

The Future of Life Institute graded eight frontier labs on 35 indicators. Anthropic topped out at a C+, and not one company cleared a D on existential safety.
What the AI safety index 2026 actually measured
The AI safety index 2026 is the Future of Life Institute’s third independent scorecard, grading eight frontier AI labs on 35 indicators across six domains, with an independent panel of experts assigning letter grades on a standard 4.0 GPA scale. Released in December 2025 as the “Winter 2025” edition and widely cited through 2026, it is the closest thing the industry has to a comparable, repeatable safety report card.
The six domains are Risk Assessment, Current Harms, Safety Frameworks, Existential Safety, Governance and Accountability, and Information Sharing. Data was collected through November 8, 2025 from public documents and a voluntary company survey. Five of the eight companies submitted survey responses; Meta, DeepSeek and Alibaba Cloud relied on public materials alone, which the panel notes weighed on their disclosure-heavy scores.
The eight labs assessed are Anthropic, OpenAI, Google DeepMind, xAI, Z.ai, Meta, DeepSeek and Alibaba Cloud. That roster is deliberate: it spans the US frontier leaders and the leading Chinese labs, which is what makes this the rare apples-to-apples comparison across the geopolitical divide.
The headline number is unflattering for everyone. The best overall grade in the entire index is a C+. No lab earned a B or an A overall, and the single most repeated finding is that the field’s safety practices have not caught up to its capability ambitions.
Scores run 0 to 4 on a US GPA basis: A=4.0, B=3.0, C=2.0, D=1.0, F=0. A 2.0 is a flat C. Anything below 2.0 is a D or F. The grading was done by an independent expert panel, not by the companies themselves.
The full scoreboard: overall grades for all eight labs
2.67
Anthropic’s top overall score
A C+, the best grade in the index
0.98
Alibaba Cloud, last place
A D-, lowest of eight labs
8
Labs graded
Across 35 indicators in 6 domains
Anthropic leads the AI safety index 2026 with an overall 2.67 (C+), followed by OpenAI at 2.31 (C+) and Google DeepMind at 2.08 (C); every other lab landed in D territory, from xAI’s 1.17 down to Alibaba Cloud’s 0.98 (D-). The top three clear a flat C; the bottom five do not.
