

What it actually costs to rent an H100, H200 or B200 by the hour in 2026 — and why neoclouds undercut AWS, Azure and GCP by 3x to 6x.
GPU cloud pricing 2026: what does it cost to rent a GPU?
In May 2026, the median on-demand price to rent a single Nvidia H100 is about $2.95 per GPU-hour, an H200 is $3.39, and a B200 is $5.24 — but the same H100 costs $2.69 on a neocloud like RunPod and $12.29 on Microsoft Azure, a 4.6x spread for identical silicon. That gap, not the absolute numbers, is the story of GPU cloud pricing 2026.
The AIMultiple Cloud GPU Rental Price Index, which tracks 58 providers and 17 GPU models, pegs the H100 cohort median at $2.95/GPU-hour — down from above $7 in early 2024, a roughly 58% decline in about two years. The A100 has fallen to $1.62, while the newest Blackwell cards anchor the top: B200 at $5.24 and B300 around $6.99.
But a single median hides a market that has effectively split in two. On one side sit the neoclouds — Lambda, RunPod, Vast.ai, Nebius, GMI Cloud, Spheron — that rent bare GPU capacity at razor margins. On the other sit the hyperscalers — AWS, Google Cloud, Azure — that wrap the same chips in VPCs, compliance, and managed services and charge 3x to 6x more. Knowing which side of that line your workload belongs on is the highest-leverage cost decision in applied AI this year.
How much cheaper are neoclouds than hyperscalers?
Neoclouds rent the exact same Nvidia GPUs as hyperscalers for 3x to 6x less: an H100 is roughly $2.69/hr on a neocloud versus $6.88 on AWS, $10.98 on Google Cloud, and $12.29 on Azure — and Spheron’s H100 spot at $1.03/hr is about 6.7x cheaper than AWS on-demand. The hardware is identical; you are paying for everything wrapped around it.
The pattern holds across the stack. For the H200, GMI Cloud lists $2.60/hr and Nebius $3.50 against Azure’s roughly $13.78 — nearly a 5x markup. For the Blackwell B200, RunPod and Lambda sit at $4.99 and Nebius at $5.50, while AWS’s p6-b200 instance runs about $14.24 on-demand. Across every generation, the hyperscaler carries a 3x-6x premium for the same FLOPs.
This is the chart every infrastructure lead should have on the wall. The clustered bars below put neocloud medians next to the hyperscaler list price for each GPU generation, and the magnitude of the gap is hard to look away from.
