

GPT-5.4 Pro and Claude own image and chart reasoning. Kimi K2.5, Gemini and Qwen own video. In 2026, no single model wins both.
Who actually wins multimodal AI benchmarks 2026?
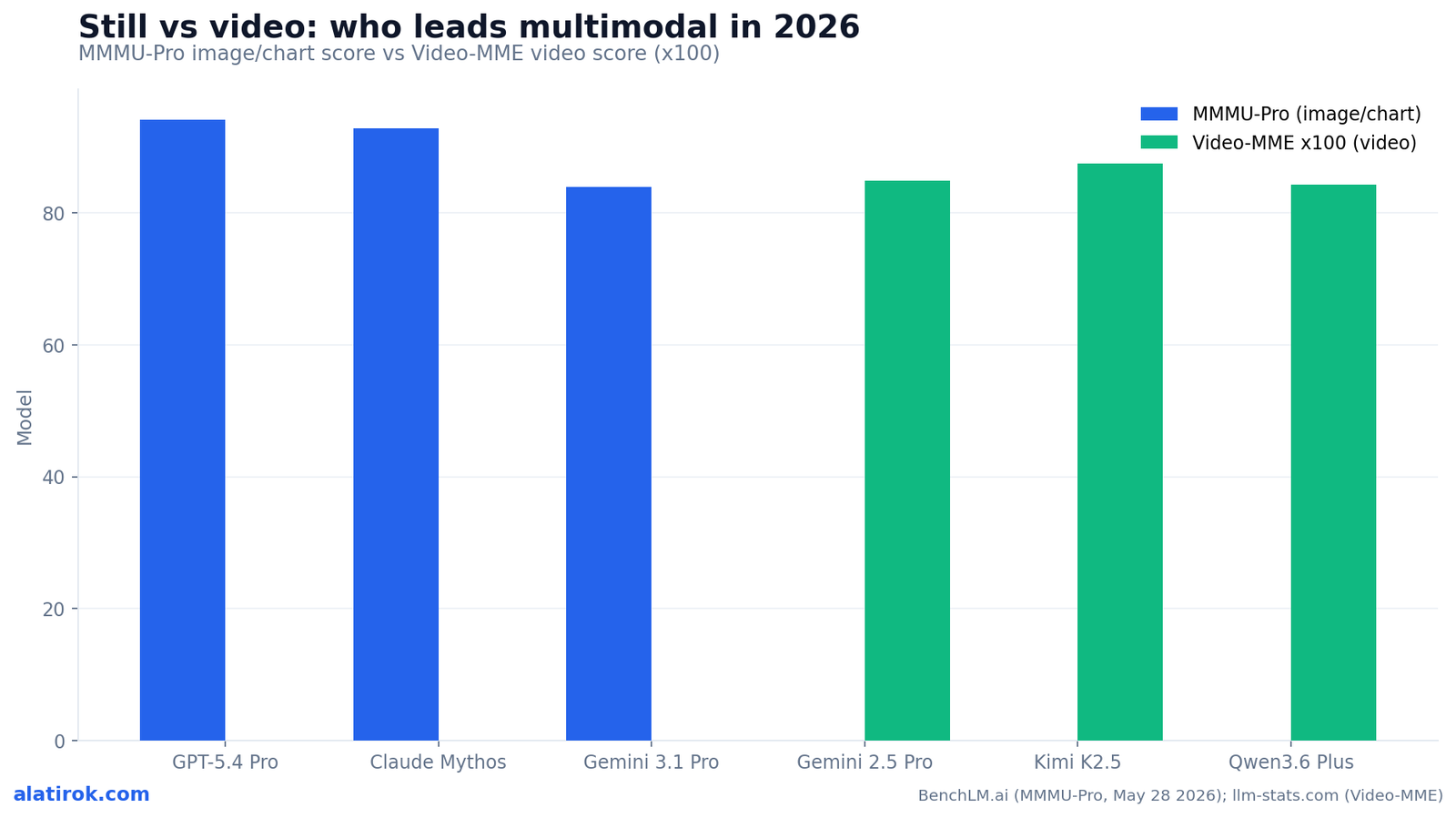
No single model wins the multimodal AI benchmarks 2026. GPT-5.4 Pro leads image and chart reasoning on MMMU-Pro at 94%, while Kimi K2.5 leads video understanding on Video-MME at 0.874 — and the two leaderboards share almost no overlap at the top.
