

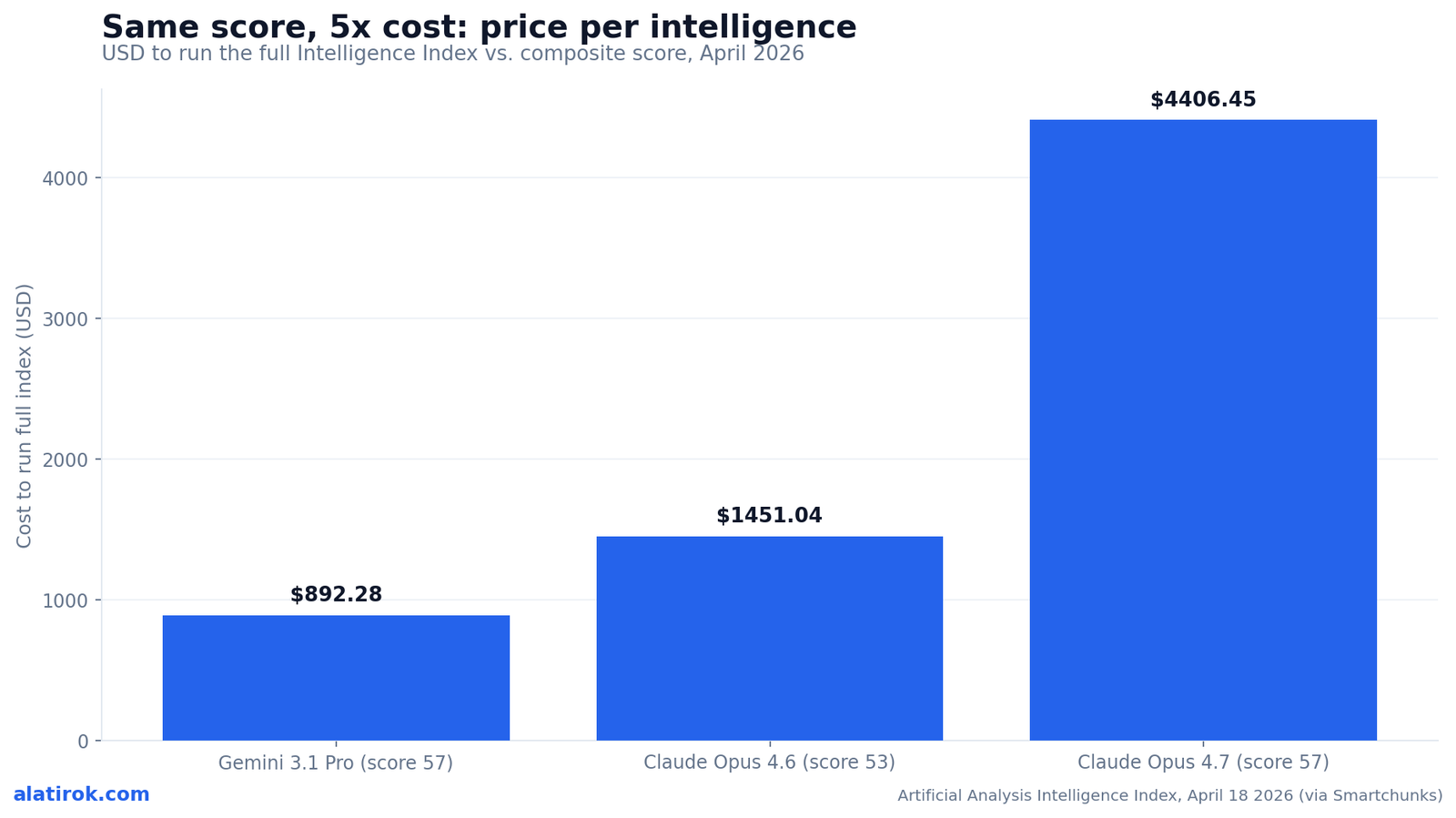
Three frontier models tied at 57 on the April 2026 Intelligence Index. Running that identical score cost from $892 to $4,406 – a 5x spread hiding in plain sight.
What does price per intelligence actually mean?
Price per intelligence is the dollar cost to reach a given score on a fixed capability benchmark – and in April 2026 three frontier models reached the exact same score for prices ranging from $892 to $4,406, a 5x spread. It is the difference between the number a vendor prints on the leaderboard and the number that shows up on your inference invoice.
