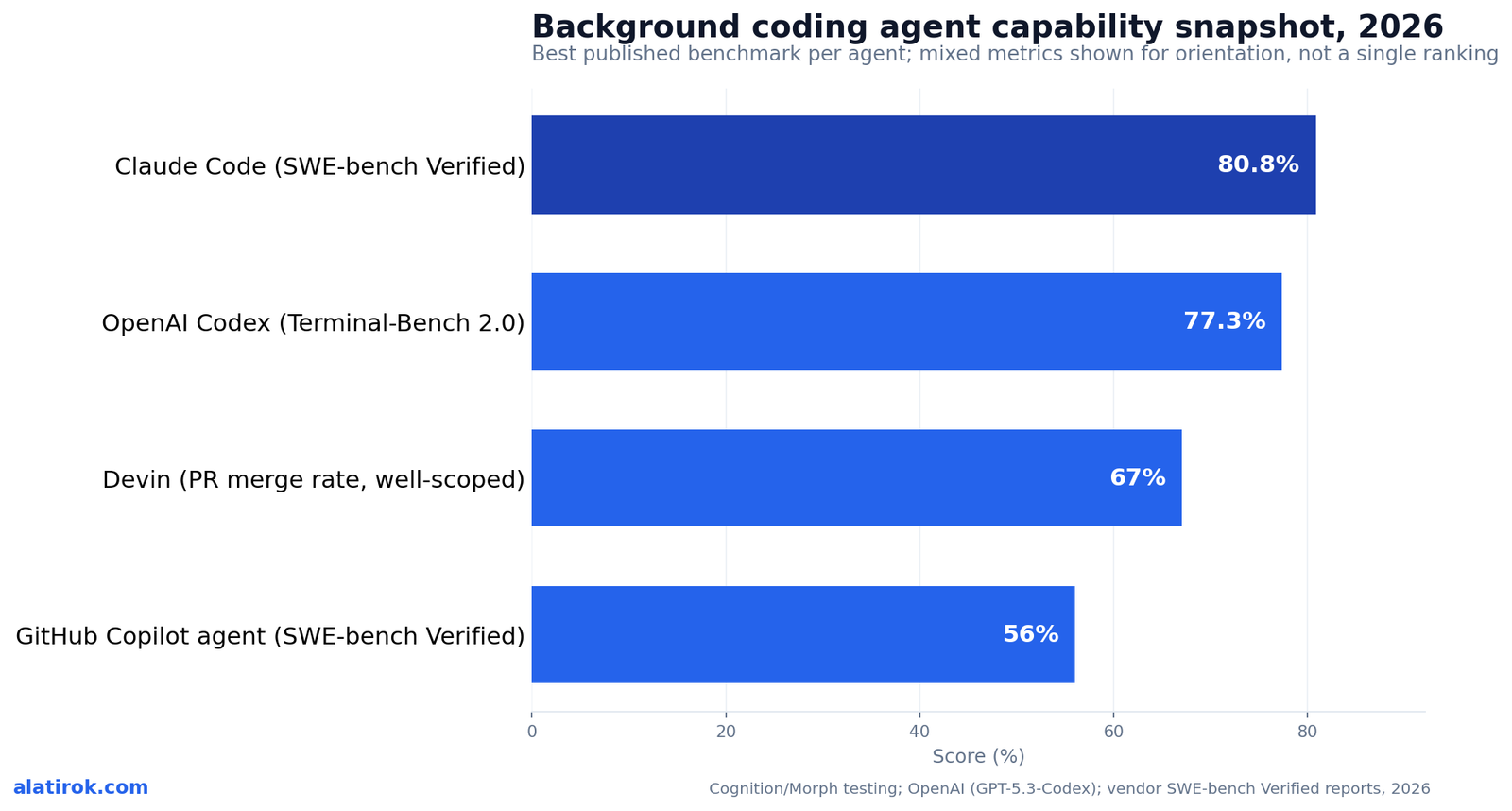
We ranked the truly autonomous, repo-cloning, PR-opening coding agents on the only metrics that matter for the background job: PR merge rate, SWE-bench Verified, parallel sessions, sandbox model, and cost per task. No IDE copilots.
What are the best autonomous coding agents in 2026?