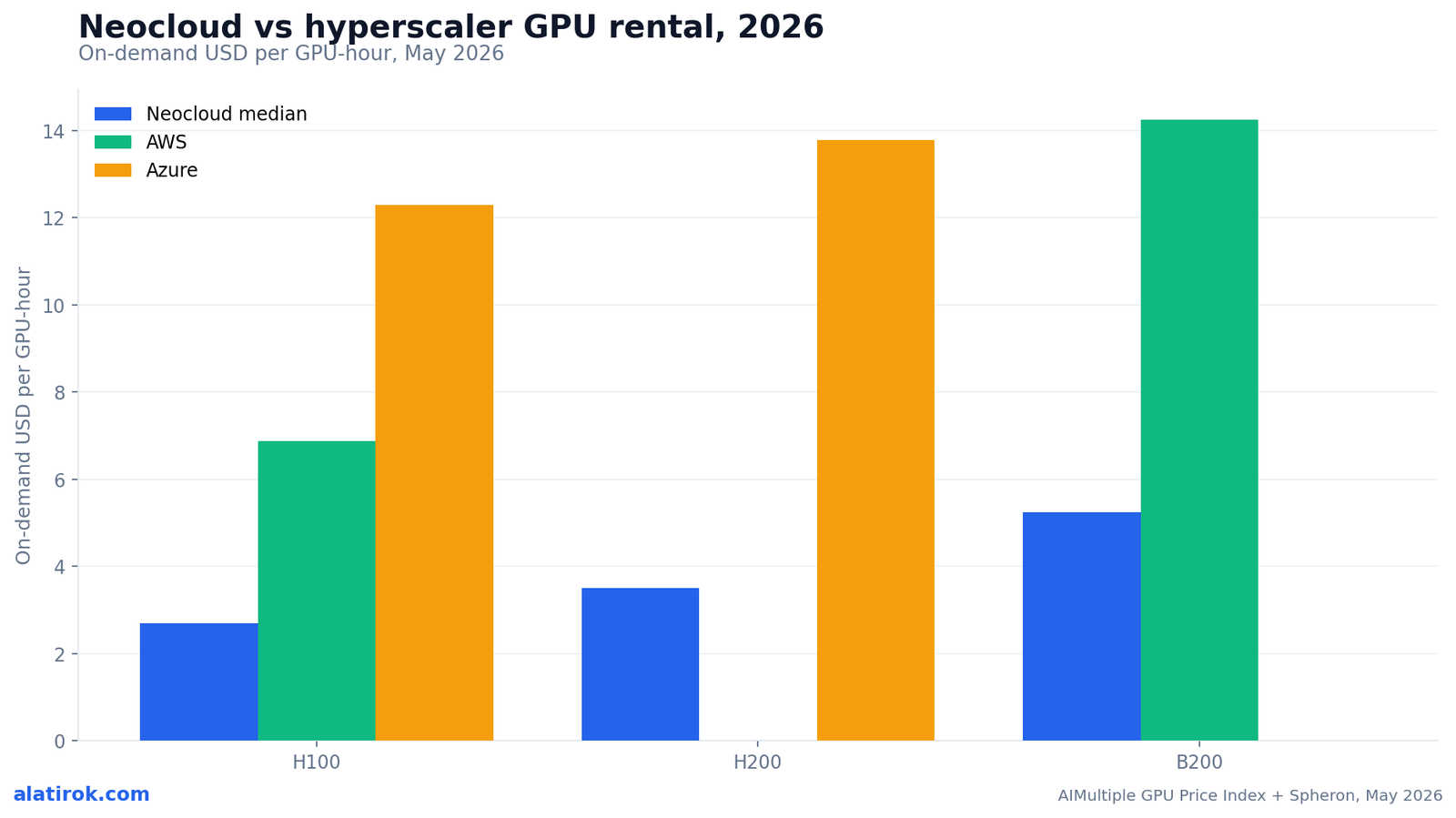
AWS does not publish a comparable on-demand H200 SKU in the tracked sample, and Azure’s headline Blackwell SKU was not yet in the May 2026 index — hence the zero bars. The neocloud line is the consistent thread: every generation lands between $2.69 and $5.24.
H100, H200 or B200: which GPU is cheapest per unit of work?
The B200 is usually the cheapest per token despite its higher hourly rate, because at roughly $5.24/hr on a neocloud it delivers about 3x to 4x the inference throughput of an H100 at $2.69/hr — so the price-per-hour ranking inverts once you normalize to work done. Hourly stickers mislead; cost-per-million-tokens is the metric that pays the bills.
The H100 remains the workhorse and the cheapest entry point at $2.69-$2.95 on-demand. The H200 adds 141GB of HBM3e (versus the H100’s 80GB), which matters enormously for serving large-context models without splitting them across cards — and at $3.39-$3.50 neocloud it is a small premium for a big memory jump. The B200 is the throughput king and the right default for high-volume inference, where its Blackwell architecture amortizes the higher hourly rate across far more tokens.
The table below lays out the full menu — on-demand and spot, neocloud floor and hyperscaler ceiling — so you can match the card to both the workload and the billing model.
| GPU | Neocloud on-demand | Neocloud spot | Hyperscaler on-demand | Key spec |
|---|---|---|---|---|
| A100 80GB | $1.07 (Spheron) | $0.60 | — | 40GB/80GB HBM2e |
| H100 SXM5 | $2.49-$2.95 | $1.03 (Spheron) | $6.88 AWS / $12.29 Azure | 80GB HBM3 |
| H200 | $2.60-$3.59 | — | $13.78 Azure | 141GB HBM3e |
| B200 SXM6 | $4.99-$6.02 | $2.12 (Spheron) | $14.24 AWS | Blackwell, 192GB |
| B300 | $6.80 (Spheron) | $2.45 | — | Blackwell Ultra |
Why did reserved H100 prices rise while on-demand fell?
Reserved H100 capacity got more expensive even as on-demand spot prices fell: SemiAnalysis’s 1-year H100 rental index rose roughly 40% in six months, from $1.70/hr in October 2025 to $2.35/hr in March 2026, because on-demand capacity is sold out and every new cluster coming online through August-September 2026 is already booked. The market is short, not soft.