The metric exists because the AI industry has spent two years optimizing the wrong axis. Leaderboards rank models by intelligence: how many problems they get right. But you do not buy intelligence by the unit – you buy tokens, and different models burn wildly different token counts to land on the same answer. Two models can tie on capability while one quietly costs five times as much to operate.
Artificial Analysis made this legible by publishing not just the composite Intelligence Index score for each model but the actual USD cost it spent running the full benchmark suite through each model’s API. That second number – the cost to run the index – is the closest thing the industry has to a standardized price-per-intelligence figure. When you put score on one axis and cost-to-run on the other, the frontier stops looking like a ladder and starts looking like a scatter plot with a 5x vertical spread at a single score.
This article walks the April 2026 snapshot where the spread was starkest, explains the token-efficiency mechanic that drives it, and updates the picture with the late-May frontier shift to Claude Opus 4.8 and GPT-5.5. The short version: stop reading the leaderboard as a price tag.
The April 2026 three-way tie at 57
57
Three-way tie
Opus 4.7, Gemini 3.1 Pro, GPT-5.4 xhigh
53
Claude Opus 4.6
Prior-gen flagship, one notch back
51
GLM-5.1
Open-weight challenger from Zhipu
10
Evals in the index
GDPval-AA, HLE, GPQA Diamond and more
On April 18, 2026, Claude Opus 4.7, Gemini 3.1 Pro Preview, and GPT-5.4 (xhigh) all scored exactly 57 on the Artificial Analysis Intelligence Index – a genuine three-way tie on capability. Claude Opus 4.6 trailed at 53 and Zhipu’s GLM-5.1 sat at 51, per the Artificial Analysis data summarized by Smartchunks.
By every measure the leaderboard cares about, those three top models were interchangeable. The composite index aggregates ten hard evaluations – GDPval-AA, Tau-squared-Bench Telecom, Terminal-Bench Hard, SciCode, AA-LCR, AA-Omniscience, IFBench, Humanity’s Last Exam, GPQA Diamond, and CritPt – so a tie at 57 is not a fluke on one test. It means three labs converged on roughly the same capability frontier in the same quarter.
If the leaderboard were a shopping list, you would flip a coin. But the cost-to-run column tells a completely different story, and it is the story that should drive the purchase decision.
A composite tie across ten independent evaluations is much stronger evidence of equivalence than matching on a single benchmark. It means picking the cheapest of the three at 57 costs you nothing in measured capability.
The 5x price per intelligence gap
Running the full Intelligence Index cost $4,406.45 on Claude Opus 4.7, $1,451.04 on Claude Opus 4.6, and just $892.28 on Gemini 3.1 Pro Preview – so Anthropic’s top model cost roughly 5x what Gemini did for an identical composite score of 57. Those figures come straight from Artificial Analysis’s per-model evaluation cost, as reported by Smartchunks for the April snapshot.
Sit with the absurdity of the middle column. Claude Opus 4.6 – a model that scores four points lower at 53 – was still 1.6x cheaper to run than its own successor and 1.6x more expensive than Gemini. The intelligence ranking and the cost ranking are almost orthogonal. Buying the top of the leaderboard is, in cost terms, buying the bottom.
The chart below is the asset to bookmark. The X-axis is the Intelligence Index score; the Y-axis is the USD cost to run the full index on a logarithmic scale. Drop a vertical line at score 57 and you see three points stacked from $892 to $4,406 – same intelligence, 5x cost. That vertical spread is the entire argument for tracking price per intelligence as a first-class metric.
A note on snapshot drift: Artificial Analysis’s live Claude Opus 4.7 model page later showed the cost-to-run figure at $5,117.14 against ~110M output tokens generated, higher than the April $4,406.45 reading. Benchmark versions and token counts shift between runs, which is exactly why you re-pull these numbers rather than memorize them. The 5x-versus-Gemini relationship holds in both snapshots.
Why sticker price misleads: token efficiency
Per-token list pricing only explains part of the cost gap; the rest is token efficiency – how many tokens a model burns to finish a task – and it can swing the real bill by more than 2x even between models with similar sticker prices. List price is the rate; tokens-per-task is the quantity. Your invoice is rate times quantity, and the leaderboard shows you neither.