The best autonomous coding agents 2026 buyers should shortlist are Devin, Google Jules, OpenAI Codex (cloud/background), and Claude Code Agent Teams — four background agents that clone your repository into an isolated cloud sandbox, work asynchronously, and open a pull request without a human babysitting an IDE. Every pick on this list does the same job: you hand it a GitHub issue or a one-line task, it disappears, and it comes back with a reviewable PR. That is a fundamentally different product from an IDE copilot like Cursor or Windsurf-the-editor, which lives in your editor and pairs with you keystroke by keystroke.
That distinction is exactly why most rankings are useless to a buyer with this intent. Nearly every “best AI coding agent” list lumps IDE copilots in with true background agents and scores them on a single axis, which is apples-to-oranges. A copilot’s autocomplete latency is irrelevant when the agent runs for twenty minutes in a VM you never see. So we scoped this list strictly to the background/async job and ranked on the data that actually predicts whether a delegated task ships: PR merge rate, SWE-bench Verified, Terminal-Bench 2.0, parallel-session count, the sandbox/VM model, and cost per task.
If you only remember one thing: benchmark scores rank the model, but PR merge rate ranks the product. A 90%-on-paper model that opens PRs your reviewers reject is worse than a 67%-merge-rate agent whose output your team actually ships. We weight merge rate and cost per task above leaderboard glory throughout this guide.
Background coding agents compared (merge rate, benchmarks, cost)
For a head-to-head on the metrics that matter, the comparison table below ranks the leading background coding agents on PR merge rate, SWE-bench Verified, Terminal-Bench 2.0, parallel sessions, sandbox model, and per-task cost — IDE-only tools are excluded by design. Read PR merge rate as the outcome metric (does the work ship?) and the benchmarks as capability proxies (can the model do the work?). The two diverge more than vendors admit.
A note on the numbers: SWE-bench Verified and Terminal-Bench 2.0 figures come from vendor reports and independent trackers and move week to week as models update. PR merge rates are scenario-dependent — Devin’s widely-cited ~67% is on well-defined tasks like migrations and tech-debt cleanup, not on open-ended feature work, where every agent is dramatically worse. Treat the table as a 2026 snapshot, not a leaderboard frozen in stone.
Those are IDE copilots: they shine when you are in the editor driving. This list is scoped to the background job — hand off an issue, get a PR back. Note the blurring lines: Cognition now owns both Devin and Windsurf, and Cline (~5M+ installs, zero token markup) ships an autonomous mode, but its center of gravity is still the editor.
| Agent | PR merge rate (well-scoped) | SWE-bench Verified | Terminal-Bench 2.0 | Parallel sessions | Sandbox / VM model | Per-task cost |
|---|---|---|---|---|---|---|
| Devin (Cognition) | ~67% (up from ~34%) | n/a (uses own scaffold) | n/a | Yes (parallel sessions) | Full cloud VM: IDE + browser + terminal + shell | $20/mo Core + ~$2.25/ACU (~15 min); bug fix ≈ 2–3 ACU |
| OpenAI Codex (cloud) | Not vendor-published | ~80–85% (GPT-5.3-Codex) | 77.3% (Codex harness) | Yes (Background Computer Use, Apr 16 2026) | Isolated OpenAI cloud containers + computer use | ChatGPT Plus $20 / Pro $200; token-metered (Apr 2 2026) |
| Google Jules | Not vendor-published | Gemini 2.5 Pro-class | n/a | Up to 3 concurrent (free tier) | Repo cloned into secure Google Cloud VM | Free: 15 tasks/day; paid via AI Pro $19.99 / Ultra $124.99 |
| Claude Code (Agent Teams) | High on real repos (4% of public commits) | ~80.8–80.9% (Opus) | Strong (multi-file) | Yes (Agent Teams, Feb 2026) | Local or cloud; subagents + worktrees | Token-metered via Claude plans; Pro/Max tiers |
| Grok Build (xAI) | Not vendor-published | Not vendor-published | Not vendor-published | Up to 8 (Arena Mode) | CLI on your machine (not a hosted VM) | SuperGrok / X Premium+ — ~$300/mo list ($99 intro) |
| GitHub Copilot coding agent | Not vendor-published | ~56% | n/a | Per-issue (GitHub Actions) | Sandboxed GitHub Actions runner | From $10/mo (15M devs) |
Devin vs Jules vs Codex background: which should you pick?
For Devin vs Jules vs Codex background, pick Devin for the most self-sufficient agent on well-defined engineering tasks, Jules for the cheapest serious on-ramp (a genuinely usable free tier), and Codex for the deepest reasoning plus computer-use reach when your task spills past the repo. All three clone your repo into a sandbox and open a PR; the differences are in autonomy, cost shape, and how far they roam outside the code.
