

The layer that survives a crash, a model timeout, or a human-in-the-loop pause, compared across Temporal, Restate, and DBOS, with Inngest and Hatchet as reference points.
What is durable execution for AI agents, and why does the agent layer need it?
Durable execution for AI agents is an infrastructure layer that records every step of an agent’s progress to persistent storage so the agent can survive a process crash, a model timeout, or a multi-day human-in-the-loop pause and resume exactly where it left off, without re-running side effects. It is the difference between an agent that loses 30 hours of work when a pod restarts and one that picks up at the next unfinished step. As agents move from demos into production, durable execution for AI agents has become the part of the stack that decides whether an agent is a science project or a system you can put in front of customers.
The reason the agent layer needs this specifically is structural. A traditional request-response service finishes in milliseconds; if it crashes, you retry the whole request. An agent does not finish in milliseconds. It loops: call a model, parse a tool request, call an external API, feed the result back, call the model again, maybe wait hours for a human approval. Any of those steps can fail independently, the whole thing can run for days, and re-running it from scratch is both expensive (you pay for every token again) and dangerous (you might charge a card or send an email twice).
Gartner predicts that 40% of enterprise applications will feature task-specific AI agents by the end of 2026, up from less than 5% in 2025. That curve is exactly why durable execution stopped being a niche concern. When agents were toys, an occasional lost run was tolerable. When they are embedded in 40% of enterprise apps and orchestrating payments, refunds, and tickets, a lost run is an incident. Three engines have emerged as the serious contenders for this layer: Temporal, Restate, and DBOS.
How the durable execution engines actually work
All three engines achieve durability by persisting each completed step before the next one runs, then replaying recorded results instead of re-executing them after a crash, but they differ fundamentally in where that state lives and whether you operate a separate server. Understanding the mechanism is what lets you reason about failure, so it is worth getting concrete about each.
Temporal uses deterministic workflow replay. Your orchestration code is a workflow, every external effect is an activity, and Temporal records an event history of activity inputs and outputs. After a crash, Temporal re-runs the workflow’s coordination code, but per Temporal’s own documentation, replay does not re-execute activities; it reuses the recorded outputs from the event history. The LLM call, the database write, the API call happen exactly once and are read back from history on replay. The cost of this model is that workflow code must be deterministic, and large LLM payloads can saturate workflow history.
Restate is journal-based. Every durable step is appended to a per-invocation journal and persisted before the invocation proceeds, so the engine always knows precisely how far an invocation got. Restate ships as a self-contained single binary that scales from a laptop to multi-region clusters, and Restate Cloud, which opened to everyone on September 30, 2025, runs that binary as fully-managed infrastructure so you do not operate stateful infra yourself. DBOS takes the most minimal approach of all: it is a library, not a server. You decorate functions with @DBOS.workflow() and @DBOS.step(), and DBOS checkpoints state directly into your own Postgres. Per the DBOS docs, there is no additional infrastructure to configure or manage, in pointed contrast to Temporal, where the server and its datastores sit on the critical path as single points of failure.
Every engine here forces non-deterministic work (LLM calls, tool calls, external APIs) into a recorded step or activity. The orchestration code stays deterministic and replayable; the messy, non-deterministic work runs once and is read back from the journal. If you remember one thing about this category, remember that.