The cluster is striking. Three labs sit between 2.08 and 2.67. The other five are packed between 0.98 and 1.17, a spread of just 0.19 points across xAI, Z.ai, Meta, DeepSeek and Alibaba Cloud. There is no gentle gradient here; there is a cliff. The distance from Google DeepMind (2.08) to xAI (1.17) is wider than the entire range separating the bottom five labs from one another.
That bimodal shape is the single most important takeaway. The index does not describe a spectrum of slightly-safer-to-slightly-riskier labs. It describes two populations: a group that has built measurable safety processes and disclosed them, and a group that largely has not.
| Rank | Company | Overall score | Grade |
|---|---|---|---|
| 1 | Anthropic | 2.67 | C+ |
| 2 | OpenAI | 2.31 | C+ |
| 3 | Google DeepMind | 2.08 | C |
| 4 | xAI | 1.17 | D |
| 5 | Z.ai | 1.12 | D |
| 6 | Meta | 1.10 | D |
| 7 | DeepSeek | 1.02 | D |
| 8 | Alibaba Cloud | 0.98 | D- |
The C-minus cliff: where the top three pull away
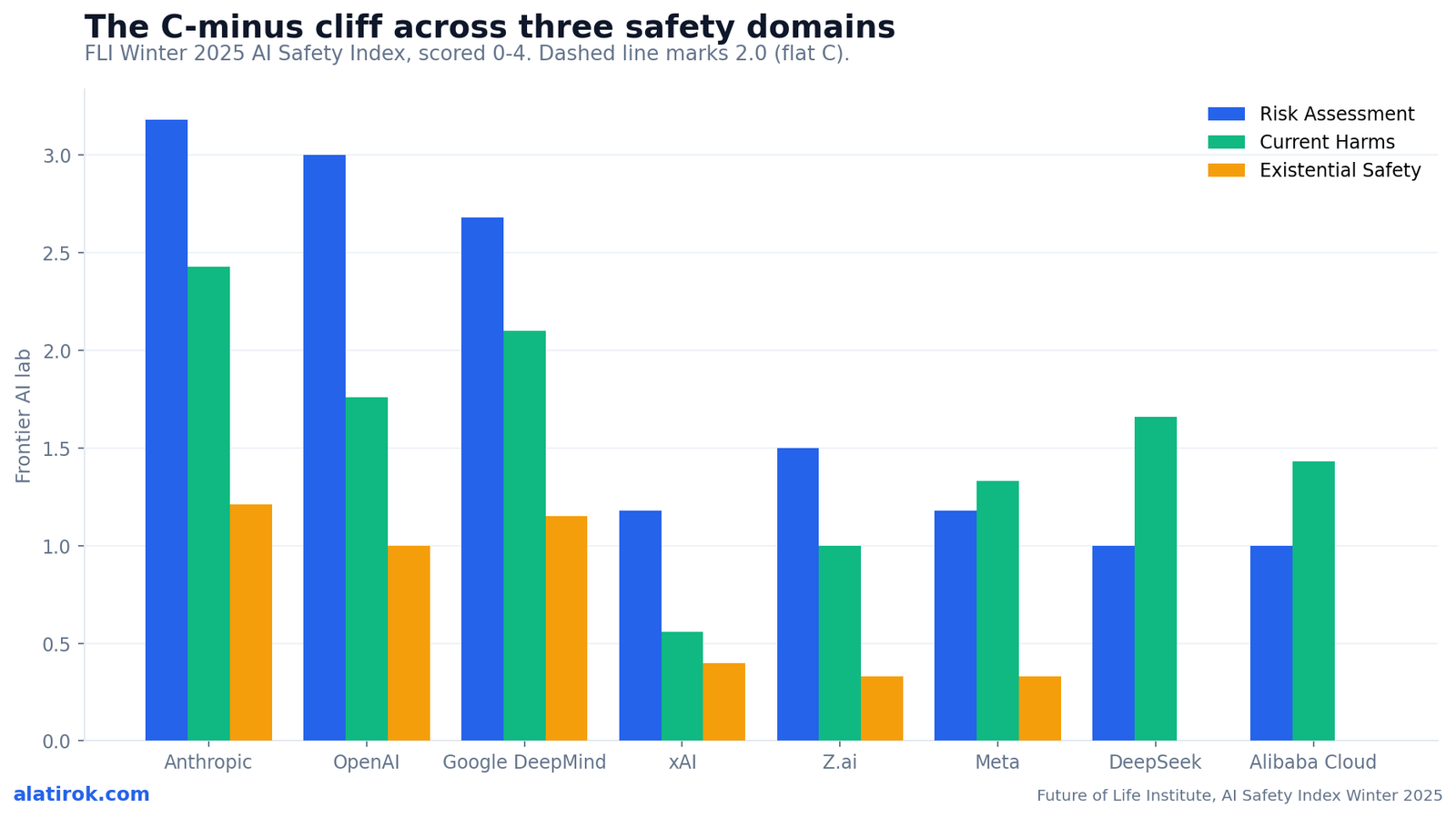
The gap between the leaders and the rest is driven almost entirely by three domains: Risk Assessment, Safety Frameworks and Information Sharing, where the top three labs post B-range scores and the bottom five collapse into Ds and Fs. This is the clearest data-rich view of why the AI safety index 2026 splits into two tiers.
On Risk Assessment, Anthropic scored 3.18 (B), OpenAI 3.00 (B) and Google DeepMind 2.68 (C+). The bottom five all sit at or below 1.50: Z.ai 1.50, xAI 1.18, Meta 1.18, DeepSeek 1.00, Alibaba Cloud 1.00. That is roughly a two-full-grade gap on the single domain most predictive of how a model behaves under adversarial pressure.
Current Harms — covering real, present-day issues like security, bias and misuse — is the one domain where the bottom labs occasionally close the gap, but the ceiling stays low. Anthropic leads at 2.43 (C+), Google DeepMind at 2.10 (C), and DeepSeek (1.66) actually edges out OpenAI (1.76) and Meta (1.33). The worst Current Harms score belongs to xAI at 0.56 (F).
The chart below maps three domains per lab against the 2.0 (flat C) reference line. The visual point is blunt: only Anthropic, OpenAI and Google DeepMind have any bars crossing 2.0, and they cross it on the domains that take real institutional investment to build.
Existential safety: nobody scored above a D
For the second straight edition of the index, no company scored above a D on existential safety — Anthropic topped the domain at 1.21, with OpenAI at 1.00 and Google DeepMind at 1.15, while xAI (0.40), Z.ai (0.33), Meta (0.33), DeepSeek (0.00) and Alibaba Cloud (0.00) all earned F grades. This is the index’s defining structural weakness.
