

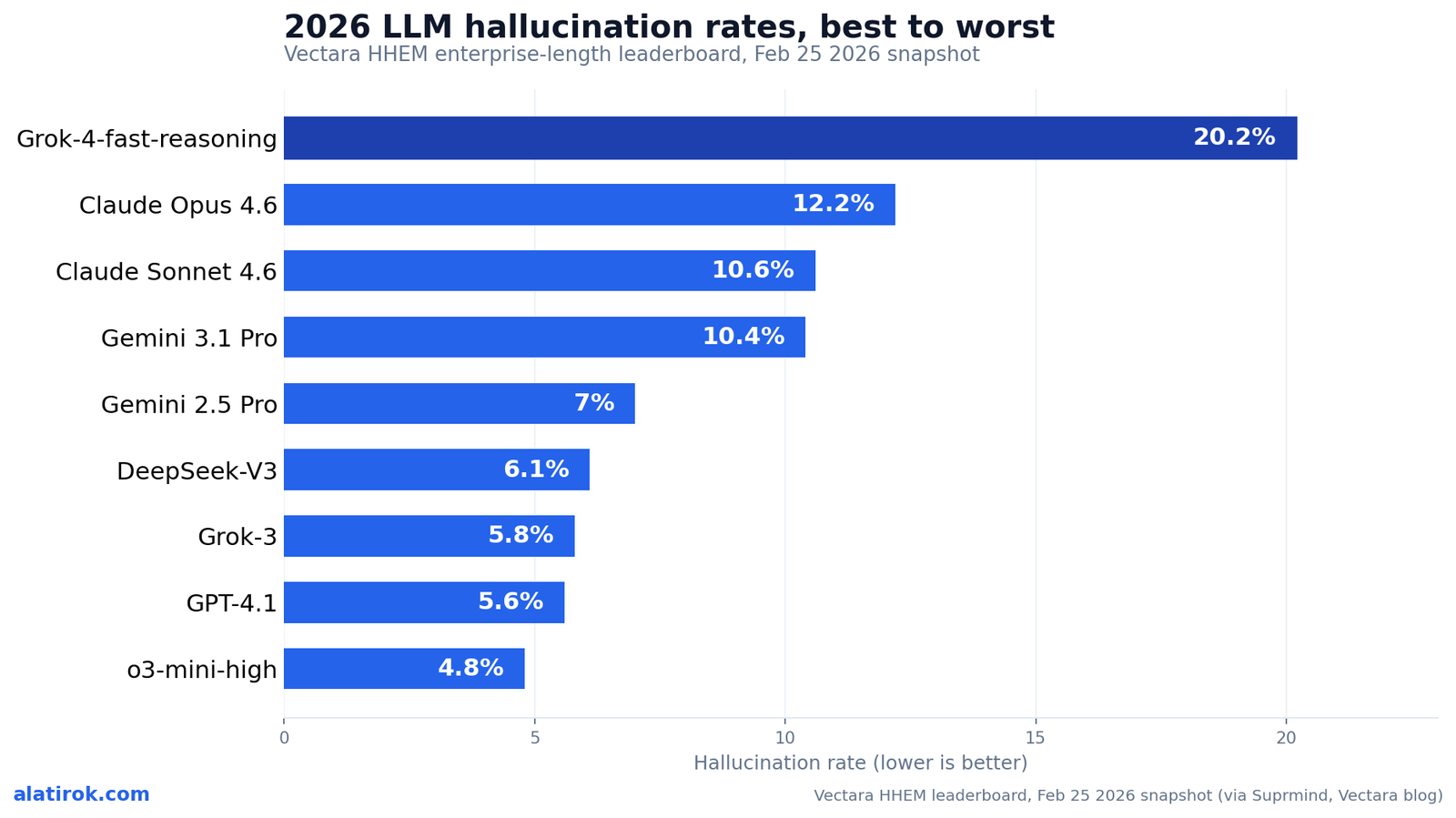
The newest reasoning flagships invent more facts than year-old lightweight models. Here is what the Feb 2026 Vectara HHEM leaderboard actually shows, why it happens, and how to read it without getting fooled.