Start with the published rates. Gemini 3.1 Pro lists at $2 input / $12 output per million tokens. GPT-5.4 sits at $2.50 / $15. Claude Opus 4.7 is $5 / $25 – and Artificial Analysis’s live page blends it to about $4.10 per million across a representative input/output mix. On rate alone, Opus is roughly 2-2.5x Gemini, not 5x. The remaining gap is quantity: reasoning-heavy models like Opus generate far more internal thinking tokens per problem, and the index bills every one of them.
GPT-5.5 is the cleanest demonstration of this mechanic. When OpenAI shipped it in late April 2026, the API price doubled from $2.50/$15 to $5/$30 per million tokens. A naive reading says your costs double. But Artificial Analysis measured the effective increase at only ~20% to run the full index, because GPT-5.5 reaches its answers using roughly 40% fewer output tokens than its predecessor. The price per token doubled; the price per intelligence barely moved.
This is the trap in reverse, too: a model can advertise a low per-token rate and still be expensive if it rambles. The only honest unit is cost-to-finish-the-task, which is precisely what the cost-to-run-the-index column measures.
GPT-5.5’s per-token price doubled to $5/$30, yet the real cost to run the Intelligence Index rose only ~20% because the model spends ~40% fewer output tokens per task. Never read a price-list change as a cost change without the token-efficiency multiplier.
| Model | Input $/1M | Output $/1M | Index score | Cost to run index |
|---|---|---|---|---|
| Gemini 3.1 Pro Preview | $2.00 | $12.00 | 57 | $892.28 |
| GPT-5.4 (xhigh) | $2.50 | $15.00 | 57 | n/a (price ref) |
| Claude Opus 4.6 | $5.00 | $25.00 | 53 | $1,451.04 |
| Claude Opus 4.7 (max) | $5.00 | $25.00 | 57 | $4,406.45 |
| GPT-5.5 (xhigh) | $5.00 | $30.00 | 60.2 | ~20% over GPT-5.4* |
The late-May 2026 frontier shift
By the end of May 2026 the tie broke: Claude Opus 4.8 took the #1 spot at 61.4 on the Intelligence Index, edging GPT-5.5 (xhigh) at 60.2, while older flagships fell behind. Anthropic released Opus 4.8 (Adaptive Reasoning, Max Effort) on May 28, 2026, and it leads GPT-5.5 by 1.2 points on the composite, per Artificial Analysis and OfficeChai.
Crucially, Opus 4.8 attacks its own predecessor’s biggest weakness – cost. Artificial Analysis reports it hits its scores using 15% fewer turns per task and 35% fewer output tokens than Opus 4.7. That is a direct price-per-intelligence improvement: same family, same $5/$25 list price, but a markedly cheaper run because it stops over-thinking. On the agentic GDPval-AA benchmark it posts 1,890 Elo, 121 points clear of GPT-5.5.
The takeaway is not which model is on top this week – that will change again. It is that the price-per-intelligence frontier is moving on the cost axis as aggressively as the capability axis. The labs have figured out that token efficiency is a competitive weapon, and the gap between leaderboard rank and invoice rank is what they are now racing to close.
If you froze a cost model in April based on the 57-way tie, it is already stale: the top score is now 61.4, GPT-5.5 changed the price-list math, and Opus 4.8 changed the token-efficiency math. Re-pull, re-compute.
“The price per token doubled; the price per intelligence barely moved. That sentence is the whole 2026 cost story in one line.”
On GPT-5.5’s pricing change
How to actually buy price per intelligence
The winning move is to stop buying a single model and start routing by task: send routine work to the cheapest model that clears your quality bar, and reserve the expensive max-effort tier only for tasks where the extra points measurably matter. At a 5x cost spread, mis-routing one workload can dwarf every other line in an inference budget.
Concretely, that means three habits. First, price by cost-to-finish-the-task, never by per-token rate alone – build a small internal eval that mirrors your real prompts and measure dollars-per-correct-answer for each candidate model. Second, weight token efficiency as heavily as list price; a model that is 25% pricier per token but 40% terser can be cheaper in practice. Third, re-benchmark on a cadence – every six weeks the frontier moves enough to invert a ranking.
The leaderboard remains useful for one thing: telling you which models are even in contention at all. Among models tied at the top of the capability index, the only rational selection criterion left is price per intelligence. For a tied score, paying 5x is not buying quality – it is buying a number on a slide.
Pros
Cons
The verdict on price per intelligence
Buy the score, not the brand – then buy the cheapest model that holds the score.
