

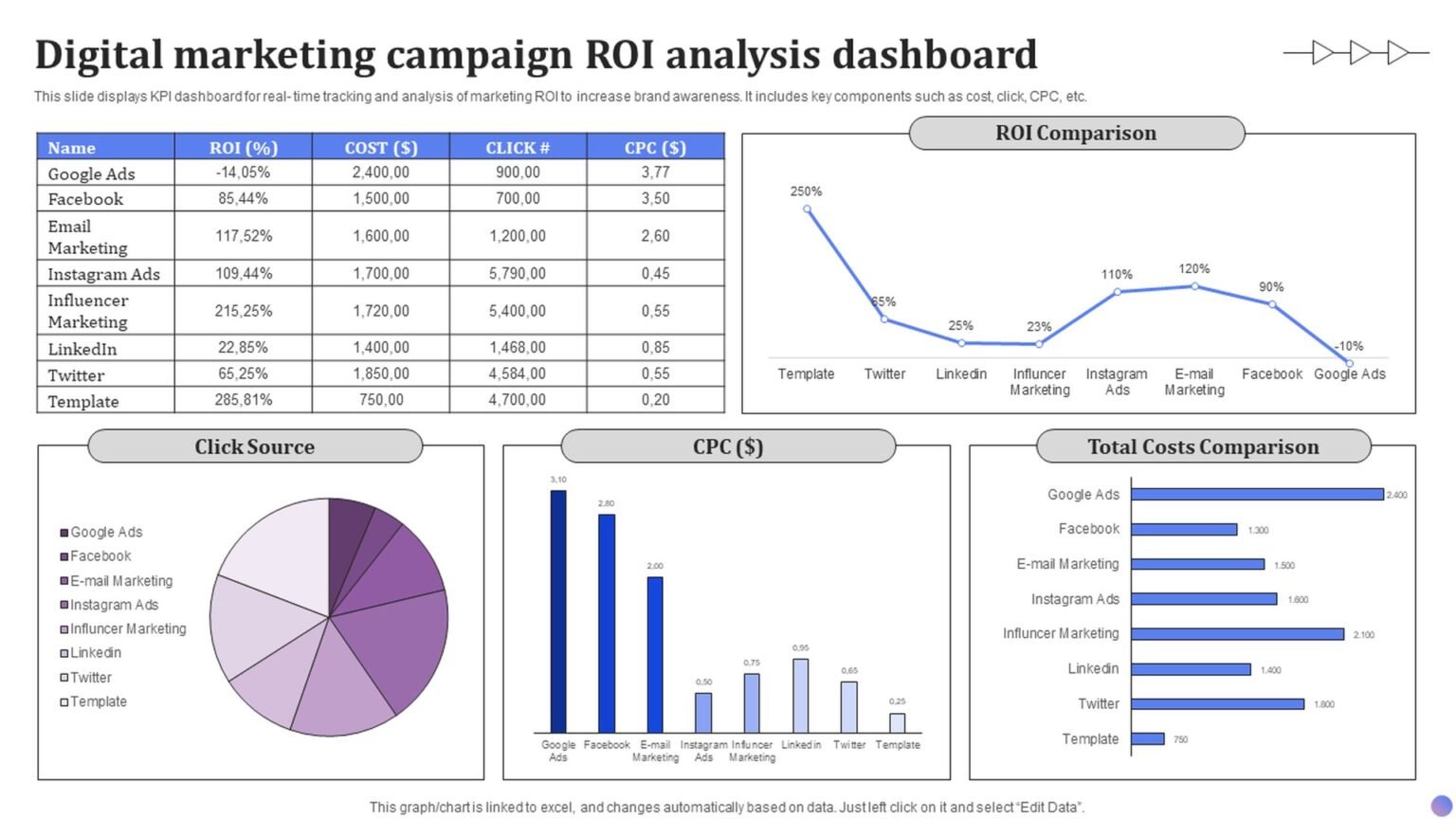
Anticipated returns near 170 percent collide with a 95 percent pilot-failure rate. Here is the ROI framework, the cost and value inputs, and the metrics that actually hold up in a 2026 finance review.
What is agentic AI ROI and why is it so hard to measure in 2026?
Agentic AI ROI is the realized financial return from autonomous, multi-step AI workflows after you subtract their full cost of ownership, and it is hard to measure because the cost side is unmetered and the value side is over-claimed. Unlike a SaaS seat with a fixed price, an agent’s cost moves with every run, and its value shows up indirectly as deflected work or faster cycles rather than as a clean invoice line.