For two years, “multimodal” was treated as one capability you either had or did not. In 2026 that framing collapsed. The benchmarks that matter now measure two genuinely different skills: parsing a static, information-dense frame (a chart, a circuit diagram, a CT scan) versus tracking meaning across thousands of frames over time. They turn out to be won by different labs, with different architectures and different training priorities.
The practical takeaway lands before the details: if you are buying a model to read documents and diagrams, you look at one leaderboard. If you are buying a model to understand hour-long video, you look at a completely different one. Conflating them is the most expensive mistake in multimodal procurement this year.
This piece breaks down both boards from primary sources — BenchLM.ai’s MMMU-Pro ranking dated May 28, 2026, and llm-stats.com’s Video-MME ranking — explains why the split exists, and shows where the frontier still falls apart entirely (the new Video-MME-v2).
MMMU-Pro: the image and chart reasoning leaders
On MMMU-Pro, OpenAI’s GPT-5.4 Pro leads at 94%, Anthropic’s Claude Mythos Preview is a close second at 92.7%, and Google’s Gemini 3.1 Pro is third at 83.9% — a roughly 9-point gap between the top two and the rest of the field of 27 models.
MMMU-Pro is the hard successor to MMMU. Where the original benchmark asked college-level questions paired with charts, diagrams, maps and chemical structures, MMMU-Pro deliberately makes them harder in three ways: it filters out questions a text-only model could guess, it adds more wrong-answer options to defeat lucky guessing, and — critically — it introduces a vision-only mode where the question text itself is embedded inside the image. The model has to see and read at the same time, the way a human does with a textbook page.
That third change is brutal. When MMMU-Pro launched, models lost between 16.8 and 26.9 percentage points moving from MMMU to MMMU-Pro. The vision-only setting alone cost GPT-4o several points and knocked open-source models down by double digits. So a 94% on MMMU-Pro in 2026 is not a saturated, meaningless score — it represents genuine frontier difficulty, and the top two models are now brushing up against the human-expert band of roughly 88.6%.
The shape of this leaderboard matters as much as the numbers. There is a clear two-model breakaway (GPT-5.4 Pro and Claude Mythos), then a dense Google-and-everyone-else cluster from 84% down to the high 70s, where Gemini 3.5 Flash (83.6%), GPT-5.5 (81.2%), Gemini 3 Pro (81%) and Moonshot’s Kimi K2.6 (79.4%) all sit within a few points of each other.
College-level questions fused with charts, diagrams, maps and chemical structures — including a vision-only mode where the question text is baked into the image, forcing the model to read and reason inside a single frame.
| Rank | Model | Provider | MMMU-Pro score |
|---|---|---|---|
| 1 | GPT-5.4 Pro | OpenAI | 94% |
| 2 | Claude Mythos Preview | Anthropic | 92.7% |
| 3 | Gemini 3.1 Pro | 83.9% | |
| 4 | Gemini 3.5 Flash | 83.6% | |
| 5 | GPT-5.5 | OpenAI | 81.2% |
| 6 | Gemini 3 Pro | 81% | |
| 7 | Kimi K2.6 | Moonshot AI | 79.4% |
Video-MME: the video understanding leaders are different
On Video-MME, Moonshot AI’s Kimi K2.5 leads at 0.874, Google’s Gemini 2.5 Pro is second at 0.848, and Alibaba’s Qwen3.6 Plus is third at 0.842 — none of which top the MMMU-Pro image leaderboard. The still-image champions, GPT-5.4 Pro and Claude, do not appear on the Video-MME podium at all.
Video-MME measures something MMMU-Pro cannot: comprehension across time. The benchmark spans 900 videos totaling 254 hours, with 2,700 human-annotated question-answer pairs, deliberately ranging from 11-second clips to full hour-long videos across six domains — knowledge, film and television, sports, artistic performance, life-record and multilingual content. It folds in video frames, subtitles and audio, so a strong score reflects fused temporal-plus-audio understanding, not single-frame pattern matching.