For any score-tied set of frontier models, price per intelligence is the deciding metric, and in 2026 it can vary by 5x – so the cheapest model at a given Intelligence Index score is almost always the correct default purchase.
The April snapshot is the proof point that should reset how the industry shops: three models at 57, costing $892, $1,451-ish in the prior generation, and $4,406 to run the same benchmark. The May shift to Opus 4.8 at 61.4 – cheaper to run than 4.7 despite the same list price – shows the labs themselves now treat token efficiency as the real battleground. Read the leaderboard for who is in the race; read the cost-to-run column for who you should actually pay.
Builder’s take
I run Cyntr, an AI orchestration engine that calls frontier models thousands of times a day, and Loomfeed on top of it. The April 2026 index is the clearest data point I have ever seen for a thesis I keep repeating to anyone who will listen: the benchmark score on the box is not the number you pay for.
- The headline composite score and the line item on your invoice are two different numbers, and the gap between them is now 5x at the frontier. Treating the leaderboard as a buying guide is how you 5x your inference bill for zero quality gain.
- Token efficiency is the variable nobody puts on the slide. GPT-5.5 doubled its sticker price and the real cost to run the index went up only ~20% because the model thinks in ~40% fewer output tokens. Sticker price is marketing; tokens-per-task is the bill.
- I route by task, not by brand. In Cyntr the dispatch layer sends cheap-and-good work to the Gemini-class tier and reserves the expensive max-effort tier for the handful of tasks that actually move the score. Most orchestration code still hardcodes one model – that is the single most expensive line in the repo.
- Re-run the math every six weeks. The frontier moved from a 57-tie in April to Opus 4.8 at 61.4 in May. Any cost model you froze in Q1 is already wrong.
Frequently asked questions
Price per intelligence is the dollar cost to reach a given capability score on a fixed benchmark, rather than the per-token list price. Artificial Analysis approximates it with the USD cost to run its full Intelligence Index through each model’s API. In April 2026, three models tied at score 57 but cost from $892.28 to $4,406.45 to run that identical benchmark – a 5x price-per-intelligence spread.
Two reasons stack. First, list price: Opus 4.7 is $5/$25 per million input/output tokens versus Gemini 3.1 Pro at $2/$12, roughly 2x. Second, token efficiency: reasoning-heavy models generate far more thinking tokens per task, multiplying that gap. Together they produced a $4,406.45 vs $892.28 cost to run the same Intelligence Index, both scoring 57.
No. GPT-5.5’s API price doubled from $2.50/$15 to $5/$30 per million tokens, but Artificial Analysis measured the effective cost increase at only about 20% to run the full Intelligence Index. The reason is token efficiency: GPT-5.5 reaches its answers using roughly 40% fewer output tokens than GPT-5.4, so the higher rate is applied to far fewer tokens.
It is a composite benchmark that aggregates ten hard evaluations – including GDPval-AA, Terminal-Bench Hard, SciCode, GPQA Diamond, Humanity’s Last Exam, and IFBench – into a single capability score. Artificial Analysis also publishes the USD cost it spent running the full suite through each model, which is the figure used to compute price per intelligence.
Claude Opus 4.8 (Adaptive Reasoning, Max Effort), released May 28, 2026, took the top spot at 61.4, edging out GPT-5.5 (xhigh) at 60.2. Opus 4.8 also improved its own price per intelligence, reaching those scores with 15% fewer turns and 35% fewer output tokens than Opus 4.7 at the same list price.
Price by cost-to-finish-the-task using an eval that mirrors your real prompts, not by per-token rate alone. Weight token efficiency as heavily as list price, route routine work to the cheapest model that clears your quality bar, reserve the expensive max-effort tier for tasks where extra points matter, and re-benchmark roughly every six weeks because the frontier moves fast.
Primary sources
- Artificial Analysis Intelligence Index April 2026 Explained — Smartchunks
- Claude Opus 4.7 – Intelligence, Performance & Price Analysis — Artificial Analysis
- OpenAI’s GPT-5.5 is the new leading AI model — Artificial Analysis
- Claude Opus 4.8 – The new #1 AI model — Artificial Analysis
- Artificial Analysis Intelligence Index — Artificial Analysis
- Claude Opus 4.8 Tops Intelligence Index With Score Of 61.4 — OfficeChai
- Best AI Models May 2026 Leaderboard — Build Fast with AI
Last updated: June 1, 2026. Related: Products.