Temporal vs Restate vs DBOS: the comparison matrix
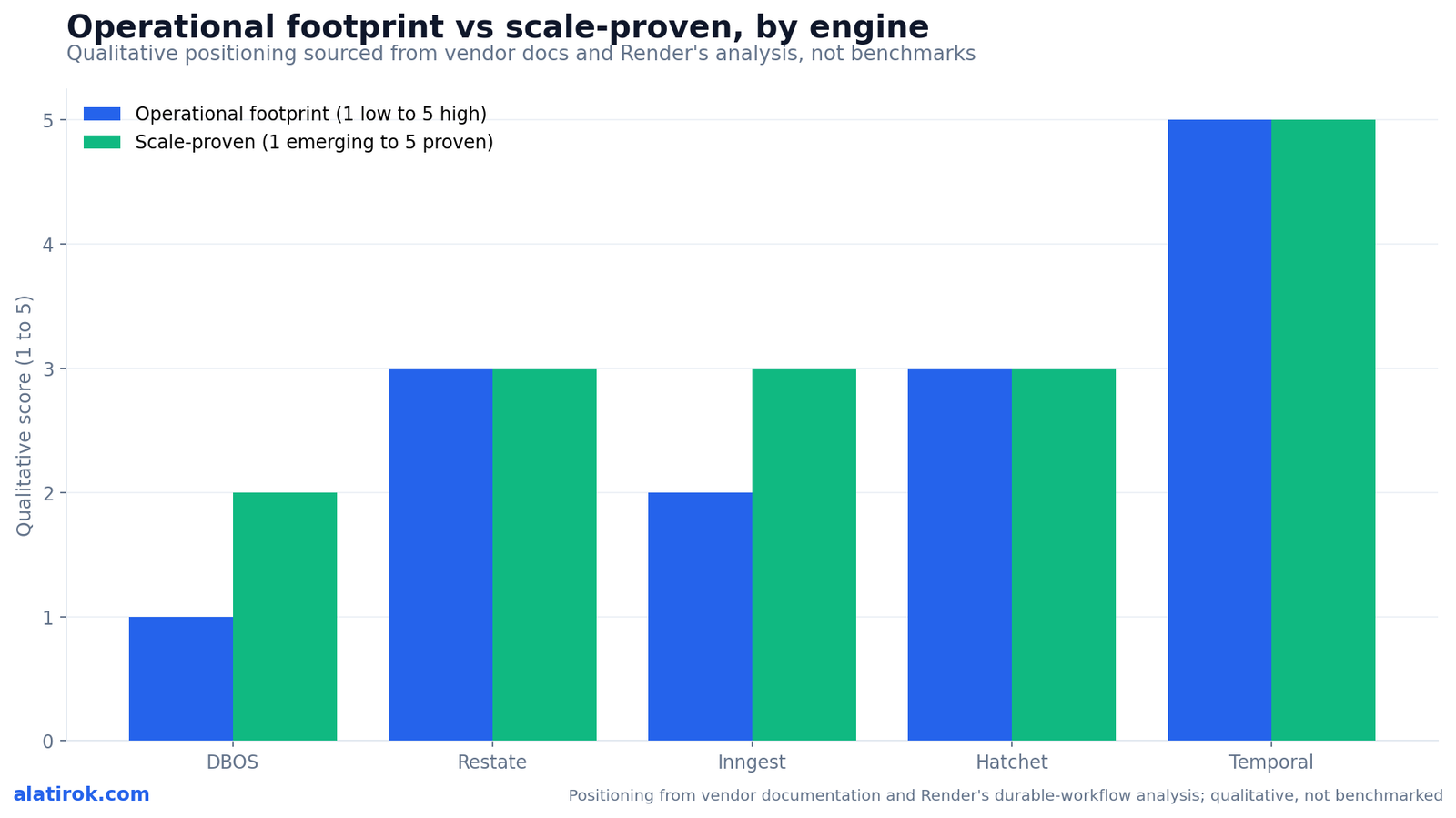
Choose Temporal for the largest scale and the deepest agent-framework integrations, Restate for a lighter single-binary footprint that fits edge and serverless, and DBOS for the absolute minimum operational footprint when you already run Postgres. The table below lines up the dimensions that actually drive the decision: architecture, how each handles the non-deterministic LLM call, whether a separate orchestration server is required, and the framework wrappers that decide how much glue code you write.
A few rows deserve emphasis. The orchestration-server column is the single biggest operational fork in the road. Temporal and the managed tiers of Restate run a server (self-hosted or cloud); DBOS runs none, which is its entire pitch. The framework-wrapper column is where 2026 momentum shows: the OpenAI Agents SDK plus Temporal Python SDK integration reached general availability on March 23, 2026, wrapping every agent invocation as a Temporal activity so crash-proofing comes essentially for free.
