


Cerebras, Groq, SambaNova, Together, Fireworks and Baseten benchmarked on a common open model — with the real tokens-per-second numbers and the caveats that change them.
What is the fastest AI inference provider in 2026?
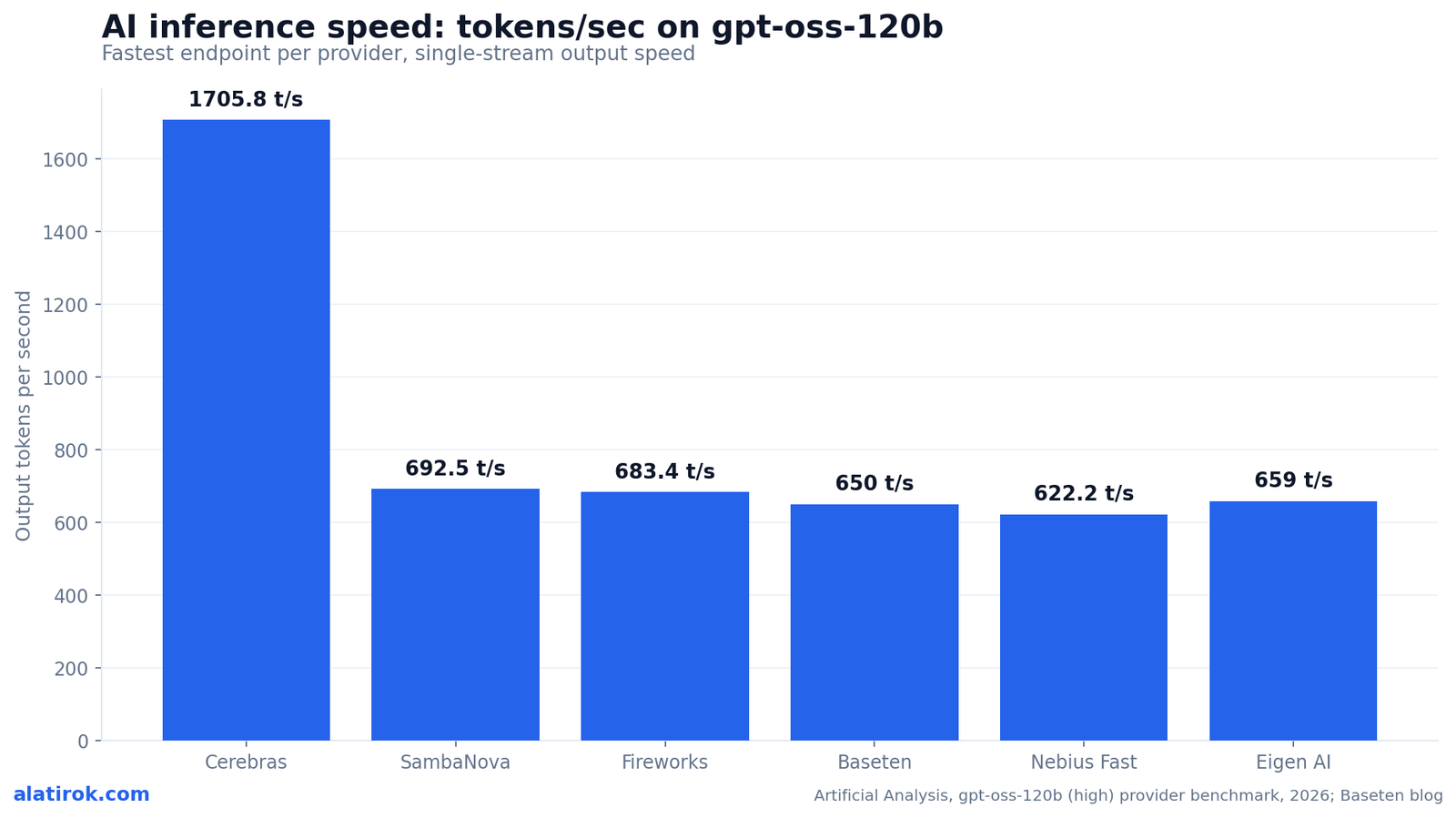
On the most-compared common open model — OpenAI’s gpt-oss-120b — Cerebras is the fastest AI inference provider in 2026, clocking 1,705.8 output tokens per second on Artificial Analysis, more than 2.4x the next-fastest API. Behind it, SambaNova (692.5 t/s) and Fireworks (683.4 t/s) lead a tight chasing pack, with Baseten close at roughly 650 t/s as the fastest NVIDIA-GPU-based option.