Devin is the purest expression of the category. It runs a fully sandboxed cloud environment with its own IDE, browser, terminal, and shell, and it is built to grind through migrations, framework upgrades, and tech-debt cleanup with minimal hand-holding. Its ~67% PR merge rate on well-scoped tasks — up from roughly 34% over the prior year — is the headline credibility number in the whole space. The catch is the cost shape: $20/month Core plus about $2.25 per Agent Compute Unit (~15 minutes of work), so a 2–3 ACU bug fix is cheap but a 30-ACU migration can cross $70.
Google Jules is the value play. Now generally available and powered by Gemini 2.5 Pro, it clones your codebase into a secure Google Cloud VM, works asynchronously, and opens a PR — and the introductory free tier (15 tasks/day, 3 concurrent) is the most generous on-ramp of any serious background agent. Paid usage rides along with Google AI Pro ($19.99/mo) or Ultra ($124.99/mo). For teams already in Google’s ecosystem, Jules is the lowest-friction way to start delegating real work.
OpenAI Codex is the reach play. The cloud agent runs in isolated OpenAI containers with full repo access, and GPT-5.3-Codex posts a category-leading 77.3% on Terminal-Bench 2.0 with SWE-bench Verified in the ~80–85% range. The April 16, 2026 Background Computer Use update lets Codex see, click, and type across apps and even schedule future work and wake itself up to continue long tasks — useful when the job needs a dashboard or a browser, not just a diff. Billing moved to token-metering on April 2, 2026, available through ChatGPT Plus ($20) and Pro ($200).
“Benchmark scores rank the model. PR merge rate ranks the product. A 90%-on-paper agent that opens PRs your reviewers reject is worse than a 67%-merge-rate agent whose work your team actually ships.”
Alatirok analysis, 2026
Google Jules vs OpenAI Codex 2026: free tier vs frontier reach
In Google Jules vs OpenAI Codex 2026, choose Jules when cost and a no-commitment free tier matter most, and Codex when you need the strongest agentic-coding model and the ability to operate apps and browsers beyond the repo. Both are true background agents — clone, work async, open a PR — but they optimize for different buyers.
Jules’s advantage is economic and operational. The free tier (15 daily tasks, 3 concurrent) means an engineer can route a dozen small chores — dependency bumps, lint fixes, test scaffolding, changelog generation — to Jules every day at zero marginal cost, then escalate to a paid Google AI plan only when volume justifies it. Because it runs in Google Cloud VMs and is private by default (it does not train on your private code), it is an easy security sign-off for Google-shop teams.
Codex’s advantage is capability ceiling and scope. GPT-5.3-Codex is purpose-built for agentic software engineering, and Background Computer Use turns Codex from a code-only agent into something that can drive the surrounding tooling — reviewing PRs, running multiple terminals, connecting to remote devboxes over SSH, and operating apps with its own cursor. If your background task is really an end-to-end chore (reproduce a bug in a staging UI, then fix it), Codex reaches further than a repo-bound agent. You pay for that reach in token-metered billing that can run $100–$200/developer/month for heavy users.
The honest tiebreaker: start tasks on Jules’s free tier to see how much of your backlog is genuinely automatable, then promote the high-value, high-complexity work to Codex (or Devin) where the extra capability earns its cost.
Rule of thumb: pilot on Jules’s free tier to learn which chores actually automate, then promote the gnarly, high-value tasks to Codex or Devin where the extra capability pays for itself.Parallel coding agents and the February 2026 multi-agent wave
Parallel coding agents went mainstream in a single two-week window in February 2026, when nearly every major tool shipped multi-agent: Grok Build (up to 8 agents), Windsurf (5 parallel via git worktrees), Claude Code Agent Teams, the Codex CLI, and Devin parallel sessions all landed at once. Running several agents simultaneously on different parts of a codebase went from novelty to table stakes almost overnight.
Mechanically, most parallelism rides on git worktrees: each agent checks out the repo into its own directory on its own branch, so five or eight agents can work without stepping on each other, then their branches surface as separate PRs or get arbitrated. Windsurf’s Wave 13 was the first commercial IDE to make this first-class, spawning up to five Cascade agents across isolated worktrees. Grok Build pushes the count to eight with an Arena Mode that fans agents out to plan, search docs, and write code in parallel — though Grok Build is a CLI that runs on your machine, not a hosted background VM, and it ships behind SuperGrok / X Premium+ at roughly $300/month list (a time-limited $99 intro).