Which 2026 models invent the fewest facts?
4.8%
Lowest hallucination rate
o3-mini-high, the small reasoning model that leads the board
20.2%
Highest rate on the board
Grok-4-fast-reasoning, a 2026 reasoning flagship
7,700+
Articles in the test set
Up from ~1,000 in the original short-document benchmark
On the February 25, 2026 Vectara HHEM enterprise-length leaderboard, OpenAI’s o3-mini-high invents the fewest facts at a 4.8% hallucination rate, followed by GPT-4.1 at 5.6%, Grok-3 at 5.8%, and DeepSeek-V3 at 6.1% — while several newer, more expensive reasoning flagships land far worse. The single most important pattern in the data is not who wins, but who loses: Claude Opus 4.6, one of the most capable models money can buy in 2026, hallucinates at 12.2%, and Grok-4-fast-reasoning hits 20.2% — more than four times the rate of a small, year-old OpenAI model. These LLM hallucination rates upend a common assumption: newer reasoning-tuned flagships do not automatically invent fewer facts.
This matters because LLM hallucination rates are now a procurement variable, not a research curiosity. If you are building retrieval-augmented generation (RAG), document Q&A, or any pipeline that summarizes source text, the headline benchmark scores you see in launch announcements (MMLU, coding, math) tell you almost nothing about whether the model will faithfully stick to a document you hand it.
The Vectara Hallucination Evaluation Model — HHEM — measures exactly that narrow, high-stakes behavior: grounded faithfulness. It does not ask whether a model knows facts about the world. It asks whether, given a source document, the model’s summary introduces any claim the document does not support. For enterprise software, that is the question that actually predicts production failures.
Grounded hallucination only: how often a model adds unsupported claims when summarizing a document it was explicitly given. It is not a test of world knowledge or trivia accuracy — it is a faithfulness test, which is why it maps so directly onto RAG and document-Q&A reliability.
The 2026 LLM hallucination rates leaderboard, ranked
Sorted best-to-worst, the Feb 25, 2026 HHEM enterprise-length rankings run: o3-mini-high (4.8%), GPT-4.1 (5.6%), Grok-3 (5.8%), DeepSeek-V3 (6.1%), Gemini 2.5 Pro (7.0%), Gemini 3.1 Pro (10.4%), Claude Sonnet 4.6 (10.6%), Claude Opus 4.6 (12.2%), and Grok-4-fast-reasoning (20.2%). The visual below color-codes by provider so the cross-vendor pattern is obvious: this is not one lab’s problem, it is an industry-wide property of the current reasoning-model generation. In other words, LLM hallucination rates track grounding discipline, not raw capability.
Read the chart with one annotation in mind. The two clearly reasoning-tuned flagships in this slice — Claude Opus 4.6 at 12.2% and Gemini 3.1 Pro at 10.4% — both sit below (worse than) the older, cheaper GPT-4.1 at 5.6%. A team that upgraded from GPT-4.1 to Claude Opus 4.6 expecting ‘a better model’ would, on grounded summarization specifically, roughly double its unsupported-claim rate.
Note also the intra-vendor gap. Grok-3 sits at a respectable 5.8%, while Grok-4-fast-reasoning balloons to 20.2% — same lab, newer model, far worse faithfulness. The reasoning variant is the regression. That is the cleanest single illustration in the entire dataset of the counterintuition this article exists to explain.
