


Anthropic’s new ‘dreaming’ feature lets Claude agents review their own past sessions and rewrite their memory between jobs. Here is the actual mechanism, where it sits in the memory stack, and whether you should turn it on.
What is Claude dreaming?
Claude dreaming is a scheduled, between-sessions process that reviews an agent’s past transcripts and memory store, extracts recurring patterns, and rewrites a curated memory layer so the agent improves over time — without retraining the model. Anthropic introduced it as a research-preview feature for Claude Managed Agents on May 6, 2026, at the Code with Claude developer conference in San Francisco, alongside a self-grading ‘outcomes’ loop and multi-agent orchestration.
The name is deliberate. Anthropic compares dreaming to hippocampal memory consolidation — the way a human brain replays the day’s events during sleep and decides what is worth keeping. While the agent is idle between jobs, a background pass reads what it did, decides what mattered, and reorganizes its notes accordingly.
The critical thing to understand up front: dreaming does not touch model weights. As Anthropic put it, the company is not doing ‘updates to the weights or anything like that.’ One write-up summed up the technique well — it is ‘closer to a structured note-taking ritual than to training.’ Dreaming is a maintenance layer that sits on top of an agent’s external memory and periodically improves the quality of what is stored there.
So when people call this a ‘self-improving AI agent,’ they mean something specific and narrow: the agent gets better at a recurring class of tasks because it stops forgetting the lessons it already paid for, not because the underlying intelligence changes.

Dreaming = scheduled review of past sessions + memory → pattern extraction → reorganized memory layer → better next runs. No weight changes. Research preview as of May 6, 2026. Opt-in, and you can require human review of memory edits.
How does Claude dreaming work, step by step?
Dreaming runs as a periodic background job that reads an agent’s recent sessions and its memory store, mines them for three kinds of patterns, then condenses stale entries and promotes load-bearing ones into a reorganized memory layer. The whole loop is plain-text and observable, which is what makes it auditable rather than a black box.
Per Anthropic’s explanation, the consolidation pass works on structured logs — not just the raw conversation transcript, but metadata about task outcomes, corrections the user made, tool calls that failed, and which memory entries were actually retrieved and used. That richer signal is what lets it tell a one-off from a real pattern.
The three pattern types dreaming surfaces are the heart of the feature: recurring mistakes (the same failure showing up across jobs), converged workflows (a sequence multiple sessions or agents independently arrived at), and shared preferences (conventions an entire agent team keeps applying). Each becomes a candidate edit to the memory layer.
Then it curates. Frequently retrieved, high-value entries get promoted and tightened into reusable notes or ‘playbooks.’ Entries that were never retrieved, or that are now stale, get condensed or dropped. The output is a smaller, cleaner, more load-bearing memory store than the agent accumulated by writing notes ad hoc during live sessions.
| Stage | What happens | Concrete output |
|---|---|---|
| 1. Collect | Background job reads recent sessions + the memory store | Transcripts, outcomes, failed tool calls, retrieval logs |
| 2. Extract | Mine for recurring mistakes, converged workflows, shared preferences | Candidate patterns with frequency signal |
| 3. Curate | Promote load-bearing entries, condense or drop stale ones | Reorganized, smaller memory layer |
| 4. Apply | Auto-apply, or hold for human review before commit | Updated memory the next session reads |
| 5. Improve | Next run reads the curated memory at task start | Fewer repeated mistakes, faster completion |
Where Claude dreaming sits in the memory architecture
Claude dreaming sits one layer above the file-based memory tool: the memory tool is the storage substrate, and dreaming is the curator that periodically rewrites what is stored there. You cannot understand dreaming without understanding the layer it depends on.