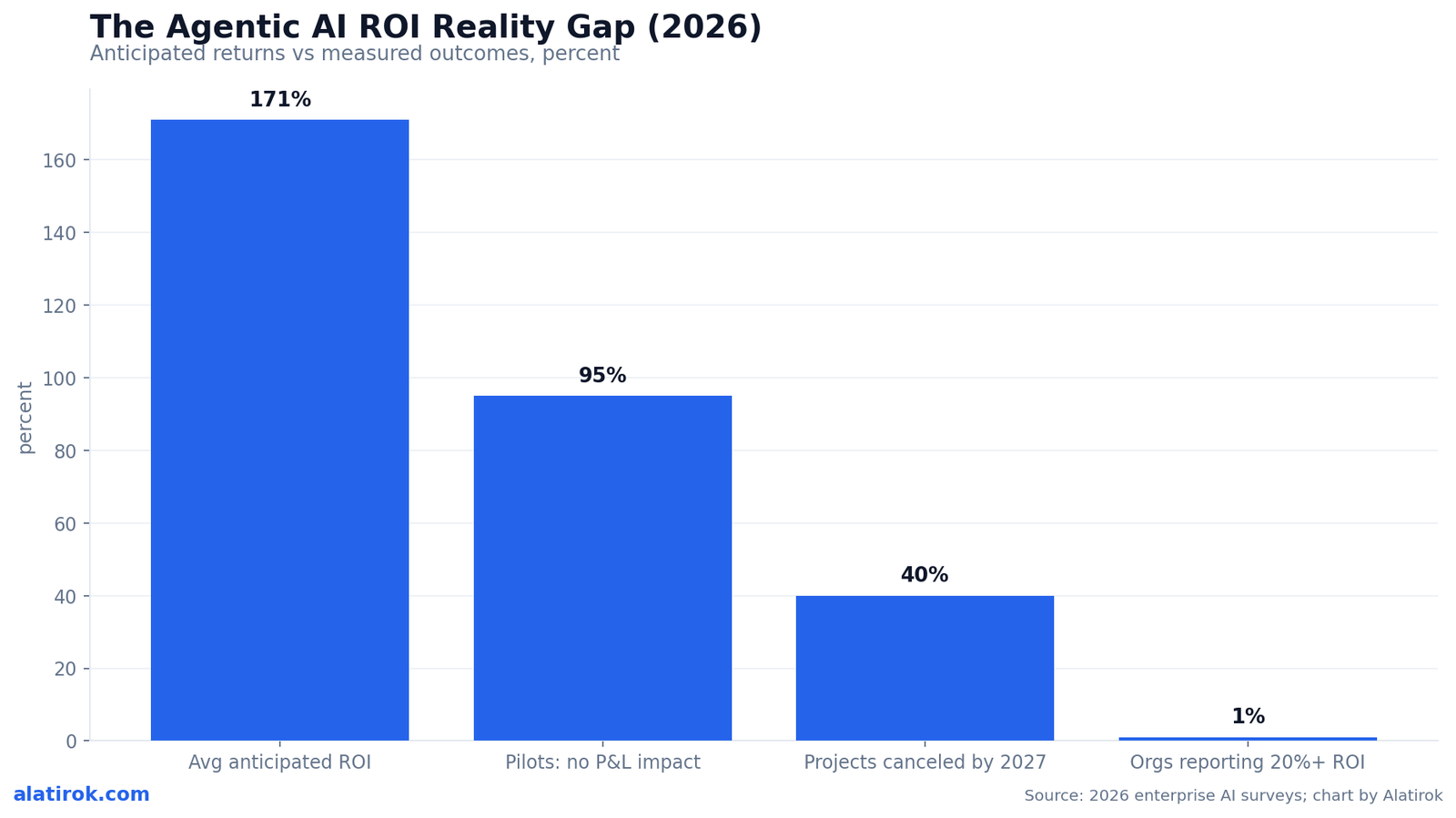
The headline numbers expose the tension. A PagerDuty survey of 1,000 IT and business executives found that more than three in five decision-makers expect agents to return over 100 percent, with the average anticipated return near 171 percent and U.S. firms closer to 192 percent, per CIO Dive. Those are forecasts, not results. On the realized side, Deloitte’s enterprise research reports that while over 70 percent of organizations claim positive AI ROI, fewer than 1 percent report a significant return of 20 percent or more, with most landing in the 1 to 5 percent range, often measured as soft productivity rather than hard P&L.