That headline hides a more interesting story. The same Artificial Analysis page reports a 39.2x gap between the fastest and slowest providers serving the exact same weights. Two endpoints can run byte-identical model files and deliver wildly different experiences — because AI inference speed is a property of the hardware and serving stack, not the model.
This comparison uses gpt-oss-120b deliberately: it is open-weight, widely hosted, and benchmarked by a neutral third party across more than 20 providers, which makes it the cleanest apples-to-apples test bed available in 2026. Every number below is a single-stream measurement and will shift with model, context length and load — a caveat we return to at the end.

Output tokens per second (t/s) measures how fast a model streams new text in a single request. Roughly, 1 token is about 0.75 of an English word, so 700 t/s is around 525 words per second — far faster than any human reads. Above ~1,000 t/s, the bottleneck stops being the model and starts being your network and application code.
AI inference speed compared: output tokens per second by provider
Across the six providers most associated with fast inference, output speed on gpt-oss-120b ranges from Cerebras at 1,705.8 tokens per second down to GPU-based providers in the 300–700 t/s band. The chart below plots the verified Artificial Analysis figures for the fastest endpoint of each named provider.
Three of these — Cerebras, Groq and SambaNova — run custom silicon (wafer-scale, LPU and RDU respectively) built specifically to stream tokens fast. The other three — Together, Fireworks and Baseten — run optimized stacks on NVIDIA GPUs, and have closed much of the gap through speculative decoding and aggressive kernel work. Baseten, for instance, reports it made its gpt-oss serving 60% faster over ten weeks using EAGLE-3 speculative decoding to reach the ~650 t/s tier.
A note on Groq: on gpt-oss-120b the public Artificial Analysis ranking is led by the custom-silicon and top GPU stacks above, but Groq remains a speed leader on other open models — it posts 306.8 t/s on Llama 3.3 70B, narrowly ahead of SambaNova’s 295.1 t/s on that model. This is exactly why the ranking is model-dependent.
| Provider | Output speed (t/s) | Time to first token | Hardware class |
|---|---|---|---|
| Cerebras | 1,705.8 | 1.66s | Wafer-Scale Engine (custom) |
| SambaNova | 692.5 | sub-1s class | RDU (custom) |
| Fireworks | 683.4 | mid-single-digit s | NVIDIA GPU |
| Baseten | ~650 | mid-single-digit s | NVIDIA GPU (EAGLE-3) |
| Together | not top-5 speed; 4.23s TTFT | 4.23s | NVIDIA GPU |
| Groq (Llama 3.3 70B) | 306.8 on that model | 0.91s | LPU (custom) |
Latency vs throughput: why time to first token matters
Peak tokens per second tells you how fast a model finishes; time to first token (TTFT) tells you how fast it starts — and for chat and agents, the second number often dominates the felt experience. On gpt-oss-120b, Cerebras posts both the highest throughput (1,705.8 t/s) and the lowest latency (1.66s TTFT), a rare double.
Below the leader, the trade-offs sharpen. Together.ai is not in the top tier for raw output speed on this model, yet it lands among the lower-latency providers at 4.23s TTFT — useful context for workloads where the first token’s arrival is what users notice. A provider that streams at 680 t/s but takes 4+ seconds to produce its first token will feel slower in a quick back-and-forth than one that starts in under two.
AI inference speed is really two numbers, so the practical rule splits with them: for long-form generation (reports, code files, batch summarization) optimize for throughput, because most of the wall-clock time is spent streaming. For short, interactive turns — the bulk of agent tool-calls and chat replies — optimize for TTFT, because the response is over before peak throughput ever matters.
