


Crossing 200K or 512K tokens can double your entire bill, not just the overflow. Here is the 2026 surcharge-threshold matrix, the breakeven math, and who quietly fixed it.
What is the LLM long-context pricing surcharge in 2026?
The LLM long context pricing surcharge 2026 is a threshold-triggered price multiplier — when a single request’s token count crosses a provider’s line (most commonly 200K or 512K tokens), the higher per-million rate applies to the entire request, not just the tokens above the line. That is why a prompt one token over the threshold can cost roughly double a prompt one token under it. This piece maps long-context pricing surcharge in practical terms.
This is the single mechanic that generic pricing tables miss. Most pages list one input rate and one output rate per model and stop there. But for several frontier models there are two rate tiers, and which tier you pay is decided by your prompt length on a per-call basis. A retrieval step that pulls in three extra documents, a conversation that grows one turn too long, a PDF that tokenizes heavier than expected — any of these can push you over and re-price the whole call.
The damage is worse than the headline 2x suggests, because the multiplier sweeps up costs you did not think were variable. On Google‘s Gemini, crossing 200K input tokens re-rates both input and output for the request. On MiniMax’s M3, crossing 512K re-rates input, output, and cache reads — so the cheap cached prefix you carefully built suddenly bills at double too. The surcharge does not care that 480K of your 520K tokens were cache hits.
The good news for 2026: the landscape just shifted in buyers’ favor at the top end. Anthropic eliminated its long-context surcharge entirely in March 2026, making Claude‘s 1M-token window flat-priced. The bad news: OpenAI moved the other way, introducing a long-context tier on its GPT-5.5 and GPT-5.4 models. If your cost model still assumes ‘Claude is expensive past 200K, OpenAI never surcharges,’ it is now backwards on both counts.

The surcharge is a step function applied to the whole request — crossing the threshold by a single token re-prices every token in the call (and on MiniMax, your cache reads too), not just the overflow.
Long context surcharge threshold matrix: who charges what in 2026
As of June 2026, three of the four major Western/Chinese frontier providers apply a length-based surcharge — Google (above 200K), OpenAI (above 272K), and MiniMax (above 512K) — while Anthropic is the one provider that removed its cliff. The table below is the reference most pricing pages do not give you: not just the rate, but the threshold, the multiplier, whether it hits the whole request, and the current status.
Read the ‘applies to whole request?’ column carefully — it is the line item that wrecks budgets. A ‘yes’ means your breakeven calculation has to compare the full request at the high rate against the full request at the low rate, plus the cost of any restructuring (chunking, caching) you do to stay under. A model where the surcharge only applied to overflow tokens would barely move your budget; none of the surcharged models here work that way.
Note the asymmetry in multipliers. Gemini doubles both input and output (2x / 2x effectively, $1.25→$2.50 and $10→$15 — output is 1.5x). OpenAI’s GPT-5.5 doubles input but applies 1.5x to output ($5→$10 input, $30→$45 output). MiniMax doubles everything, including cache reads, the only provider in the matrix to surcharge cached tokens. These differences change which model is cheapest at a given prompt size — see the breakeven section below.
| Model | Surcharge threshold | Standard input / output | Long-context input / output | Applies to whole request? | Status |
|---|---|---|---|---|---|
| Claude Opus 4.7 / Sonnet 4.6 (Anthropic) | None (1M flat) | $5.00 / $25.00 (Opus); $3.00 / $15.00 (Sonnet) | Same — no surcharge | N/A | Surcharge eliminated Mar 13, 2026 |
| Gemini 2.5 Pro (Google) | > 200K input tokens | $1.25 / $10.00 | $2.50 / $15.00 | Yes | Active |
| GPT-5.5 (OpenAI) | > 272K input tokens | $5.00 / $30.00 | $10.00 / $45.00 | Yes (full session) | Active (new in 2026) |
| GPT-5.4 (OpenAI) | > 272K input tokens | $2.50 / $15.00 | $5.00 / $22.50 | Yes (full session) | Active |
| MiniMax M3 | > 512K tokens | $0.60 / $2.40 (cache $0.12) | $1.20 / $4.80 (cache $0.24) | Yes — incl. cache reads | Active |
Does Claude charge more over 200K tokens in 2026?