| Rank | Model | Provider | Hallucination rate | Class |
|---|---|---|---|---|
| 1 | o3-mini-high | OpenAI | 4.8% | Small reasoning |
| 2 | GPT-4.1 | OpenAI | 5.6% | Lightweight (2025) |
| 3 | Grok-3 | xAI | 5.8% | Base |
| 4 | DeepSeek-V3 | DeepSeek | 6.1% | Base |
| 5 | Gemini 2.5 Pro | 7.0% | Flagship | |
| 6 | Gemini 3.1 Pro | 10.4% | Reasoning flagship | |
| 7 | Claude Sonnet 4.6 | Anthropic | 10.6% | Reasoning |
| 8 | Claude Opus 4.6 | Anthropic | 12.2% | Reasoning flagship |
| 9 | Grok-4-fast-reasoning | xAI | 20.2% | Reasoning |
Why reasoning flagships hallucinate more than older lightweight models
Reasoning flagships hallucinate more because they make more claims overall: extended chain-of-thought generates longer, more elaborate answers, and every extra sentence is another opportunity to assert something the source document never said. OpenAI documented this mechanism directly in its own system card — on the PersonQA benchmark, the reasoning model o3 hallucinated on 33% of questions and o4-mini on 48%, versus 16% for the older o1 and 14.8% for o3-mini. OpenAI’s own explanation: the models ‘make more claims overall,’ producing ‘more accurate claims as well as more inaccurate/hallucinated claims.’
The second mechanism is overthinking. On a grounded summarization task, the correct behavior is almost mechanical: extract and compress what the document says, add nothing. Reasoning models are trained to do the opposite — to reason, infer, and fill gaps. That instinct is gold on a math proof and poison on a faithfulness test. Vectara’s researchers describe frontier reasoning models as deviating from source material precisely because they ‘think through’ the answer instead of staying inside the four corners of the document.
Crucially, this is a task mismatch, not a capability deficit. Claude Opus 4.6 is not a ‘worse model’ than GPT-4.1 in any general sense — on reasoning, coding, and agentic tasks it is dramatically stronger. But faithfulness to a provided document is a constraint-satisfaction problem where the optimal policy is restraint, and restraint is the one thing reinforcement-learned reasoning actively trains out. Researchers studying the effect (arXiv 2505.23646) frame it the same way: the reinforcement learning used to make o-series-style models smarter can amplify the very hallucination tendencies that conventional training suppresses.
“On a faithfulness test, the optimal policy is restraint — and restraint is the one thing reinforcement-learned reasoning actively trains out.”
The core mechanism behind the 2026 reasoning-model hallucination gap
What is ‘grounded’ hallucination, and how is it different from getting trivia wrong?
A grounded hallucination is a claim in a model’s output that is not supported by the source document it was given — even if that claim happens to be true in the real world. If a document about a 2025 earnings call never mentions headcount and the summary asserts the company ‘cut 4,000 jobs,’ that is a grounded hallucination regardless of whether the layoff actually happened. World-knowledge benchmarks measure something else entirely. HHEM only cares about faithfulness to the provided text, which is exactly the failure mode that breaks RAG.Why does answer length show up as average summary length on the leaderboard?
Vectara reports average summary length alongside the hallucination rate because length is a confound. A model that writes a two-sentence summary has fewer chances to go off-script than one that writes two paragraphs. Reporting length lets you sanity-check whether a low score reflects genuine faithfulness or just terseness — and lets you see the reasoning-verbosity tax directly in the data.How the HHEM score is actually computed
HHEM scores every model summary on a 0-to-1 faithfulness scale and counts any summary below 0.5 as a hallucination, then runs each model over 7,700-plus articles and reports three numbers: hallucination rate, answer rate, and average summary length. The threshold is the part people miss. A single summary is not partially hallucinated in the leaderboard math — it is binary. Score 0.51 and it counts as clean; score 0.49 and it counts as a hallucination. The published ‘rate’ is the percentage of summaries that fall below the 0.5 line.