That gap between expectation and outcome is what a CFO is paid to interrogate. The honest version of agentic AI ROI in 2026 is not a single percentage; it is a defensible bridge from a documented baseline to a realized outcome, net of token spend, infrastructure, build, oversight, and error remediation. Everything in this article is built to make that bridge survive cross-examination.
How bad is the pilot-to-production gap, and what does the data say?
171%
Average anticipated agentic AI ROI
PagerDuty survey of 1,000 executives; expected, not realized
95%
GenAI pilots with no measurable P&L impact
MIT NANDA, GenAI Divide 2025
40%+
Agentic AI projects forecast to be canceled by 2027
Gartner, poll of 3,400+ organizations
<1%
Organizations reporting 20%+ AI ROI
Deloitte enterprise AI research
The pilot-to-production gap is severe: most agentic and generative AI pilots never produce a measurable financial return, and roughly 40 percent of agentic AI projects are forecast to be canceled outright. The optimism in the boardroom is real, but so is the failure rate, and a CFO review starts from the failure rate.
MIT’s NANDA initiative, in The GenAI Divide: State of AI in Business 2025, found that about 95 percent of generative AI pilots delivered little to no measurable P&L impact despite an estimated $30 to $40 billion in enterprise spend, as reported by Fortune. Buying from specialized vendors succeeded around 67 percent of the time versus roughly 33 percent for internal builds. Gartner, polling more than 3,400 organizations, predicts over 40 percent of agentic AI projects will be canceled by the end of 2027 due to escalating costs, unclear business value, or inadequate risk controls, and warns of widespread ‘agent washing.’
The takeaway for finance is not that agentic AI does not work. It is that value concentrates in a narrow band of well-instrumented deployments. The 5 percent that succeed share a pattern: a clear baseline, a single owned outcome, and a cost ledger that the finance team can audit.
The agentic AI ROI framework: cost inputs and value inputs
A defensible agentic AI ROI framework has two ledgers: a total-cost-of-ownership ledger with five inputs (tokens, infrastructure, build, oversight, error remediation) and a value ledger with three inputs (cycle-time, deflection, revenue). ROI is then realized value minus total cost, divided by total cost, measured over a fixed window against a baseline you captured before launch.
The cost side is where most pilots quietly bleed. Token and inference spend is variable and scales with usage; The SaaS CFO notes inference can average roughly a quarter of AI product cost at scale. But the line items finance forgets are oversight (the human-in-the-loop review time that does not disappear) and error remediation (the cost of correcting an agent’s wrong actions). Independent 2026 analyses peg evaluation and integration at 28 to 44 percent of total agent program cost in mature deployments, which is why a pilot that looked cheap can fail review at scale.
On the value side, map each input to something your CFO already books. Cycle-time becomes hours saved at a loaded labor rate; deflection becomes resolved tickets or qualified leads at a known cost-per-unit; revenue becomes influenced or accelerated bookings. The table below is the full input list to instrument before you claim a number.
If you did not measure the metric before the pilot, you cannot prove the pilot moved it. Capture mean time to resolution, cost per unit of work, and error rate for the existing process first. The most common reason agentic AI ROI collapses in a CFO review is a missing baseline, not a missing benefit. Companies that set baselines and assign a business owner before deployment reach positive ROI roughly 2.4x faster, per 2026 deployment analyses.
| Ledger | Input | What to capture | Common trap |
|---|---|---|---|
| Cost | Tokens / inference | Input and output tokens per run, by model tier | Quoting pilot-volume pricing that breaks at scale |
| Cost | Infrastructure | Orchestration, retrieval, vector DB, observability | Treating it as fixed; it scales with agent count |
| Cost | Build | Engineering hours to design, integrate, and evaluate | Excluding eval and integration (28-44% of program cost) |
| Cost | Oversight | Human review and approval time per agent action | Assuming the human cost goes to zero |
| Cost | Error remediation | Rework hours, escalations, reversed actions | Booking it as an exception, not a recurring line |
| Value | Cycle-time | Mean time to resolution before vs. after | No pre-pilot baseline, so no subtraction possible |
| Value | Deflection | Tasks resolved autonomously at a known cost-per-unit | Counting volume without a quality check (CSAT, returns) |
| Value | Revenue | Bookings influenced or accelerated, attributed | Claiming 100% attribution for a multi-touch deal |
Which agentic AI ROI metrics do CFOs trust, and which are vanity?
CFOs trust metrics that connect consumption to a verified business outcome: cost per resolved unit, gross margin per work unit, realized payback period, and quality-adjusted resolution rate. They discount vanity metrics like seats, daily active users, and raw token counts to roughly zero. The dividing line is whether a metric proves work happened and money moved, or merely that access exists.