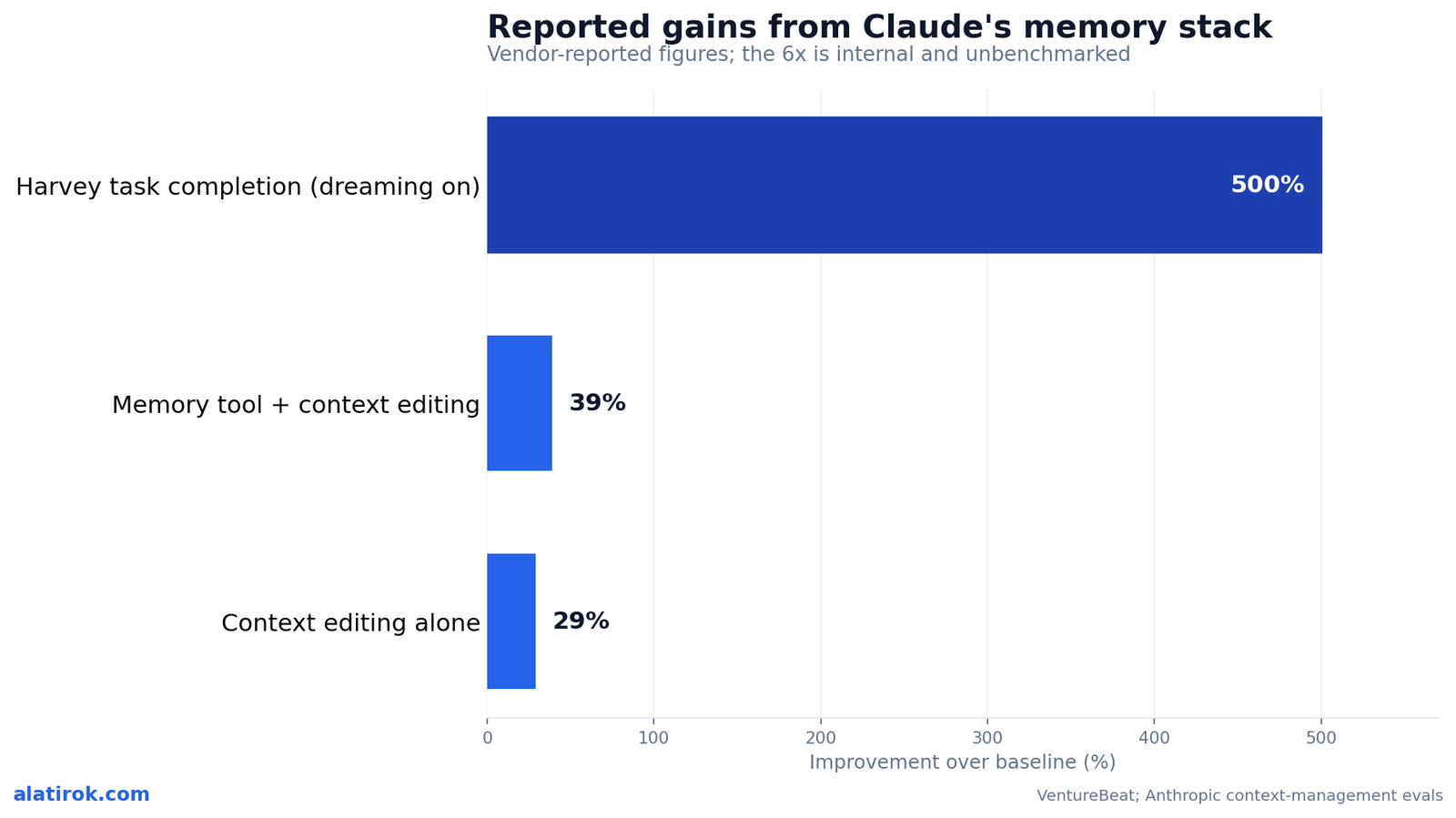
The foundation is Anthropic’s memory tool, available in public beta on the Claude Developer Platform (and natively on Amazon Bedrock and Google Cloud’s Vertex AI). It lets Claude create, read, update, and delete files in a dedicated memory directory that lives in your infrastructure and persists across conversations. The point is to keep durable knowledge outside the context window — Anthropic’s internal evals found that pairing the memory tool with context editing improved agentic-search performance by 39% over baseline.
During a live session, the agent writes notes to that store on the fly. That works, but it is messy: the agent has no global view of which notes are redundant, contradictory, or useless, because it is heads-down on the current task. Dreaming is the offline pass that takes that global view. It is the difference between scribbling sticky notes all day and actually filing them at night.
This is also how dreaming differs from the two things people confuse it with. Per-session agent memory is scoped to one job and is gone (or unconsolidated) afterward. Retrieval-augmented generation (RAG) fetches from a static, externally-curated corpus you maintain. Dreaming is neither — it is the agent curating its own experiential memory, a write-and-reorganize loop over knowledge the agent generated itself.