The strategic subtlety buyers miss: parallelism is a throughput lever, not a correctness lever. Eight agents do not make any single agent’s diff more likely to merge; they let you attack eight tasks at once, or race several attempts at one task and keep the best. That is genuinely valuable for backlog burn-down and for “try five approaches” exploration — but if your single-agent merge rate is 50%, eight agents just generate rejected PRs eight times faster. Fix the merge rate first, then scale the parallelism.
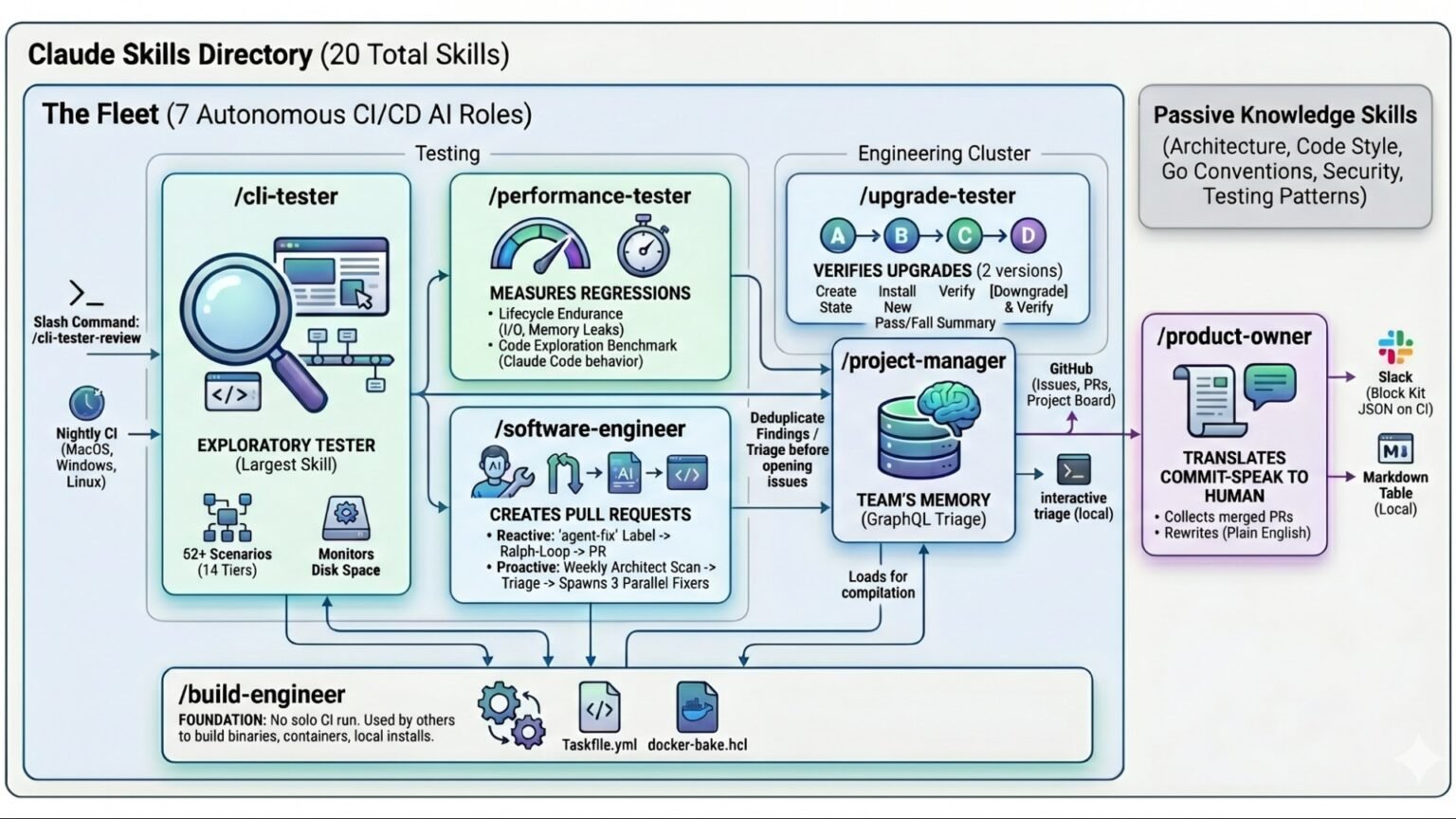
How do background coding agents actually work?