The SaaS CFO’s four-layer model is the cleanest lens: consumption (tokens, calls), work (records updated, tickets handled), outcomes (resolved, qualified, closed), and business impact (hours saved, cost avoided, revenue influenced). A number that lives only in layer one or two is operational telemetry, not ROI. Salesforce’s ‘Agentic Work Unit’ (a record updated, workflow triggered, or decision made) is an attempt to give layer two a unit, but on its own it still does not prove value reached layer four.
InformationWeek captures why the old playbook fails: Gartner’s Anushree Verma argues traditional efficiency metrics like headcount reduction and time savings ‘cannot capture the unique cost and value dynamics of AI-agent-powered workflows,’ and advises CIOs to ‘move away from opaque vendor-supplied measures and focus on financial gains that matter most to business leaders.’ BCG X’s Matt Kropp is blunter, noting most agent-based solutions ‘deliver very little ROI.’ Strategic metrics that hold up include capital velocity, time-to-value, and mean time to resolution measured in money.
Cost per resolved unit
Best for: Support deflection, lead qualification, back-office automation
What works
Watch out for
Realized payback period
Best for: Capital approval and renewal decisions
What works
Watch out for
Quality-adjusted resolution rate
Best for: Customer-facing agents
What works
Watch out for
Token count / seats / DAUs
Best for: FinOps cost control only, never ROI claims
What works
Watch out for
A worked agentic AI ROI example a CFO would actually approve
Here is a 90-day support-deflection agent worked end to end: the realized agentic AI ROI is about 86 percent, with payback in roughly 6.5 months, once you subtract full TCO including oversight and error remediation. Notice the number is well below the 171 percent anticipated benchmark, and that honesty is exactly what makes it credible in review.
The setup: a Tier-1 support team handles 20,000 tickets a month at a fully loaded human cost of about $7.00 per ticket. The agent autonomously resolves 35 percent of them (7,000 tickets) at a quality-adjusted resolution rate verified against CSAT, so we only count clean resolutions. The remaining tickets still route to humans. We measured cost-per-ticket and mean time to resolution for a full month before turning the agent on.
The math below is intentionally conservative: it counts oversight as a real recurring cost and books a remediation line for the agent’s wrong resolutions. The value is deflection only; we deliberately exclude any revenue-influence claim because attribution would not survive scrutiny. That discipline is the difference between a number the CFO approves and a number they veto.
The 86 percent realized figure beats the 171 percent forecast precisely because it includes the costs the forecast hid. When you bring oversight and remediation onto the ledger yourself, the CFO has nothing left to discount. A clean 86 percent you can defend funds the next phase; an unverifiable 171 percent gets the whole program frozen pending an audit.
AGENTIC AI ROI — 90-DAY WORKED EXAMPLE (support deflection)
BASELINE (captured pre-pilot)
Tickets/month ................... 20,000
Fully loaded human cost/ticket .. $7.00
Quality bar ..................... CSAT >= pre-pilot avg
VALUE (per month)
Clean autonomous resolutions .... 7,000 (35% deflection, QA-adjusted)
Avoided human cost .............. 7,000 x $7.00 = $49,000
Quarterly avoided cost .......... $49,000 x 3 = $147,000
COST — TOTAL COST OF OWNERSHIP (per quarter)
Tokens / inference .............. $21,000
Infrastructure (orchestration,
retrieval, observability) ..... $12,000
Build (amortized over 4 qtrs) ... $20,000
Human oversight (review queue) .. $14,000
Error remediation (rework on
wrong resolutions) ............ $12,000
---------------------------------------------
Total quarterly cost ............ $79,000
REALIZED ROI
(Value - Cost) / Cost
= ($147,000 - $79,000) / $79,000
= $68,000 / $79,000
= ~86% quarterly return
Payback period .................. ~6.5 months (incl. one-time build)
CONTRAST
Vendor 'anticipated' ROI ........ 171%
Realized, full-TCO ROI .......... ~86%
>>> The delta IS the CFO review.What actually survives a CFO review of agentic AI ROI?
The metrics that survive: cost per resolved unit and realized payback, against a real baseline
What survives is a single owned outcome, a pre-pilot baseline, full-TCO costing including oversight and remediation, a quality-adjusted unit metric, and a realized payback period reported against a fixed window. What does not survive is vendor-supplied anticipated ROI, raw token or seat counts, and productivity uplift with no baseline to subtract from.