“Two endpoints can run byte-identical model weights and deliver a 39x difference in speed. Inference speed is a property of the stack, not the model.”
Artificial Analysis gpt-oss-120b benchmark, 2026
Custom silicon vs GPUs: where the speed actually comes from
1,705.8
Cerebras t/s on gpt-oss-120b
Fastest single endpoint benchmarked by Artificial Analysis
39.2x
Spread fastest-to-slowest
Same model, same weights, different stacks
~650
Baseten t/s on NVIDIA GPUs
Up ~60% in 10 weeks via EAGLE-3 speculative decoding
1.66s
Cerebras time to first token
Lowest TTFT in the gpt-oss-120b field
The fastest AI inference speed in 2026 comes from purpose-built chips that keep the entire model in fast on-chip memory, eliminating the memory-bandwidth bottleneck that throttles GPU inference. Cerebras’ Wafer-Scale Engine is a single dinner-plate-sized chip; Groq’s LPU and SambaNova’s RDU take different routes to the same goal: stop shuttling weights back and forth from external memory on every token.
In Cerebras’ own head-to-head, its WSE ran gpt-oss-120b at over 3,000 t/s in a configuration that beat an eight-GPU NVIDIA GB200 setup — which Baseten benchmarked at around 650 t/s — by roughly 5x, at a modestly higher token price ($0.75 vs $0.50 per million in that test). The architectural advantage is real and repeatable.
But custom silicon has a coverage cost. These vendors host a curated menu of popular open models. The moment you need a specific fine-tune, a quantization they don’t offer, or a brand-new release on day one, you are back on GPU providers — Fireworks, Together and Baseten — whose entire value proposition is flexibility plus increasingly competitive speed. The GPU field’s gains via speculative decoding mean the speed penalty for that flexibility is now far smaller than it was in 2024.
How to choose a fast inference provider
Choose your inference provider by matching its strengths to your workload shape, not by chasing the top of a single leaderboard. The right answer is different for an interactive agent, a batch pipeline, and a cost-sensitive product feature — and it changes again if you need a model the speed leaders don’t host.
Start with three questions: Is my model on a custom-silicon menu? Do I need lowest latency or highest throughput? And what is my real cost-per-task once AI inference speed is priced in? On gpt-oss-120b, blended prices on Artificial Analysis ran from about $0.05 per million tokens (DeepInfra) up to the $0.75 range for the fastest custom-silicon endpoints — so the fastest option is rarely the cheapest, and the cheapest is rarely the fastest.
The pros and cons below summarize where each architecture class makes sense. Use it to shortlist, then run your own prompts: published benchmarks are single-stream snapshots, and your concurrency, context length and prompt mix will move the numbers.
Cerebras
Best for: Real-time agents and latency-critical apps on popular open models
What works
Watch out for
SambaNova
Best for: Teams wanting custom-silicon speed beyond a single vendor’s menu
What works
Watch out for
Fireworks
Best for: Production apps needing speed plus a broad, current model catalog
What works
Watch out for
Baseten
Best for: Teams wanting GPU flexibility with near-custom-silicon speed
What works
Watch out for
Together
Best for: Maximum model coverage and same-day access to new releases
What works
Watch out for
Groq
Best for: Low-latency serving of the specific models Groq optimizes
What works
Watch out for
Pros
Cons
The caveat that breaks every inference benchmark
Cerebras owns raw speed; the right pick still depends on your workload
Every tokens-per-second figure in this article is a single-stream measurement on one model at one moment — change the model, the context length, the concurrency, or the time of day, and the ranking can reorder. This is the single most important thing to internalize before you pick a provider on the strength of a leaderboard.
Three forces move the numbers. Model: Groq tops Llama 3.3 70B but not gpt-oss-120b. Context length: long prompts add prefill time and drag effective throughput down. Load: a single-user benchmark says nothing about how an endpoint behaves at 100 concurrent requests, when batching and queueing change the math entirely. Artificial Analysis publishes its figures precisely because they are standardized — but standardized is not the same as identical to your production traffic.