The domain measures whether a lab has a concrete, credible plan for controlling or aligning systems that approach or exceed human-level capability. The panel’s verdict is that the rhetoric about AGI and superintelligence has not translated into quantitative safety plans, alignment-failure mitigations, or credible internal monitoring and control interventions. FLI president Max Tegmark told reporters that reviewers found the universal failure here “kind of jarring.”
Two labs — DeepSeek and Alibaba Cloud — posted a literal 0.00 on existential safety, meaning the panel found nothing assessable. Even the three leaders, all of which publicly target AGI within the decade, cannot clear a D. The contradiction is the story: the companies most confident they will build smarter-than-human systems are the same ones with no graded plan for keeping those systems under control.
For a builder, the practical reading is sobering but simple. The vendor will not hand you a controllability guarantee for advanced systems because, per this index, the vendor does not have one. That pushes the burden of containment, monitoring and kill-switch design back onto whoever deploys the model.
“The companies most confident they will build smarter-than-human systems are the same ones with no graded plan for keeping those systems under control.”
On the existential-safety gap
Three labs publish no safety framework at all
Alibaba Cloud, DeepSeek and Z.ai publish no Frontier AI Safety Framework whatsoever, earning failing or near-failing grades in that domain, even as roughly a dozen companies industry-wide published or updated such frameworks during 2025. A missing framework is the cleanest signal in the entire index.
DeepSeek and Alibaba Cloud both scored 0.55 (F) on Safety Frameworks; Z.ai scored 0.88 (D-). By contrast, the top three all sit in the C+ range — Anthropic 2.65, OpenAI 2.55, Google DeepMind 2.45 — reflecting published, versioned frameworks with defined capability thresholds and response commitments. xAI (1.50, D+) and Meta (1.61, D+) have frameworks on paper but thin substance behind them.
A Frontier AI Safety Framework is the document where a lab commits, in advance, to specific capability tripwires and the mitigations it will apply when a model crosses them. It is the closest thing the field has to a published safety contract. Without one, there is no external reference point for what a lab promised to do before shipping a dangerous capability.
This is also where the US-China comparison sharpens. The three labs with no framework are all Chinese, but the picture is not purely geographic: Z.ai actually outscored several Western peers on Information Sharing, while Meta and xAI underperform on framework substance despite operating in the same regulatory environment as the three leaders.
If you are selecting a model for production, treat “no published safety framework” as a missing SLA. There is no document to escalate against when a safety failure surfaces downstream.
| Company | Safety Frameworks | Grade | Published framework? |
|---|---|---|---|
| Anthropic | 2.65 | C+ | Yes |
| OpenAI | 2.55 | C+ | Yes |
| Google DeepMind | 2.45 | C+ | Yes |
| Meta | 1.61 | D+ | Yes (thin) |
| xAI | 1.50 | D+ | Yes (thin) |
| Z.ai | 0.88 | D- | No |
| DeepSeek | 0.55 | F | No |
| Alibaba Cloud | 0.55 | F | No |
Domain by domain: where each leader is strong and weak
Even among the top three, the AI safety index 2026 shows distinct profiles: Anthropic leads on Risk Assessment and Governance, OpenAI matches it on frameworks but lags on Current Harms, and Google DeepMind trails on Governance and Accountability despite solid technical scores. The leaders are not interchangeable.
Anthropic’s strongest domains are Risk Assessment (3.18, B) and Governance and Accountability (2.82, B-), with a B on Information Sharing. Its weakest, like everyone’s, is Existential Safety at 1.21. OpenAI mirrors the risk-assessment strength (3.00, B) but drops to 1.76 (C-) on Current Harms and 2.54 (C+) on Governance.
Google DeepMind is the most uneven of the three. Its Risk Assessment (2.68) and Current Harms (2.10) are respectable, but Governance and Accountability falls to 1.80 (C-) — below both Anthropic and OpenAI — which is what drags its overall to a flat C and a third-place finish.
Among the bottom five, the texture matters too. DeepSeek’s relatively strong Current Harms (1.66) is undercut by an F on Safety Frameworks (0.55) and a 0.00 on Existential Safety. Meta has a framework but weak substance across the board. xAI posts the worst Current Harms score in the index (0.56, F), a notable result for a lab shipping a high-traffic consumer assistant.
Pros
Cons
What the AI safety index 2026 means for buyers and regulators
A report card the whole field is failing — but unevenly
The practical signal from the AI safety index 2026 is to treat the 2.0 line as a procurement threshold and the existential-safety gap as a mandate to build your own containment — the index tells you which vendors have institutional safety processes, not that any of them have solved safety.