“The question is not which engine is best. It is which failure you are most afraid of, and how much infrastructure you are willing to babysit to avoid it.”
The core trade-off in choosing a durable execution layer
| Dimension | Temporal | Restate | DBOS |
|---|---|---|---|
| Persistence model | Deterministic workflow replay from event history | Journal-based; every step persisted before proceeding | Checkpoints workflow state into your own Postgres |
| Architecture | Multi-service cluster (Cassandra/Postgres + workers) or Temporal Cloud | Self-contained single binary; laptop to multi-region | Library embedded in your app; no separate server |
| Orchestration server required | Yes (self-hosted or Temporal Cloud) | Yes, but single binary; managed via Restate Cloud | No |
| Non-deterministic LLM calls | Wrapped in Activities; run once, replayed from history | Wrapped in durable steps; journaled, not re-run | Wrapped in @DBOS.step(); checkpointed, auto-retried |
| Operational footprint | High (cluster + datastores to manage) | Mid (single binary; managed option) | Low (just a library + Postgres you already run) |
| Framework wrappers | OpenAI Agents SDK integration GA Mar 23 2026; Python/Go/Java/TS SDKs | TS/Java/Python/Go SDKs; serverless platform deploys | Python and TypeScript decorators; Pydantic AI integration |
| Scale signal | 9.1T lifetime actions; 150k+ actions/sec peak | Public cloud since Sep 2025; emerging at scale | Emerging; strongest fit for existing Postgres shops |
Temporal: the scale-proven incumbent for durable execution
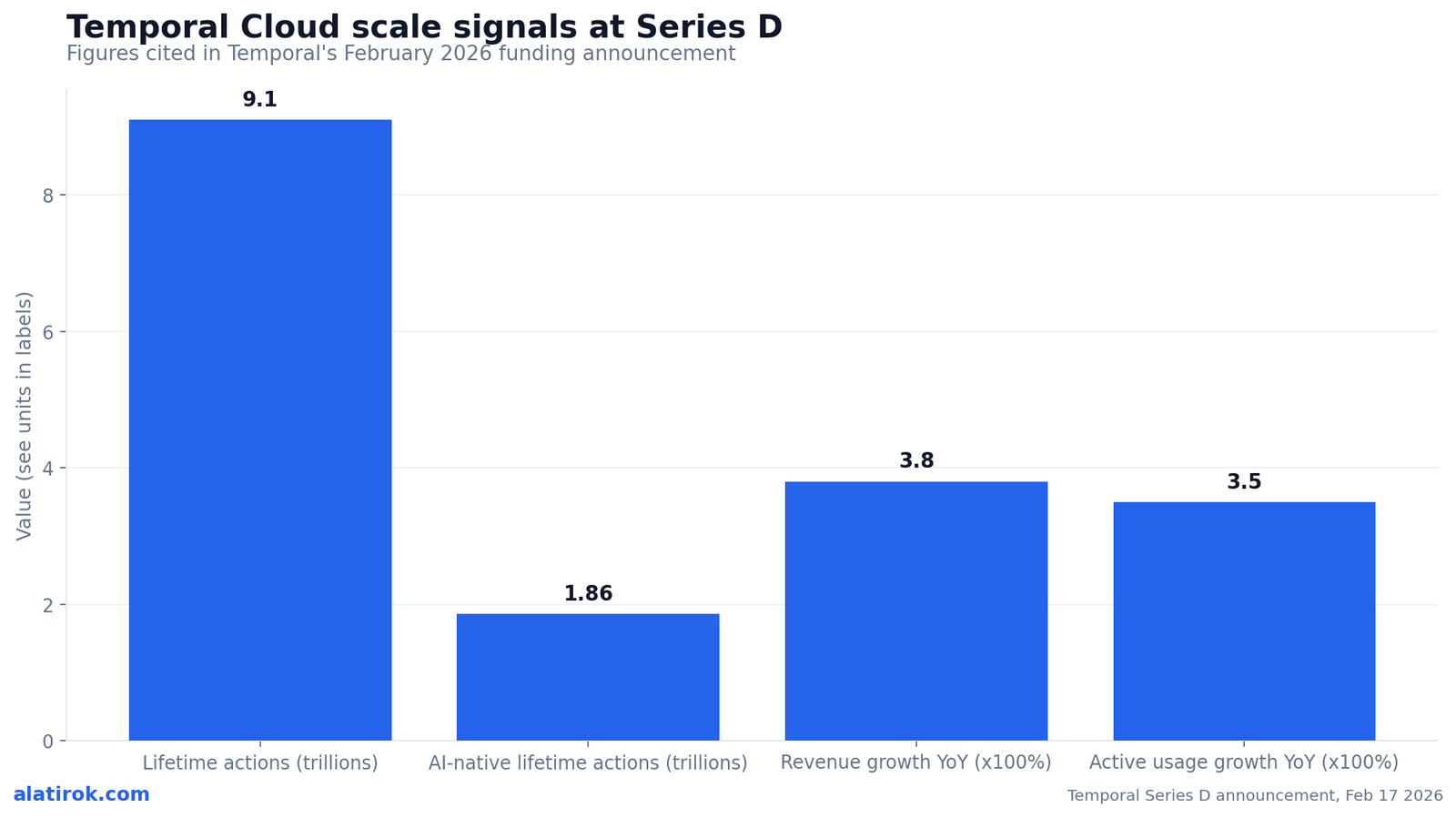
Temporal is the most battle-tested durable execution layer, the right pick when you need proven scale and first-class agent-framework integrations, at the cost of the highest operational footprint. It explicitly positions itself as the durable execution layer for agents, and the numbers behind that positioning are real: on February 17, 2026, Temporal raised a $300M Series D at a $5B valuation, led by Andreessen Horowitz, citing 9.1 trillion lifetime action executions on Temporal Cloud and peak throughput above 150,000 actions per second.