“The memory tool is where an agent keeps what it knows. Dreaming is the night shift that decides what’s worth keeping.”
Alatirok
Dreaming vs per-session memory vs RAG: what’s the difference?
The short version: per-session memory remembers within a job, RAG retrieves from a corpus you curate, and dreaming curates the agent’s own accumulated memory between jobs. They are complementary layers, not competitors — a serious agent stack can run all three.
The distinction that matters operationally is who owns curation and where the knowledge comes from. With RAG, you own the corpus and the agent only reads it. With dreaming, the agent both generates the knowledge (from its own runs) and reorganizes it. That autonomy is exactly what makes dreaming powerful for long-running work — and exactly what makes its failure mode different and more dangerous, as we’ll cover below.
| Property | Per-session memory | RAG | Claude dreaming |
|---|---|---|---|
| Scope | Single job | Static external corpus | Across sessions, days, operators |
| Knowledge source | Current task only | Documents you curate | The agent’s own past runs |
| Who curates | No one (ephemeral) | You / your pipeline | The agent, on a schedule |
| Persists between jobs? | Often no | Yes (read-only) | Yes (read + rewrite) |
| Main failure mode | Forgetting | Stale or irrelevant docs | Reinforcing its own bad patterns |
The Harvey 6x result: what actually happened
~6x
Harvey task-completion lift
Internal testing, no external benchmark
39%
Memory tool + context editing gain
Anthropic agentic-search evals, over baseline
May 6, 2026
Dreaming announced
Code with Claude, research preview
Legal-AI company Harvey reported that task-completion rates rose roughly 6x in internal testing after enabling dreaming. The number is the headline of Anthropic’s announcement — and it is genuinely instructive once you understand the specific problem it solved.
Harvey’s agents do long, repetitive legal-drafting work. Their recurring pain was that agents kept forgetting filetype quirks and tool-specific workarounds between sessions, so the same jobs failed in the same way over and over. Every session re-discovered the same fix from scratch. That is the textbook case dreaming is built for: a stable domain, a repeating failure, and a workaround worth remembering.
With dreaming on, the workarounds stuck. The consolidation pass recognized the recurring mistake, wrote the fix into the curated memory layer, and the next session read it before starting. The 6x lift is the compounding effect of no longer paying the same tax repeatedly.
Two honest caveats. First, as one analysis noted, 6x is the figure Anthropic is publishing without an external benchmark — it is a vendor-and-customer internal result, not an independent eval. Second, and importantly, Harvey did not run dreaming alone: they paired it with a tight outcomes rubric (the self-grading loop that shipped the same day) so that any drift in the memory store would be caught by the grader on the next run. That pairing is the real lesson, not the multiplier.
Does Claude dreaming cause more hallucinations?
It can — dreaming’s signature risk is a compounding feedback loop where a wrongly-extracted pattern gets written to memory, makes the next session fail, and then the next dreaming pass reads that failed transcript as confirmation the pattern was right. This is qualitatively worse than ordinary hallucination because the error actively deepens across iterations instead of staying constant.
Walk the loop: dreaming extracts a wrong pattern and writes it to the memory store. The next session uses that flawed memory and performs the task incorrectly. The following dreaming pass then reviews a transcript where the agent behaved ‘consistently’ with the bad memory — and can interpret that consistency as validation. The wrong memory becomes more deeply embedded. As one analysis put it bluntly, you get ‘a positive feedback loop of hallucination.’
There is a second, related risk vector: memory poisoning via prompt injection. Because the memory store now persists and is written automatically, a malicious input that convinces an agent of a wrong instruction during one session can get consolidated into long-term memory, where it is silently applied to every future session. Persistent, self-curating memory is a strictly larger attack surface than ephemeral memory.
This is why the controls matter more than the feature. Dreaming is opt-in, and the platform lets you require human review of memory edits before they take effect — Anthropic explicitly recommends that for high-stakes workflows. The defensible pattern, the one Harvey used, is dreaming plus an objective grader: a self-grading outcomes loop catches drift on the next run, so a bad memory edit gets flagged instead of entrenched.
Pros
Cons
How to evaluate whether dreaming is worth turning on
Worth it for narrow, instrumented, repetitive agents — risky everywhere else
Enable dreaming only when your workload is repetitive and single-domain, you have an objective grader to catch drift, and you can observe and diff the memory layer between runs. If any of those three are missing, the expected value tips negative.