This is the counterintuitive heart of GPU cloud pricing 2026. The 58% headline decline in H100 on-demand prices since 2024 created a narrative of glut and falling costs. But the reserved-contract index — compiled from monthly surveys of more than 100 market participants — tells the opposite story: anyone who locked up on-demand instances refuses to release them back into the pool even after price hikes, so committed capacity has gotten scarcer and pricier.
Before late 2025, the consensus expectation was that Hopper (H100/H200) rental prices would crater as Blackwell ramped, given Blackwell’s much lower cost per unit of compute. That reversed. The lesson for buyers: a low spot price is not a signal of abundance. If your workload needs guaranteed, uninterrupted capacity, you are negotiating in a shortage, and the reserved curve is rising under your feet.
“A low spot price is not a signal of abundance. Reserved H100 contracts rose 40% in six months while spot fell — the market is short, not soft.”
SemiAnalysis H100 1-Year Rental Price Index, March 2026
What do spot prices actually buy you?
$1.03/hr
H100 spot floor (Spheron)
vs $2.50 on-demand — a 59% cut
6.7x
H100 spot vs AWS on-demand
$1.03 spot against $6.88 AWS p5
$2.12/hr
B200 spot floor (Spheron)
vs $6.02 on-demand and $14.24 AWS
~60%
Typical spot discount
across H100, B200 and B300 on neoclouds
Spot pricing on neoclouds cuts the bill by 55% to 65% versus on-demand — Spheron’s H100 spot is $1.03 against $2.50 on-demand, and B200 spot is $2.12 against $6.02 — but in exchange your instance can be preempted with little warning, making spot ideal for fault-tolerant batch jobs and dangerous for live serving. The discount is real; so is the catch.
The economics are striking once you map them out. A B300 — Nvidia’s Blackwell Ultra — runs $6.80/hr on-demand but drops to $2.45 on spot, which is cheaper than many providers charge for an H200 on-demand. An A100 falls to $0.60/hr spot. For training runs that checkpoint frequently, embedding pipelines, offline evaluation, and synthetic-data generation, spot is close to free money.
Where spot bites is anything user-facing. A preemption mid-request is a dropped customer interaction; a preemption mid-training without checkpoints is hours of wasted compute. The discipline that separates teams who profit from spot from teams who get burned is checkpointing cadence and graceful preemption handling — engineering work that has to be priced in alongside the GPU-hour.
Below is the case for and against living on spot, drawn straight from the 2026 rate sheet.
Pros
Cons
When is the hyperscaler premium worth paying?
Paying Azure $12.29/hr for an H100 instead of $2.69 on a neocloud is rational only when the workload demands deep VPC integration, certified compliance, guaranteed non-preemptible capacity, or a single-vendor contract — for experimentation and batch work, the 3x-6x premium is almost never justified. The premium buys insurance and integration, not faster chips.
Concretely, the hyperscaler case holds when: your data must stay inside an existing AWS/GCP/Azure VPC for security or latency reasons; you need SOC 2 / HIPAA / FedRAMP boundaries the neocloud cannot certify; an enterprise procurement contract already commits you to one cloud; or you simply cannot tolerate the operational overhead of managing a thinner neocloud stack. For a regulated healthcare or finance workload, $12.29/hr can be the cheap option once you price the compliance failure mode.
For everyone else — startups, researchers, indie builders, and most inference workloads — the neocloud is the obvious answer, and the savings compound fast. An 8-GPU H100 node running 24/7 for a month costs roughly $15,500 on a neocloud at $2.69/hr versus about $70,800 on Azure at $12.29/hr. That $55,000 monthly delta is the difference between a viable product and a venture that runs out of runway, and it is why the neocloud sector exploded into the 58-provider field the index now tracks.
The same 8x H100 node, running 24/7 for one month: about $15,500 on a neocloud versus roughly $70,800 on Azure. The chip is identical — the $55K/month gap is pure platform premium.How should you actually buy GPU compute in 2026?
The optimal 2026 strategy is a tiered mix: neocloud spot for batch and experimentation, neocloud on-demand for production serving, and reserved or hyperscaler capacity only when compliance or guaranteed uptime forces it — and you should always benchmark cost-per-token, not cost-per-hour. One billing model rarely fits a whole organization.
Start by classifying every workload on two axes: how interruptible is it, and how regulated is it. Interruptible-and-unregulated goes to spot. Always-on-but-unregulated goes to neocloud on-demand. Regulated-or-contractually-bound goes to a reserved hyperscaler commitment — accepting that, per SemiAnalysis, that reserved curve is rising and capacity through late 2026 is largely pre-booked, so lock it early.