The customer list is the other signal. Temporal cites OpenAI, ADP, Yum! Brands, and Block among its users, and the company reported revenue growth above 380% and weekly active usage growth of 350% year over year. For agents specifically, the OpenAI Agents SDK integration reaching GA in March 2026 is the headline: a TemporalRunner wraps the SDK runner so every agent invocation executes as a durable Temporal activity, and an activity_as_tool helper converts Temporal activities into OpenAI-compatible tool schemas automatically.
The cost is real too. Render’s analysis notes Temporal faces workflow-history saturation with large LLM payloads and requires learning deterministic coding constraints, and DBOS points out the Temporal server and datastores sit on the critical path as single points of failure. Self-hosting means operating a multi-service cluster. None of this is disqualifying at scale, but it is exactly the overhead a small team is trying to avoid.
Restate and DBOS: the lighter-weight challengers
Restate trades cluster operations for a single binary that fits edge and serverless deployments, while DBOS trades the orchestration server entirely for a library that checkpoints into the Postgres you already run. These are not merely smaller Temporals; they are different bets on where durable execution for AI agents should live.
Restate’s bet is portability. The same self-contained binary runs on a laptop and scales to multi-region clusters, and Restate Cloud explicitly targets serverless compute, with documented deploys to Cloudflare Workers, Vercel Functions, and Deno Deploy. Pricing is usage-based and counts durable actions as the billing unit, with a free tier of 50,000 actions per month and no credit card required. State reads and writes via ctx.get and ctx.set are not billed as actions, which keeps the pricing model legible for agents that touch state constantly. The persistence guarantee is the journal: every step is durably recorded before the invocation proceeds.