The 2026 evidence converges on one conclusion: the technology is rarely the failure point. Gartner, MIT, and Deloitte all attribute the dominant failure mode to organizational and measurement gaps, not model quality. Deloitte’s research notes agentic AI is ‘scaling faster than guardrails,’ and that enterprises frequently deploy agents where simpler tools would do, then book negative ROI when remediation piles up. The 5 percent that win instrument cost before value and own one number.
For finance leaders, the operating instruction is simple. Refuse to fund or renew on an anticipated percentage. Require a baseline, a TCO ledger, and a realized payback figure measured over 90 days. If a team cannot produce those three artifacts, you are not looking at an ROI problem, you are looking at a measurement problem, and measurement problems are the ones Gartner expects to cancel 40 percent of these projects.
“Bring oversight and remediation onto your own ledger, and the CFO has nothing left to discount. The honest 86 percent funds the next phase; the unverifiable 171 percent freezes the program.”
Surya Koritala, founder of Cyntr and Loomfeed
Builder’s take
I run Cyntr, an agent orchestration runtime, and Loomfeed, so I sit on both sides of this table: I build the agents that consume tokens, and I have to justify their cost to people who think in payback periods. The single biggest reason agentic AI ROI dies in review is that nobody captured a baseline before the pilot, so there is nothing to subtract the new cost from.
- Instrument the cost side before you instrument the magic. At Cyntr the per-run ledger (tokens, tool calls, retries, escalations) shipped before any value dashboard, because a CFO can disprove your value claim but they cannot argue with your bill.
- Pick one metric that maps to a line item your CFO already tracks, like cost per resolved ticket or cost per qualified lead. ‘Productivity uplift’ is not a line item and will be discounted to zero in review.
- Budget for error remediation as a first-class cost, not a surprise. Every autonomous action an agent takes is a future correction someone may have to make. We meter escalation rate and rework hours the same way we meter inference spend.
- Treat the 171 percent figure as a hypothesis, not a result. Run a 90-day window with a hard baseline and report realized payback, not the deck number your vendor handed you.
Frequently asked questions
There is no single ‘good’ number, but realized full-TCO returns in the 50 to 100 percent range over 12 months are strong and defensible. Be skeptical of the widely cited 171 percent average from the PagerDuty survey, because that figure is anticipated ROI from executive expectations, not realized results, and Deloitte’s data shows fewer than 1 percent of organizations report a return above 20 percent.
They fail mainly for organizational and measurement reasons, not technical ones. MIT found 95 percent of generative AI pilots had no measurable P&L impact, and Gartner expects over 40 percent of agentic AI projects to be canceled by 2027 due to escalating costs, unclear value, and weak risk controls. The most common specific cause is no pre-pilot baseline, so teams cannot prove the agent moved anything.
Five: token and inference spend, infrastructure (orchestration, retrieval, observability), build and integration, human oversight, and error remediation. Teams routinely forget oversight and remediation, which together can dominate cost at scale. Evaluation and integration alone can run 28 to 44 percent of total program cost in mature deployments.
Seats, daily active users, and raw token counts are vanity metrics because they show access and consumption rather than work or outcomes. CFOs discount them to near zero. Even resolution volume is a vanity metric unless it is quality-adjusted with a signal like CSAT, repeat-contact rate, or returns.
Agentic AI takes autonomous, multi-step actions, so its cost is variable per run and it generates a new cost category: error remediation for wrong actions. Gartner notes traditional efficiency metrics like headcount reduction cannot capture these dynamics, pushing CFOs toward outcome metrics like cost per resolved unit, mean time to resolution in money, and capital velocity.
Use a fixed window, typically 90 days, measured against a baseline captured before the pilot launched. Report a realized payback period rather than a percentage taken from a vendor deck. Analyses in 2026 found only about 41 percent of agent rollouts cross positive ROI within 12 months and 19 percent never reach payback, so a defined window keeps the claim honest.
Primary sources
- Gartner: Over 40% of Agentic AI Projects Will Be Canceled by End of 2027 — Gartner
- MIT report: 95% of generative AI pilots at companies are failing — Fortune
- Enterprises have high ROI hopes for agentic AI (PagerDuty survey) — CIO Dive
- Agentic AI has a value gap and old ROI models won’t close it — InformationWeek
- The Four Layers of AI Measurement: A CFO’s Framework — The SaaS CFO
- Agentic AI is scaling faster than guardrails — Deloitte Insights
Last updated: May 31, 2026. Related: Capital.