No — as of March 13, 2026, Anthropic eliminated the long-context surcharge, so Claude Opus 4.7 and Sonnet 4.6 bill the full 1M-token context window at standard rates with no premium above 200K. This is the single biggest 2026 change to the long-context cost map, and it is the reason most pricing articles you will find are now wrong about Claude.
Here is what changed. Before March 2026, Claude’s 1M-token context was a beta tier (on Sonnet 4.5) that triggered a 2x input / 1.5x output surcharge above 200K tokens — and crucially, that surcharge applied to the whole request. Sonnet’s standard $3 / $15 became $6 / $22.50 the moment a prompt crossed 200K. A 220K-token call was not billed at $3 for the first 200K and $6 for the last 20K; it was billed at $6 for all 220K. That is the classic cliff, and Anthropic ran it for most of the 1M beta period.
On March 13, 2026, Anthropic promoted the 1M window to general availability on Opus 4.6 and Sonnet 4.6 (and the line continues through Opus 4.7) at standard pricing, deleting the surcharge tier entirely. Today a 900K-token Claude call costs the same per token as a 90K-token call. For document-heavy and repo-scale workloads, that quietly made Claude one of the more predictable long-context options — the price line is flat, not a staircase.
Practical takeaway for FinOps owners: if your cost dashboards or internal calculators still apply a 200K Claude surcharge, remove it. You are over-provisioning budget and possibly steering traffic away from Claude for long-context tasks on outdated math. Verify against Anthropic’s live pricing page, because beta-era numbers are still cached all over the web.
“A 900K-token Claude call now costs the same per token as a 90K-token call. Anthropic deleted the cliff; OpenAI built one.”
Alatirok analysis of 2026 frontier pricing
Gemini long context pricing above 200K and OpenAI’s new 272K tier
Gemini 2.5 Pro still applies a long-context surcharge above 200K input tokens — input rises from $1.25 to $2.50 per million and output from $10 to $15, applied to the entire request — while OpenAI’s GPT-5.5 newly added a tier that doubles input above 272K tokens. Google kept its cliff; OpenAI quietly introduced one. Both now matter.
On Gemini, the rule is unambiguous: if your input context is longer than 200K tokens, all tokens — input and output — are billed at the long-context rate. A 199K-token prompt and a 201K-token prompt are priced very differently per token. Context caching is not available on that long-context tier either, so you cannot lean on cache discounts to soften the jump the way you can elsewhere. For workloads that hover near 200K, the practical move is to keep prompts deliberately under the line or commit fully to the larger window and budget for the higher rate.
OpenAI is the freshness landmine. For years the correct advice was ‘OpenAI applies no length-based surcharge at any context length,’ and many 2024-2025 cost guides still say exactly that. In 2026 it is no longer true. The GPT-5.5 and GPT-5.4 models on OpenAI’s own pricing page now list separate short-context and long-context rates: GPT-5.5 goes from $5 / $30 to $10 / $45 once input exceeds roughly 272K tokens, and GPT-5.4 from $2.50 / $15 to $5 / $22.50. The long-context rate applies to the full session, not just the overflow — the same whole-request mechanic as Gemini.
Why 272K and not 200K? OpenAI’s models carry a ~1.05M-token window, and the threshold sits at 272K input tokens — a higher line than Gemini’s 200K, which gives GPT models more runway before the cliff. But once you cross it on GPT-5.5, the input rate is steep ($10/M), so the higher threshold does not automatically make OpenAI cheaper at very long contexts. Run the numbers for your specific prompt size; do not assume the older ‘no surcharge’ rule still holds.