DBOS’s bet is radical minimalism. There is no orchestration server at all. You install the library, point it at Postgres, and decorate functions. When a workflow starts, DBOS writes a row to a workflow_status table as PENDING and stores the inputs; each completed step writes its output to an operation_outputs table; on restart, a background thread queries Postgres for PENDING workflows and resumes each from its last completed step by simply calling the function again with its stored inputs. The @DBOS.step() decorator takes retriesAllowed, intervalSeconds, and maxAttempts so retry policy is per-step and declarative. For a team already operating Postgres, the marginal operational cost of adding durable execution is close to zero, which is the whole point.
Pros
Cons
Inngest, Hatchet, and framework checkpoints: the reference points
Inngest and Hatchet are adjacent durable-execution entrants worth plotting as reference points, and framework-native checkpointing like LangGraph 1.0 is a related but weaker guarantee you should not confuse with full durable execution. The category is crowding, and knowing where the neighbors sit clarifies the three primary choices.
Inngest uses step-level memoization: each step runs once, its result is persisted externally, and on retry completed steps are skipped by re-injecting stored results, making agent workflows crash-proof without a new infrastructure layer. It adds AI-specific primitives like step.ai.infer, which proxies long-running LLM requests to cut serverless compute cost, and step.ai.wrap, which adds retries and telemetry to any AI SDK call. The watch-out, per Render, is that step-based pricing can get expensive fast when an agent makes many model calls. Hatchet is a managed durable task queue, YC-backed, that durably logs every task invocation and resumes exactly where workflows left off; it was purpose-built for AI pipelines with DAG-based task graphs, streaming step outputs, and priority lanes.
LangGraph 1.0, released in October 2025, provides durable execution that the deepagents stack builds on. When you compile a graph with a checkpointer such as PostgresSaver, the runtime snapshots graph state at every super-step, keyed by a thread_id. That is genuinely useful and lets agents resume after failures. But it is worth being precise: checkpointing graph state per super-step is a different and somewhat weaker guarantee than exactly-once step replay from a journal across an arbitrary crash. For many agents the checkpoint is enough; for agents that move money or send irreversible side effects, you generally want a dedicated durable execution layer underneath the framework.
How to choose a durable execution layer for your agent
There is no single winner, only the right match for your failure fear and ops budget
Pick based on your dominant failure fear and your tolerance for operations: Temporal if you need proven scale and the OpenAI Agents SDK integration, Restate if you want a single binary that fits serverless, and DBOS if you already run Postgres and want the least infrastructure possible. Durable execution for AI agents is a decision you make once and live with for years, so it pays to map it to your actual constraints rather than the loudest brand.
Start with the failure mode. If your worst case is a multi-day agent silently losing state, you want strong replay and event history, and Temporal’s model is purpose-built for it. If your worst case is operating one more stateful cluster, DBOS removes the server entirely. If you are deploying to the edge or to serverless functions and want one artifact everywhere, Restate’s single binary is the natural fit. Then layer in the integration you will actually use: a Python shop standardizing on the OpenAI Agents SDK gets the most free leverage from Temporal’s GA wrapper, while a TypeScript serverless team may find Inngest or Restate a smoother path.
Whatever you choose, hold the line on the non-determinism discipline. Every engine here only works because LLM calls, tool calls, and external side effects are pushed into recorded steps that run once and replay from the log. Get that boundary right and any of these engines will keep your agent alive through a crash, a model timeout, or a human-in-the-loop pause. Get it wrong and no engine can save you.
Builder’s take
I have shipped enough long-running agents on Cyntr and Loomfeed to know that the demo-to-production gap is almost never the model. It is the plumbing underneath the model. Here is how I think about choosing this layer.
- The question is not which engine is best, it is which failure you are most afraid of. If your nightmare is a multi-day agent silently dropping state at hour 30, you want replay and event history, and that points at Temporal. If your nightmare is operating yet another stateful cluster, that points at DBOS.
- Match the footprint to the team, not the logo. A two-person team running an agent on top of a Postgres they already operate should not be standing up a Cassandra-backed Temporal cluster. DBOS as a library is genuinely less to babysit, and that matters more than peak throughput you will never hit.