The discipline is simple: treat published AI inference speed as a claim to verify, never a number to trust. Use public benchmarks like Artificial Analysis to build a shortlist of three or four candidates. Then replay your own prompts, at your own concurrency, measuring your own cost-per-completed-task. The provider that wins the leaderboard and the provider that wins your bill are frequently not the same name.
Published tokens/sec numbers are single-stream snapshots. Before committing, benchmark your real prompt distribution at production concurrency and measure cost-per-task, not just peak speed. The leaderboard winner can lose once your context lengths and load are applied.
Builder’s take
As founder of Cyntr and Loomfeed, I run agent pipelines where latency compounds across dozens of model calls. Here is how I actually read the inference-speed leaderboard:
- Headline tokens/sec is a single-stream number on a single model. The instant you change the model, the context length, or the time of day, the ranking shuffles. Treat any benchmark as a snapshot, not a contract.
- For interactive chat, time-to-first-token matters more than peak throughput. A provider at 650 t/s with a 1.6s TTFT feels snappier than one at 700 t/s with a 4.3s TTFT.
- Custom-silicon speed (Cerebras, Groq, SambaNova) is real, but it only exists for the handful of models those vendors host. If you need a specific fine-tune, GPU providers like Fireworks, Together and Baseten are where you live.
- In multi-step agent loops, raw speed is multiplied by your number of hops. Shaving 400ms per call across a 20-call plan is the difference between a 2-second and a 10-second agent.
- Speed is necessary but not sufficient — I benchmark cost-per-task and output quality on my own prompts before I trust any leaderboard position.
Frequently asked questions
On gpt-oss-120b, the most widely benchmarked common open model, Cerebras is the fastest at 1,705.8 output tokens per second according to Artificial Analysis — more than 2.4x the next-fastest provider. SambaNova (692.5 t/s) and Fireworks (683.4 t/s) follow. Rankings shift by model: Groq leads on Llama 3.3 70B.
It is measured in output tokens per second (t/s) — how fast a model streams generated text in a single request — alongside time to first token (TTFT), which is how long until the first token appears. Throughput matters for long generations; TTFT matters for interactive chat and agents. One token is roughly 0.75 of an English word.
Chips like Cerebras’ Wafer-Scale Engine, Groq’s LPU and SambaNova’s RDU keep the entire model in fast on-chip memory, removing the memory-bandwidth bottleneck that throttles GPU inference. In Cerebras’ own tests it ran gpt-oss-120b about 5x faster than an eight-GPU NVIDIA GB200 setup, though GPU providers have narrowed the gap with speculative decoding.
Usually not. On gpt-oss-120b, blended prices on Artificial Analysis ranged from about $0.05 per million tokens (DeepInfra) up to roughly $0.75 for the fastest custom-silicon endpoints. The fastest option carries a premium, and the cheapest option is rarely the fastest — so you should weigh cost-per-task against speed.
Published figures are single-stream snapshots on one model. Output speed changes with the model (Groq leads Llama 3.3 70B but not gpt-oss-120b), context length (long prompts slow effective throughput), and concurrency or load (a one-user test says nothing about 100 simultaneous requests). Artificial Analysis reports a 39.2x spread across providers on the same model.
Use them to build a shortlist, not to make the final call. Artificial Analysis provides standardized, neutral benchmarks ideal for narrowing to three or four candidates. Then replay your own prompts at your real concurrency and measure cost-per-completed-task, because the leaderboard winner and the provider that minimizes your bill are often different.
Primary sources
- gpt-oss-120b: API Provider Performance Benchmarking & Price Analysis — Artificial Analysis
- Llama 3.3 70B: API Provider Performance Benchmarking — Artificial Analysis
- OpenAI GPT-OSS 120B Benchmarked: NVIDIA Blackwell vs Cerebras — Cerebras
- How we made the fastest GPT-OSS on NVIDIA GPUs 60% faster — Baseten
- Llama3.1 Model Quality Evaluation: Cerebras, Groq, SambaNova, Together, Fireworks — Cerebras
Last updated: May 31, 2026. Related: Products.