A background coding agent works by cloning your repository into an isolated cloud sandbox (a VM or container with a shell, file system, and test runner), planning a change from your task description, editing files, running your tests, iterating until they pass, then opening a pull request for human review. You never watch it type; you review the diff at the end. That async, review-at-the-end loop is the defining shape of the category.
The five stages are consistent across Devin, Jules, Codex cloud, and Copilot’s coding agent. First, ingestion: the agent clones the repo and reads enough context to orient (Jules uses a secure Google Cloud VM; Codex uses isolated OpenAI containers; Copilot uses a sandboxed GitHub Actions runner). Second, planning: many agents now expose a plan/approval step so you can correct course before any code changes. Third, execution: the agent edits files, runs commands, and reads output in its sandbox. Fourth, verification: it runs your test suite and linters and loops on failures. Fifth, handoff: it pushes a branch and opens a PR — usually as a draft — with a summary of what it did.
Two implementation details decide whether you can trust the output. Sandbox isolation determines blast radius: a fully isolated VM that never touches your machine or production is the safe default, which is why repo-clone-into-VM (Jules, Devin) and ephemeral-container (Codex, Copilot) models dominate. And test gating determines quality: an agent that must make CI green before it hands you a PR is worth far more than one that opens a PR and hopes. The best results come from feeding the agent a repo with strong tests and a precisely-scoped issue — the agent is only as good as the spec and the safety net you give it.
What tasks do background agents handle well today?
Migrations (framework and language version bumps), dependency upgrades, flaky-test fixes, well-specified GitHub issues, boilerplate generation, mechanical refactors, and adding test coverage. These share three traits: a clear definition of done, a strong test suite to verify against, and limited need for product judgment. This is where Devin’s ~67% merge rate lives.What tasks still go badly?
Open-ended feature work, anything needing product or design judgment, ambiguous bug reports, cross-service changes with hidden coupling, and tasks where ‘correct’ depends on tribal knowledge not in the repo. Merge rates collapse here. Mitigation: write the issue like a spec for a junior contractor, and break big asks into small, independently-mergeable PRs.How do I keep per-task cost from spiking?
Budget per merged PR, not per seat. Watch consumption-based pricing (Devin’s ACUs, Codex’s token metering) on long-running tasks — a 30-ACU migration can cross $70. Set task scope tight, kill runs that loop, prefer agents with a plan/approval gate so you abort bad plans before they burn compute, and start on a free tier (Jules) to calibrate.Best autonomous coding agents 2026: verdict and best-for picks
Start on Jules’s free tier, promote hard tasks to Devin or Codex, reserve Claude Code for quality-critical repos
The best autonomous coding agents 2026 verdict: Devin is the best overall background agent for self-sufficient engineering work, Google Jules is the best value and best free tier, OpenAI Codex is the best for reach beyond the repo, and Claude Code Agent Teams is the best for teams already living in Claude with strong test suites. There is no single winner — the right pick is the one matched to your task profile and budget shape.
The score cards below weight what this buyer actually cares about: PR merge rate and cost per task first, raw benchmarks second. We deliberately did not rank Grok Build, Copilot’s coding agent, or Cline at the top — Grok Build is an impressive CLI but a machine-local one priced for power users, Copilot’s coding agent is a convenient on-ramp at ~56% SWE-bench Verified rather than a frontier performer, and Cline (~5M+ installs, zero token markup) is fundamentally an editor tool with an autonomous mode bolted on.
Devin (Cognition)
Best for: Migrations, framework upgrades, and tech-debt cleanup on well-scoped tasks
What works
Watch out for
Google Jules
Best for: Teams in the Google ecosystem and anyone testing the waters at zero cost
What works
Watch out for
OpenAI Codex (cloud)
Best for: Complex, multi-step tasks that spill past code into apps, browsers, and long-running jobs
What works
Watch out for
Claude Code (Agent Teams)
Best for: Repos with strong test suites where code quality and multi-file reliability matter most
What works
Watch out for
Builder’s take
I run Cyntr and Loomfeed, and a chunk of both codebases now ships through background agents that I never watched type a character. After a year of delegating real work to these systems, here is what the ranking sheets miss.
- The merge rate is the only number that pays rent. SWE-bench Verified tells you a model can patch a known-buggy repo; it does not tell you whether the PR survives your reviewer, your CI, and your house style. Devin’s jump from ~34% to ~67% PR merge rate on well-scoped tasks is the more honest signal, and it is still a coin flip on anything ambitious.