This is where the headline split becomes undeniable. The models that dominate static visual reasoning are absent from the top of video, and an open-weight model from Moonshot leads the closed labs. Temporal reasoning — causality, action order, event transitions — is a distinct muscle, and it is being trained hardest by a different set of teams. Alibaba’s Qwen family in particular stacks the mid-board, with multiple Qwen3-VL variants from 0.745 down filling out the open-source ranks.
If you only ever read one chart in this article, read the next one. It puts both leaderboards on a single 0-100 axis so the still-vs-video leadership swap is impossible to miss.
Why one model cannot win both leaderboards
Image reasoning and video understanding diverge because they stress different parts of the stack: MMMU-Pro rewards dense single-frame perception and reading, while Video-MME rewards temporal modeling, frame budgeting and audio fusion. Optimizing hard for one trades against the other.
A static chart question is, computationally, a fixed problem: one high-resolution image, all the information present at once, and the challenge is reading it correctly and reasoning over it. The winning move is high-fidelity visual tokenization and strong symbolic reasoning — exactly what OpenAI and Anthropic have poured effort into for document and diagram workloads.
Video is a different beast. An hour of footage is tens of thousands of frames, far more data than any context window can hold uncompressed. So video models must aggressively sample and compress frames, then reason about what happened between the frames they kept — causality, ordering, scene transitions — while keeping audio and subtitles synchronized to the visuals. A one-second sync drift can break the association entirely. The skill that wins here is temporal aggregation and efficient frame budgeting, not pixel-perfect single-frame reading.
That is why an open-weight model like Kimi K2.5 can top video while sitting mid-pack on still images, and why the MMMU-Pro leaders are nowhere on the video podium. The labs are making genuine, divergent bets. There is no free lunch where one architecture maxes both — at least not in the 2026 generation of models on the board today.
Pros
Cons
Video-MME-v2: where the whole frontier still breaks
3,300
human-hours
to build Video-MME-v2
90.7
human score
Video-MME-v2 non-linear
49.4
best model
Gemini-3-Pro, Video-MME-v2
41.3 pt
human–model gap
on Video-MME-v2
On Video-MME-v2, released April 2026, the best commercial model (Gemini-3-Pro) scores just 49.4 against a human-expert 90.7 — a 41.3-point gap that exposes how far real video reasoning still lags, even for the models leading the original Video-MME.
The original Video-MME is increasingly saturated at the top, so the benchmark’s authors built a harder successor. Video-MME-v2 took roughly 3,300 human-hours to construct — 12 annotators and 50 independent reviewers — across 800 videos and 3,200 questions, each with eight answer options instead of four. Crucially, it replaces simple per-question accuracy with a group-based, non-linear scoring strategy that rewards consistency and reasoning coherence across related questions, punishing models that get individual frames right but cannot hold a coherent understanding of the whole video.
The results are humbling. Where humans reach a 90.7 non-linear score (94.9% raw accuracy), the best commercial model lands at 49.4 (66.1% accuracy), and the best open-source model — a Qwen3.5 variant — manages only 39.1. For builders, this is the most important number in the entire 2026 multimodal landscape: it says the impressive 0.87 on the original Video-MME does not translate into trustworthy comprehension of complex, long-form video.
So read the two boards in sequence. MMMU-Pro shows a near-solved skill where the top models touch human level. Video-MME shows a contested skill with a clear but different set of leaders. Video-MME-v2 shows an unsolved skill where the entire frontier is closer to a coin flip than to a human. That progression — solved, contested, unsolved — is the real map of multimodal AI in 2026.
“MMMU-Pro shows a near-solved skill. Video-MME shows a contested one. Video-MME-v2 shows an unsolved one. That is the real map of multimodal AI in 2026.”
Alatirok analysis
How to pick a multimodal model from these boards
In 2026, multimodal is two markets, not one
Pick by modality, not by brand: route document, chart and diagram work to GPT-5.4 Pro or Claude Mythos (92-94% MMMU-Pro), and route short-to-medium video work to Kimi K2.5, Gemini 2.5 Pro or Qwen3.6 Plus (0.84-0.87 Video-MME). For long-form autonomous video, keep a human in the loop until Video-MME-v2 scores climb.