For enterprise buyers, the three labs above 2.0 — Anthropic, OpenAI and Google DeepMind — are the ones with published frameworks, documented risk assessment and disclosure practices you can actually cite in a vendor review. The bottom five may be cheaper or faster, but you are absorbing the disclosure gap yourself, and three of them give you no framework to reference at all.
For regulators, the universal failure on existential safety is the headline that justifies intervention. When the best-prepared lab on the most consequential risk cannot clear a D, voluntary commitments alone are clearly not closing the gap. The index is increasingly cited in policy debates precisely because it quantifies that shortfall in a comparable way.
For everyone, the most useful artifact is the trend. This is the third edition; the deltas between editions reveal who is investing in safety infrastructure and who is coasting on press releases. A single C+ is not reassuring, but a lab climbing across editions is telling you something a one-time grade cannot.
Builder’s take
As someone running production AI orchestration at Cyntr and a discussion platform at Loomfeed, I read this index less as a morality play and more as a procurement document. Here is what I actually take from it:
- The C-minus cliff is the only line on the chart that matters for buyers. The top three (Anthropic, OpenAI, Google DeepMind) clear 2.0; the bottom five do not. If you are routing agent traffic through a model, that gap is your real risk surface.
- A missing safety framework is a missing SLA. Alibaba Cloud, DeepSeek and Z.ai publish no framework at all. When I evaluate a model for Cyntr’s pipeline, no published framework means I have no contract to point at when something goes wrong in production.
- Existential-safety scores are a weak signal for builders but a loud signal for regulators. Nobody clearing a D there tells me the whole field is improvising the AGI endgame, so I plan my own guardrails as if the vendor has none.
- Risk Assessment is the domain that correlates with day-to-day reliability. Anthropic’s 3.18 and OpenAI’s 3.00 there are why their models behave more predictably under adversarial prompts in my own testing.
- Treat this index as a moving baseline, not a verdict. It is the third edition; the deltas between editions tell you who is actually investing, and that trend line is worth more than any single grade.
Frequently asked questions
It is an independent safety scorecard produced by the Future of Life Institute (FLI), grading eight frontier AI labs on 35 indicators across six domains. The most-cited edition is the Winter 2025 report, released in December 2025, with grades assigned by an independent panel of AI researchers and governance experts on a 0-to-4 GPA scale.
Anthropic scored highest overall with a 2.67 (C+), followed by OpenAI at 2.31 (C+) and Google DeepMind at 2.08 (C). No lab earned a B or A overall. The remaining five labs — xAI (1.17), Z.ai (1.12), Meta (1.10), DeepSeek (1.02) and Alibaba Cloud (0.98) — all landed in D territory.
The existential-safety domain measures whether a lab has a concrete plan to control or align systems at or beyond human-level capability. The panel found that AGI ambitions had not translated into quantitative safety plans or credible control interventions at any lab. Anthropic topped the domain at just 1.21, while DeepSeek and Alibaba Cloud scored 0.00. It was the second straight edition with no grade above a D here.
Alibaba Cloud, DeepSeek and Z.ai publish no Frontier AI Safety Framework, earning failing or near-failing grades (0.55, 0.55 and 0.88 respectively) in that domain. By contrast, Anthropic, OpenAI and Google DeepMind all hold published, versioned frameworks scoring in the C+ range. Roughly a dozen companies industry-wide published or updated such frameworks during 2025.
An independent expert panel grades each lab on 35 indicators grouped into six domains — Risk Assessment, Current Harms, Safety Frameworks, Existential Safety, Governance and Accountability, and Information Sharing — using a standard US GPA scale where A=4.0, B=3.0, C=2.0, D=1.0 and F=0. Data came from public documents and a voluntary company survey, with a cutoff of November 8, 2025.
The index is a measure of disclosed safety practices, not raw model quality, but the gap is meaningful. The three labs above a 2.0 (C) offer published frameworks, documented risk assessment and disclosure you can cite in a vendor review. For labs in the D range — especially the three with no published framework — you absorb the disclosure gap yourself and should plan your own containment, monitoring and escalation paths.
Primary sources
- AI Safety Index Winter 2025 (full scores) — Future of Life Institute
- AI Company Safety Practices Fall Short (press release) — Future of Life Institute
- Future of Life Index grades AI labs poorly on existential safety — Axios
- AI labs earned some of the worst grades possible on an existential safety index — Fortune
- Top AI companies’ safety practices fall short, new report says — NBC News
Last updated: June 1, 2026. Related: Governance.