If a 2025 cost guide tells you OpenAI never surcharges long prompts, it is out of date. GPT-5.5 and GPT-5.4 both carry a long-context tier above 272K input tokens as of 2026.
Why is my long prompt billed double? A worked ‘one token over the cliff’ example
Your long prompt is billed double because the surcharge re-prices the entire request the instant you cross the threshold — so a 200,001-token Gemini call costs roughly 2x a 200,000-token call, even though only one token pushed it over. Walk through the numbers and the cliff becomes obvious.
Take Gemini 2.5 Pro. Suppose you send a 200,000-token input and get a 5,000-token output. Under the line, input bills at $1.25/M and output at $10/M: input is 0.200M × $1.25 = $0.25, output is 0.005M × $10 = $0.05, total $0.30. Now add a single token of input — 200,001 tokens. You are over 200K, so the whole request re-prices to the long-context tier: input at $2.50/M, output at $15/M. Input becomes ~0.200M × $2.50 = $0.50, output becomes 0.005M × $15 = $0.075, total $0.575. One extra token nearly doubled the bill, from $0.30 to about $0.58.
MiniMax M3 shows the cache-read trap. Imagine a 510K-token call where 480K tokens are a cached prefix (cache reads at $0.12/M), 30K is fresh input ($0.60/M), and output is 10K ($2.40/M). Cost: 0.480M × $0.12 + 0.030M × $0.60 + 0.010M × $2.40 = $0.0576 + $0.018 + $0.024 ≈ $0.10. Now the prompt grows to 515K — over 512K. Everything doubles, including cache reads: 0.485M × $0.24 + 0.030M × $1.20 + 0.010M × $4.80 ≈ $0.116 + $0.036 + $0.048 = $0.20. The call doubled, and the part that doubled hardest was the cache you built to save money.
The lesson is structural, not arithmetic: treat the threshold as a hard budget boundary, not a soft slope. Instrument your token counts before the call, alert when a request is within ~5% of a threshold, and decide deliberately whether to chunk, trim, or accept the surcharge. A request that drifts over the line by accident — because a retriever returned one document too many — is the most common cause of a surprise double bill.
# Detect the long-context cliff BEFORE you send the request.
# Each provider re-prices the WHOLE request once you cross its threshold.
PRICING = {
# threshold is on INPUT tokens; rates are USD per token
"gemini-2.5-pro": {
"threshold": 200_000,
"under": {"in": 1.25e-6, "out": 10.0e-6},
"over": {"in": 2.50e-6, "out": 15.0e-6},
},
"gpt-5.5": {
"threshold": 272_000,
"under": {"in": 5.0e-6, "out": 30.0e-6},
"over": {"in": 10.0e-6, "out": 45.0e-6},
},
"minimax-m3": { # threshold is on TOTAL tokens, surcharge hits cache too
"threshold": 512_000,
"under": {"in": 0.60e-6, "out": 2.40e-6, "cache": 0.12e-6},
"over": {"in": 1.20e-6, "out": 4.80e-6, "cache": 0.24e-6},
},
"claude-opus-4.7": { # no surcharge since Mar 2026 — flat
"threshold": None,
"under": {"in": 5.0e-6, "out": 25.0e-6},
},
}
def estimate_cost(model, input_tokens, output_tokens, cache_tokens=0):
p = PRICING[model]
over = p["threshold"] is not None and input_tokens > p["threshold"]
rate = p["over"] if over else p["under"]
billable_in = input_tokens - cache_tokens
cost = billable_in * rate["in"] + output_tokens * rate["out"]
if cache_tokens and "cache" in rate:
cost += cache_tokens * rate["cache"]
return round(cost, 4), ("LONG-CONTEXT" if over else "standard")
# One token over the Gemini cliff ~doubles the bill:
print(estimate_cost("gemini-2.5-pro", 200_000, 5_000)) # (0.3, 'standard')
print(estimate_cost("gemini-2.5-pro", 200_001, 5_000)) # (0.575, 'LONG-CONTEXT')Chunk vs long context breakeven: when does the surcharge make splitting worth it?