- The non-determinism rule is universal and non-negotiable. Every one of these engines makes you push the LLM call, the tool call, and the API hit into a step or activity so it is recorded once and replayed from the journal, never re-run. If a vendor hand-waves this, walk away.
- Beware framework checkpoints masquerading as durable execution. LangGraph checkpoints state per super-step, which is real and useful, but it is not the same guarantee as exactly-once step replay across a crash. Know which one you are buying.
- Pick for the integration you will actually use. The OpenAI Agents SDK plus Temporal Python SDK integration going GA in March 2026 is the kind of thing that quietly decides architectures, because it removes the glue code that usually rots. I weight shipped integrations far higher than roadmaps.
Frequently asked questions
Durable execution for AI agents is an infrastructure layer that persists each step of an agent’s progress to durable storage before the next step runs, so the agent can survive a process crash, a model timeout, or a long human-in-the-loop pause and resume exactly where it left off without re-running side effects like payments or emails. Temporal, Restate, and DBOS are the leading engines that provide it.
They wrap every non-deterministic operation (LLM calls, tool calls, external API calls) in a recorded step or activity. The step runs exactly once, its result is written to a journal or event history, and after a crash the engine reuses that recorded result instead of re-executing the call. Temporal calls these activities and replays from event history; Restate journals each step; DBOS checkpoints @DBOS.step() outputs into Postgres.
The main difference is the orchestration server. Temporal runs a multi-service cluster (or Temporal Cloud) that sits on the critical path of execution, giving you proven scale (9.1 trillion lifetime actions) at a high operational cost. DBOS runs no server at all; it is a library that checkpoints workflow state into your own Postgres, giving you the lowest operational footprint but a shorter scale track record. Choose Temporal for scale and integrations, DBOS for minimal infrastructure.
Yes. Restate Cloud opened to everyone on September 30, 2025. Pricing is usage-based, billed on durable actions, with a free tier of 50,000 actions per month and no credit card required. State reads and writes via ctx.get and ctx.set are not counted as billable actions. Restate ships as a single self-contained binary that runs from a laptop to multi-region clusters and deploys to serverless platforms like Cloudflare Workers and Vercel Functions.
LangGraph 1.0 provides durable execution by checkpointing graph state at every super-step to a backend like PostgresSaver, keyed by thread_id, so agents can resume after failures. For many agents that is sufficient. But per-super-step checkpointing is a somewhat weaker guarantee than exactly-once step replay from a journal. For agents that move money or trigger irreversible side effects, teams typically run a dedicated durable execution layer like Temporal, Restate, or DBOS underneath the framework.
Inngest uses step-level memoization (each step runs once, the result is persisted, and completed steps are skipped on retry) and adds AI primitives like step.ai.infer and step.ai.wrap, though its step-based pricing can get expensive with many model calls. Hatchet is a YC-backed managed durable task queue purpose-built for AI pipelines, with DAG-based task graphs, streaming outputs, and priority lanes. Both are credible reference points alongside the primary trio of Temporal, Restate, and DBOS.
Primary sources
- Temporal raises $300M Series D at a $5B valuation — Temporal
- Temporal raises $300M, hits $5B valuation — GeekWire
- Production-ready agents with the OpenAI Agents SDK plus Temporal — Temporal
- Restate Cloud is Open to Everyone — Restate
- What is Durable Execution? A Definitive Guide — Restate
- Why DBOS? — DBOS
- Running Durable Workflows in Postgres using DBOS — Supabase
- Durable Workflow Platforms for AI Agents and LLM Workloads — Render
- Durable Execution: The Key to Harnessing AI Agents in Production — Inngest
- Hatchet: orchestration engine for background tasks, AI agents, durable workflows — GitHub / Hatchet
- Durable execution documentation — LangChain
- Gartner Predicts 40% of Enterprise Apps Will Feature Task-Specific AI Agents by 2026 — Gartner
Last updated: June 1, 2026. Related: Agent Infrastructure.