The 2026 dataset is what makes the numbers credible and harsh. The original Vectara leaderboard used roughly 1,000 short documents; the next-generation set expands to over 7,700 unique articles running up to 32,000 tokens, spanning ten domains — technology, stocks, sports, science, politics, medicine, law, finance, education, and business — and is deliberately split between straightforward and complex articles to stress-test reliability. This is why the best achievable rate moved up to roughly 3.3%: the test got closer to what a hospital, a law firm, or a finance team actually feeds a model.
The answer rate metric is the quiet third pillar. A model can post a flattering hallucination rate by refusing to summarize hard documents at all — those refusals do not count against it directly, but they show up as a depressed answer rate. Reading hallucination rate and answer rate together is the only honest way to compare two models: a 6% hallucination rate at a 99% answer rate is a different product than 6% at an 80% answer rate.
Because HHEM is binary at 0.5, a model that is mildly unfaithful on many summaries can score the same as one that is wildly unfaithful on fewer. Always pair the headline rate with average summary length and answer rate before drawing conclusions — the single percentage hides the shape of the failures.
Benchmarks disagree, so cross-reference at least two
A model that tops Vectara HHEM will not necessarily top Google’s FACTS Grounding or Galileo’s Hallucination Index, because each benchmark defines hallucination differently and uses a different judge — so the responsible read is to cross-reference at least two before trusting any single ranking. HHEM uses Vectara’s own purpose-built detection model. FACTS Grounding uses an ensemble of judges (GPT-4o, Claude-3.5-Sonnet, and Gemini-1.5-Pro voting together). Galileo’s Hallucination Index historically leaned on a single GPT-4o judge. Same phenomenon, three different rulers.
The ensemble-versus-single-judge distinction is not academic. Research underlying FaithBench and FACTS found that models rate their own outputs roughly 3.23 percentage points higher than outputs from competing providers — a measurable self-preference bias. A leaderboard scored by a single judge from one lab is therefore structurally suspect: it may quietly flatter that lab’s own models. Ensemble judging exists specifically to dilute that bias, which is why FACTS Grounding and HHEM can rank the same models in different orders.
The practical rule for anyone making a buying decision: if two independent benchmarks agree a model is faithful, believe it. If they disagree, do not average them — treat the disagreement itself as the signal. A model that looks great on a single-judge index but mediocre on an ensemble is exactly the case where you should run your own evaluation on your own documents before shipping.
Pros
Cons
What this means for builders shipping RAG in 2026
Pick the faithful model for the grounded step, not the flashy one
If you are shipping retrieval-augmented generation or document summarization in 2026, default to a faithful, lightweight model for the grounded step and reserve reasoning flagships for tasks that genuinely require multi-step inference — because on faithfulness, newer and more expensive is frequently worse. The HHEM data turns a common architecture mistake into a measurable cost: routing every step of a RAG pipeline through your single ‘best’ reasoning model can double or quadruple your unsupported-claim rate versus a cheaper model picked for the job.
Concretely, the leaderboard suggests a tiered architecture. Use a high-faithfulness model — an o3-mini-high or GPT-4.1-class option around 5% — for the grounded extraction and summarization layer, where staying inside the document is the whole job. Escalate to a reasoning flagship only for the steps that actually need reasoning: planning, multi-hop synthesis, tool orchestration. This is not a downgrade; it is matching the policy (restraint vs. inference) to the task.
And instrument the thing. The reason HHEM is useful is that it is a reproducible 0-1 faithfulness check; you can build the same check over your own corpus with an off-the-shelf entailment model and gate deployments on it. Vendor leaderboards are a starting hypothesis about LLM hallucination rates, not a substitute for measuring your own. The teams that win in 2026 are not the ones running the flashiest model — they are the ones who measured faithfulness on their own documents before their users did.
Builder’s take
I run Cyntr, which pumps model-generated summaries into a live feed every few minutes, and Loomfeed, where those summaries face real readers. The Vectara HHEM numbers match exactly what I see in production: the ‘best’ model on a marketing slide is rarely the most faithful one on a grounded task.