Start with the workload test. Dreaming pays off where the same agent hits the same class of problem across many sessions — legal drafting, claims processing, a fixed codebase, a recurring ops runbook. If your agent does wildly different things each run, there are few stable patterns to extract and more chances to over-generalize noise into bad memory.
Then the safety test. Never run auto-apply on a high-stakes workflow without a grader. Pair dreaming with the outcomes loop (or your own eval harness) so every run is scored against a rubric; that is your tripwire for memory drift. For anything touching money, legal output, or production systems, require human review of memory edits before they commit — the platform supports exactly this.
Finally, the observability test. You should be able to read the curated memory as plain text and diff it between dreaming passes. If you cannot see what changed, you cannot catch the pattern-poisoning loop early, and you are flying blind. Roll it out on one narrow, instrumented workflow first, watch the memory diffs for a few cycles, and only then expand.
1) Repetitive, single-domain workload. 2) Objective grader scoring every run. 3) Plain-text memory you can diff. 4) Human review before commit for high-stakes paths. 5) Start narrow, expand only after clean memory diffs.
Builder’s take
I run agents in production at Cyntr, and the gap dreaming fills is real — but so is the trap. Here is how I’d reason about it before flipping it on.
- The hard problem in long-running agents was never recall — it was that the same agent kept re-learning the same workaround every session. Dreaming attacks exactly that, and it’s why Harvey’s number is plausible rather than hype.
- Treat dreaming as a write path into a shared knowledge base, not a magic ‘gets smarter’ button. A write path with no review is a memory-poisoning surface, full stop.
- We built our own curator-plus-grader loop at Cyntr for the same reason Harvey paired dreaming with an outcomes rubric: a consolidation pass with no objective check will happily entrench its own mistakes.
- If you can’t observe and diff the memory layer between runs, don’t enable auto-apply. Human-in-the-loop on the curation step is cheap insurance against compounding hallucination.
- Start it on one narrow, well-instrumented workflow. The 6x stories come from repetitive, single-domain jobs — not from sprawling general agents where ‘patterns’ are mostly noise.
Frequently asked questions
Claude dreaming is a scheduled process that, between an agent’s jobs, reviews its past sessions and memory, finds recurring patterns, and reorganizes its memory so it works better next time. It does not retrain the model — it is closer to structured note-taking than to training. Anthropic launched it as a research preview for Claude Managed Agents on May 6, 2026.
RAG retrieves from a static corpus you curate and the agent only reads it. Dreaming works on memory the agent generated from its own past runs and reorganizes that memory itself on a schedule. RAG is read-only over your documents; dreaming is a read-and-rewrite loop over the agent’s own experience.
It can. The signature risk is a feedback loop: dreaming writes a wrong pattern to memory, the next session fails because of it, and the following dreaming pass can read that failure as confirmation the pattern was right, deepening the error. Pairing dreaming with an objective grader and human review of memory edits is how teams like Harvey mitigate it.
Legal-AI company Harvey reported that task-completion rates rose roughly 6x in internal testing after enabling dreaming, because agents stopped forgetting filetype quirks and tool-specific workarounds between sessions. Note it is an internal figure without an external benchmark, and Harvey ran it alongside a self-grading outcomes rubric.
Plain-text notes and reusable ‘playbooks’ summarizing what succeeded, what failed repeatedly, workarounds for tool and filetype quirks, and conventions shared across an agent team. The dreaming pass promotes frequently-used, load-bearing entries and condenses or drops stale ones, producing a smaller, cleaner memory store.
As of its May 6, 2026 announcement, dreaming is in research preview for Claude Managed Agents and requires requesting access. It builds on the file-based memory tool, which is in public beta on the Claude Developer Platform, Amazon Bedrock, and Vertex AI. You can choose automatic memory updates or require human review before edits take effect.
Primary sources
- Anthropic introduces ‘dreaming,’ a system that lets AI agents learn from their own mistakes — VentureBeat
- Anthropic Launches Dreaming for Claude Agents at Code with Claude 2026 — Let’s Data Science
- Claude Dreaming — When AI Starts to ‘Dream’, and Why It Might Hallucinate More — GrandLinux
- Memory tool – Claude API Docs — Anthropic
- Managing context on the Claude Developer Platform — Anthropic
Last updated: June 6, 2026. Related: Agent Infrastructure.