Chunking beats a single long-context call whenever the surcharge multiplied across your full request exceeds the cost of re-sending shared context in smaller calls — which, past the threshold, is almost always, unless the task needs global attention across the whole document. The chart below maps the cost-versus-prompt-size curves so you can see the cliff and pick a strategy.
The decision has three moving parts. First, the surcharge size: a 2x whole-request multiplier (Gemini, MiniMax) makes the case for chunking much stronger than a tier that only nudges output. Second, the duplication cost: if two chunks share a 50K-token instruction prefix, you pay for that prefix twice — unless you cache it. Third, the task: summarization, extraction, and per-section Q&A chunk cleanly; needle-in-a-haystack retrieval across the entire corpus and cross-document reasoning do not, because splitting destroys the global attention that justified the big window in the first place.
A simple rule of thumb for surcharged models: if your prompt would land between 1.0x and ~1.5x of the threshold, split it. A 250K-token Gemini task (1.25x of 200K) re-prices everything to the high tier; two 130K-token calls stay under the line and, even after re-sending a shared prefix, usually come out cheaper. Past roughly 2-3x the threshold, the duplication overhead and the latency of many sequential calls start to erode the savings, and a single long call — or switching to a flat-rate model like Claude — becomes the better trade.
Two architectural notes that change the math. Prompt caching collapses the duplication penalty: cache the shared instruction/document prefix once and each chunk only pays cache-read rates for it (cheap on Anthropic and OpenAI; but remember MiniMax surcharges cache reads past 512K). And model choice can sidestep the question entirely — since Anthropic removed its surcharge, a long Claude call has no cliff to dodge, so the chunk-vs-long-context tradeoff only exists on the providers that still run a step function.