Then normalize. A B200 at $5.24/hr that does 3.5x the work of an H100 at $2.69/hr is the cheaper card per token even though its hourly rate is nearly double. The hourly sticker is a trap; the only number that survives contact with a finance review is dollars per million tokens or per training-step. Benchmark on your actual model and batch size before you commit a dollar.
Finally, watch the second-order costs neoclouds make easy to forget: egress (many neoclouds charge zero, hyperscalers do not), storage, and idle time. The headline GPU-hour is the biggest line item, but in 2026 it is no longer the only one that decides whether your AI product makes money.
Builder’s take
As someone renting GPUs to run Cyntr’s orchestration engine and Loomfeed’s inference, the 2026 price map is the single biggest lever on unit economics — and most teams read it wrong.
- The headline 58% H100 drop is real but misleading: on-demand spot fell while 1-year reserved capacity rose ~40% in six months. If you commit, you are buying into a shortage, not a discount.
- Neoclouds win on sticker price but you pay in reliability tax — spot preemptions, thinner support, fewer regions. Price the engineering hours, not just the GPU-hour.
- Hyperscaler premiums (Azure at $12.29 vs $2.69 neocloud) are not pure rent-seeking — you are paying for VPC integration, compliance, and not having your instance vanish mid-run. For a side project that math is insane; for a regulated workload it can be rational.
- I default to neocloud spot for batch and experimentation, on-demand neocloud for anything user-facing, and reserve hyperscaler only when a customer contract forces it.
- The Blackwell story matters: a B200 at ~$5.24 neocloud with ~3.5x the throughput of an H100 is often cheaper per token than an H100, even though the hourly rate is higher. Always normalize to work done, not hours billed.
Frequently asked questions
The median on-demand H100 rate in May 2026 is about $2.95 per GPU-hour, per the AIMultiple GPU Price Index across 58 providers. Neoclouds go lower — RunPod at $2.69, Lambda from $2.49, and spot as low as $1.03/hr on Spheron — while hyperscalers charge far more: AWS around $6.88, Google Cloud $10.98, and Azure $12.29 for the same chip.
The silicon is identical; the price difference of 3x to 6x reflects what wraps around it. Hyperscalers bundle VPC integration, compliance certifications (SOC 2, HIPAA, FedRAMP), managed networking, and guaranteed non-preemptible capacity. Neoclouds like Lambda, RunPod and Nebius rent bare GPU capacity at thin margins with fewer guarantees, which is why an H100 is $2.69 on a neocloud and $12.29 on Azure.
Per hour, no — a B200 is about $5.24 on a neocloud versus $2.69 for an H100. But the B200’s Blackwell architecture delivers roughly 3x to 4x the inference throughput, so per million tokens it is often the cheaper card. Always benchmark cost-per-token on your actual model rather than comparing hourly rates.
SemiAnalysis’s 1-year H100 rental index rose about 40% in six months, from $1.70/hr in October 2025 to $2.35/hr in March 2026, even as on-demand spot prices dropped. The reason is a capacity shortage: on-demand instances are sold out, holders won’t release them, and new clusters coming online through August-September 2026 are already booked. Committed capacity is scarce, so its price is rising.
Spot instances on neoclouds typically cost 55% to 65% less than on-demand. Spheron’s H100 spot is $1.03/hr versus $2.50 on-demand, and B200 spot is $2.12 versus $6.02. The catch is that spot instances can be preempted with little warning, so they suit checkpointed training and batch inference but are risky for live, user-facing serving.
On-demand, RunPod and Lambda Labs offer the B200 at $4.99/hr, with Nebius at $5.50 and Spheron at $6.02 — all far below AWS’s p6-b200 at roughly $14.24. The absolute floor is spot: Spheron lists B200 spot at $2.12/hr, about 60% below its own on-demand rate, suitable for interruption-tolerant workloads.
Primary sources
- Cloud GPU Rental Price Index (May 2026) — AIMultiple
- GPU Cloud Pricing 2026: H100 from $1.03/hr, B200 from $2.12/hr — Spheron
- The Great GPU Shortage — H100 1-Year Rental Price Index — SemiAnalysis
- Nvidia’s H100 GPU rental prices surge nearly 40% in 6 months — Seeking Alpha
- NVIDIA H200 Price Comparison (May 2026) — Thunder Compute
Last updated: June 1, 2026. Related: Capital.