- Scope is the whole game. Background agents win on migrations, dependency bumps, flaky-test fixes, and tightly-specified GitHub issues. They lose on anything requiring product judgment. I treat the issue description as a spec I’m writing for a junior contractor, not a wish I’m whispering to an oracle.
- Cost per task beats cost per seat. A $20 base plan that bills you $2.25 per Agent Compute Unit can quietly turn a 30-ACU migration into a $70 line item. I budget per merged PR, not per month, and I kill runs that loop.
- The February 2026 multi-agent wave was real but oversold. Eight parallel agents is great for fan-out search; it does not make any single agent’s output more correct. Parallelism is a throughput lever, not a quality lever.
- Cognition now owns both Devin and Windsurf, so the ‘background agent vs parallel IDE agent’ line is blurring inside one vendor. Watch the consolidation: the interesting fights in 2026 are OpenAI vs Anthropic vs Google on the async-PR job, with xAI’s Grok Build crashing the CLI lane.
Frequently asked questions
A background (autonomous) coding agent clones your repository into an isolated cloud sandbox, works asynchronously without you watching, and opens a pull request when done — examples include Devin, Google Jules, OpenAI Codex cloud, and Claude Code Agent Teams. An IDE copilot (Cursor, Windsurf-the-editor, Cline) lives in your editor and pairs with you keystroke by keystroke. They solve different jobs, which is why this guide ranks only the background agents and excludes IDE-only tools.
Devin has the most credible, widely-cited PR merge rate at roughly 67% on well-defined tasks like migrations and tech-debt cleanup, up from about 34% over the prior year. Most other vendors do not publish a PR merge rate, leaning on SWE-bench Verified or Terminal-Bench 2.0 instead — which measure model capability, not whether your reviewers actually merge the result. Merge rate is the outcome metric to weight most heavily.
It depends on the job. Jules wins on cost and on-ramp — it’s GA, runs on Gemini 2.5 Pro in a secure Google Cloud VM, and has a generous free tier (15 tasks/day, 3 concurrent). Codex wins on capability ceiling and reach — GPT-5.3-Codex leads Terminal-Bench 2.0 at 77.3%, and Background Computer Use lets it operate apps and browsers beyond the repo. A practical approach: pilot on Jules’s free tier, then promote complex tasks to Codex.
For GitHub-issue-to-PR workflows, the strongest options are GitHub Copilot’s coding agent (assign an issue, it runs in a sandboxed GitHub Actions runner and opens a draft PR), Google Jules (clones into a Google Cloud VM and opens a PR), and Devin (full cloud sandbox with the highest published merge rate). The best fit depends on your stack: Copilot for tightest GitHub integration, Jules for cost, Devin for autonomy on well-scoped issues.
Cost shape varies. Devin charges $20/month plus about $2.25 per Agent Compute Unit (~15 minutes), so a 2–3 ACU bug fix is cheap but a 30-ACU migration can cross $70. Codex is token-metered (April 2026) via ChatGPT Plus ($20) or Pro ($200), often $100–$200/developer/month for heavy users. Jules has a free tier (15 tasks/day) with paid usage via Google AI Pro ($19.99) or Ultra ($124.99). Budget per merged PR, not per seat.
Not directly. Parallelism — like Grok Build’s 8 agents or Windsurf’s 5 worktree-based Cascade agents from the February 2026 multi-agent wave — is a throughput lever, not a correctness lever. Running eight agents lets you attack eight tasks at once or race several attempts and keep the best; it does not make any single agent’s diff more likely to merge. If your single-agent merge rate is low, parallelism just generates rejected PRs faster. Improve merge rate first, then scale parallelism.
Primary sources
- Jules: Google’s autonomous coding agent (GA announcement) — Google
- Google’s AI coding agent Jules is now out of beta — TechCrunch
- Codex for (almost) everything (Background Computer Use, April 16 2026) — OpenAI
- Introducing GPT-5.3-Codex (Terminal-Bench 2.0 77.3%) — OpenAI
- Plans and Pricing (Core $20 + ACU model) — Cognition / Devin
- Claude Code is the Inflection Point (4% of public GitHub commits) — SemiAnalysis
- Windsurf Wave 13 introduces SWE-1.5 and Git worktrees — Neowin
- xAI launches Grok Build coding agent in early beta for subscribers — Crypto Briefing
- Codex pricing (token-based, April 2 2026) — OpenAI
- Cline: autonomous coding agent (5M+ installs, zero markup) — GitHub / Cline
Last updated: June 3, 2026. Related: Products.