Pros
Cons
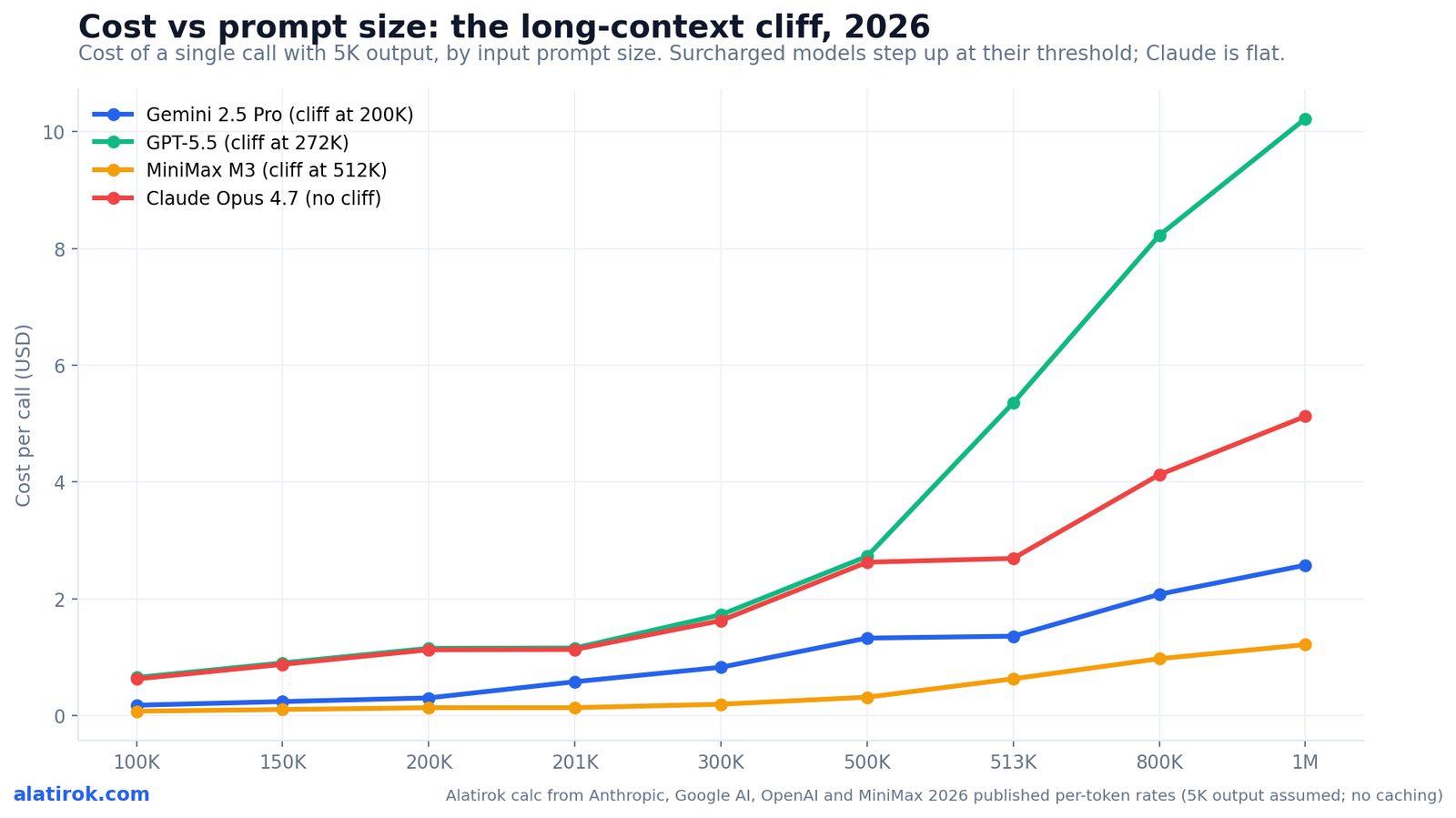
1M context token cost comparison: which model is cheapest at scale?
$1.21
MiniMax M3, 1M-token call
Cheapest at scale — if you stay under 512K
$2.58
Gemini 2.5 Pro, 1M-token call
Cheapest Western option for very long inputs
$5.13
Claude Opus 4.7, 1M-token call
Flat, no cliff, fully predictable since Mar 2026
$10.23
GPT-5.5, 1M-token call
Most expensive — new 272K surcharge bites at the top
Map the cliffs before you map the rates
For a true 1M-token call, MiniMax M3 is the cheapest by a wide margin, Gemini 2.5 Pro is the cheapest Western option, Claude Opus 4.7 is mid-priced but flat and predictable, and GPT-5.5 is the most expensive at the top of its window. The ranking flips depending on prompt size, which is exactly why a single $/M headline number misleads.
Anchoring on a 1M-token input plus 5K-token output (no caching), the published rates produce roughly: MiniMax M3 about $1.21, Gemini 2.5 Pro about $2.58, Claude Opus 4.7 about $5.13, and GPT-5.5 about $10.23. MiniMax wins on raw price but only if you stay under 512K — its sticker advantage evaporates the moment you cross its own cliff, where everything (cache included) doubles. Gemini is the value pick among US providers for very long inputs, having absorbed its 200K surcharge into a still-low $2.50/M.
The strategic story is the divergence between the two American leaders. Anthropic removed its cliff and now offers a flat, legible 1M-token price — you can reason about cost without modeling thresholds. OpenAI added a cliff and a steep top rate, so GPT-5.5 is genuinely pricey at the long end and rewards staying under 272K. If predictability is what your FinOps function values most, flat-rate Claude is now the easiest model to budget for at long context, even though it is not the cheapest per token.