Start with your actual data. If your pipeline ingests PDFs, financial charts, schematics or scientific figures, MMMU-Pro is your benchmark and the two-model breakaway at the top is your shortlist. The 9-point gap between the leaders and the field is large enough to matter in production accuracy, so the closed-lab leaders earn their place here.
If your pipeline ingests video — security clips, lectures, meetings, product demos — ignore the MMMU-Pro ranking entirely and shortlist from Video-MME. The strong showing of open-weight models (Kimi, the Qwen family) is a gift: you can often self-host or fine-tune the video leaders, which the closed image leaders do not allow. Just cap your ambition at clip lengths and complexity the benchmark actually covers.
Whatever you choose, treat these scores as a starting filter, not a verdict. The MMMU-Pro board moved measurably between March and late May 2026, and vendor-reported numbers vary by evaluation methodology. The only authoritative leaderboard is the one you build from your own representative samples — then re-run it every quarter as the frontier keeps reshuffling.
Builder’s take
As someone who routes real traffic through these models inside Cyntr and Loomfeed, the still-vs-video split is not trivia — it is a procurement signal. Here is how I read the 2026 board.
- Stop asking ‘which model is best at multimodal.’ That question has no answer in 2026. Ask ‘best at charts’ or ‘best at an hour of video’ — they have different winners.
- For document, chart and diagram pipelines, GPT-5.4 Pro and Claude Mythos are the safe defaults at 92-94% on MMMU-Pro. I send Cyntr’s chart-extraction work there without a second thought.
- For anything frame-heavy — surveillance clips, lecture recordings, long product demos — I test Kimi K2.5, Gemini and Qwen first, because the still-image leaders are simply not on the Video-MME podium.
- Watch Video-MME-v2. When the best model scores 49.4 against a human 90.7, that is not a leaderboard — it is a warning label. Do not ship autonomous long-video agents on today’s models.
- Benchmark scores rot fast. The May 28 board already looks different from March. Re-test against your own clips quarterly; vendor slides are marketing, your eval is truth.
Frequently asked questions
The two most-cited multimodal AI benchmarks in 2026 are MMMU-Pro, which tests image, chart and diagram reasoning, and Video-MME, which tests video understanding across clips from 11 seconds to an hour. A harder video successor, Video-MME-v2, launched in April 2026.
GPT-5.4 Pro leads MMMU-Pro at 94% as of BenchLM.ai’s May 28, 2026 ranking, with Claude Mythos Preview second at 92.7% and Gemini 3.1 Pro third at 83.9%, across a field of 27 models.
On the Video-MME leaderboard, Kimi K2.5 from Moonshot AI leads at 0.874, followed by Gemini 2.5 Pro at 0.848 and Alibaba’s Qwen3.6 Plus at 0.842. Notably, the image-reasoning leaders do not top the video board.
Image reasoning rewards dense single-frame perception and reading, while video understanding rewards temporal modeling, frame sampling and audio synchronization. These are different skills, so labs make divergent architectural bets and no single 2026 model leads both leaderboards.
MMMU-Pro is the robust successor to MMMU. It filters out text-only-answerable questions, adds more answer options to defeat guessing, and embeds question text inside images so models must see and read at once. Models lost 16.8 to 26.9 points moving from MMMU to MMMU-Pro.
Poorly. On Video-MME-v2, released April 2026 after roughly 3,300 human-hours of annotation, the best commercial model (Gemini-3-Pro) scores 49.4 against a human-expert 90.7 — a 41.3-point gap that shows complex long-form video reasoning remains unsolved.
Primary sources
- MMMU-Pro Benchmark 2026: 27 LLM scores — BenchLM.ai
- Video-MME Benchmark Leaderboard — llm-stats.com
- Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding — arXiv
- MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark — arXiv
- Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis — MME-Benchmarks (GitHub)
Last updated: June 1, 2026. Related: Products.