- Pick the model for the job, not the leaderboard. For summarization and RAG, a year-old lightweight model often beats this quarter’s reasoning flagship on faithfulness. I default to the faithful model and only escalate to reasoning when the task genuinely needs multi-step logic.
- Reasoning verbosity is a tax. Models that ‘make more claims overall’ produce more sentences to be wrong in. On Cyntr I cap summary length and forbid speculation in the prompt, which cuts unsupported claims more than swapping models does.
- Run your own HHEM-style check before trusting any vendor number. A 0-1 faithfulness score over your own documents is a weekend of work and worth more than every leaderboard combined, because your corpus is not Vectara’s 7,700 articles.
- Cross-reference two benchmarks or trust none. Self-preference bias is real and measurable. If FACTS Grounding and HHEM agree a model is faithful, believe it. If they disagree, the disagreement is the finding.
Frequently asked questions
On the Vectara HHEM enterprise-length leaderboard (Feb 25, 2026 snapshot), OpenAI’s o3-mini-high has the lowest grounded hallucination rate at 4.8%, followed by GPT-4.1 at 5.6%, Grok-3 at 5.8%, and DeepSeek-V3 at 6.1%. These rates apply specifically to summarizing provided documents, not to general world-knowledge accuracy.
Reasoning models generate longer, more elaborate answers, which means they make more claims overall — and every additional sentence is another chance to assert something a source document never said. They are also trained to infer and fill gaps, which is exactly the wrong instinct on a grounded summarization task where the optimal behavior is restraint. OpenAI’s own system card showed its reasoning model o3 hallucinating on 33% of PersonQA questions versus 16% for the older o1.
HHEM scores each model-generated summary on a 0-to-1 faithfulness scale and counts any summary below 0.5 as a hallucination. It runs each model over 7,700-plus articles (up to 32,000 tokens, across ten domains) and reports three numbers: the hallucination rate, the answer rate (how often the model actually produced a summary), and the average summary length.
Only on grounded faithfulness, and only because that task rewards restraint. On the Feb 2026 HHEM leaderboard, Claude Opus 4.6 hallucinates at 12.2% versus GPT-4.1’s 5.6% when summarizing provided documents. On reasoning, coding, and agentic tasks, Claude Opus 4.6 is far stronger. The lesson is to match the model to the task, not to crown one model overall.
No. Vectara HHEM, Google FACTS Grounding, and Galileo’s Hallucination Index each define hallucination differently and use different judges — HHEM uses its own detection model, FACTS Grounding uses an ensemble of GPT-4o, Claude-3.5-Sonnet, and Gemini-1.5-Pro, and Galileo has used a single GPT-4o judge. Because single-judge setups carry measurable self-preference bias (around 3.23 percentage points), the responsible approach is to cross-reference at least two benchmarks before trusting a ranking.
Not for the grounded summarization step. The HHEM data shows lightweight models around 5% beating reasoning flagships at 10-20% on faithfulness. The recommended pattern is a tiered architecture: use a high-faithfulness model for extraction and summarization, and escalate to a reasoning flagship only for steps that genuinely require multi-step inference, such as planning or multi-hop synthesis.
A grounded hallucination is any claim in a model’s output that the provided source document does not support — even if the claim is true in the real world. A factual error is about being wrong about reality. HHEM measures grounded hallucination specifically, which is the failure mode that matters for RAG and document Q&A, where the model is supposed to stay strictly inside the text it was given.
Primary sources
- Introducing the Next Generation of Vectara’s Hallucination Leaderboard — Vectara
- Which AI Hallucinates Least? May 2026 Benchmark Rates Data — Suprmind
- OpenAI’s new reasoning AI models hallucinate more — TechCrunch
- Vectara Hallucination Leaderboard (GitHub) — Vectara / GitHub
- LLM Hallucination Rates 2026: Best and Worst Models — ModelsLab
- Are Reasoning Models More Prone to Hallucination? — arXiv
Last updated: June 1, 2026. Related: Observability.