Bottom line for a 1M-token comparison: choose MiniMax for cost-sensitive bulk work that fits under 512K, Gemini for inexpensive very-long Western inference, Claude when you want a flat price and frontier quality without threshold math, and GPT-5.5 only when its specific capabilities justify the top-of-window premium. Re-validate every number against the live pricing pages before you commit — this is the fastest-moving line in your AI bill.
Builder’s take
I run the token budgets for Cyntr’s orchestration engine and Loomfeed’s content pipeline, so the surcharge cliff is not abstract to me — it is a line item I watch. Three things I tell every FinOps owner who asks why a long prompt got billed double:
- The surcharge is a step function, not a slope. One token over 200K (Gemini) or 512K (MiniMax) re-prices the ENTIRE request — input, output, and on MiniMax even cache reads. Your padding tokens, your few-shot examples, your retrieved chunks: all of it jumps to the long-context rate at once.
- Anthropic just removed its cliff and OpenAI quietly added one. As of March 2026 Claude’s 1M window is flat at standard rates; meanwhile GPT-5.5 now charges 2x input above 272K. The 2024-era ‘OpenAI never surcharges’ advice is stale — re-check before you architect around it.
- Chunking almost always wins past the threshold, but not for free. Splitting a 250K-token call into two 125K calls dodges the cliff, yet you re-send shared context and lose cross-chunk reasoning. Cache the shared prefix, measure the breakeven, and only pay for the big window when the task genuinely needs global attention.
Frequently asked questions
No. As of March 13, 2026, Anthropic eliminated its long-context surcharge. Claude Opus 4.7 and Sonnet 4.6 bill the full 1M-token context window at standard rates ($5/$25 and $3/$15 per million input/output), with no premium above 200K. Older guides still showing a 2x surcharge are out of date — Claude’s long-context price is now flat.
Because the surcharge is a step function applied to the whole request. On Gemini (above 200K), GPT-5.5 (above 272K), and MiniMax M3 (above 512K), crossing the threshold by even one token re-prices every token in the call at the higher rate — not just the overflow. So a request just over the line can cost roughly 2x one just under it.
For Gemini 2.5 Pro, prompts at or below 200K input tokens bill at $1.25/M input and $10/M output. Above 200K, the rate rises to $2.50/M input and $15/M output, applied to the entire request. Context caching is not available on that long-context tier, so you cannot use cache discounts to soften the jump.
Yes — this changed. GPT-5.5 and GPT-5.4 now carry a long-context tier above roughly 272K input tokens. GPT-5.5 goes from $5/$30 to $10/$45 per million, and GPT-5.4 from $2.50/$15 to $5/$22.50, with the higher rate applied to the full session. The older ‘OpenAI never surcharges’ advice is no longer accurate.
It depends on the provider. On MiniMax M3, crossing 512K re-prices cache reads too ($0.12 to $0.24 per million) — the only model in the matrix that surcharges cached tokens. Anthropic has no surcharge at all anymore. On Gemini’s long-context tier, context caching is simply not offered. Always check whether your cache savings survive the threshold.
Chunking usually wins on surcharged models when your prompt would land between roughly 1.0x and 1.5x of the threshold — splitting keeps each call under the line and avoids the whole-request 2x multiplier. It stops being worth it past about 2-3x the threshold, where re-sending shared context and sequential latency erode the savings, and for tasks needing global attention across the whole document, where splitting breaks the reasoning.
Primary sources
- Anthropic makes a pricing change for Claude’s longest prompts — The New Stack
- Claude API Pricing 2026: every model, token rate, and cost lever — CloudZero
- Gemini Developer API pricing — Google AI for Developers
- OpenAI API pricing — OpenAI
- GPT-5.5 model reference (long-context threshold) — OpenAI
- GPT-5.5 API Pricing Guide 2026: Cost, Cache & Long Context — EvoLink
- MiniMax-M3 API pricing and context window cost guide 2026 — Current Affair Today
- Claude API Pricing reference — Anthropic
Last updated: June 3, 2026. Related: Capital.




