

A hands-on guide to engineering cache hits: breakpoint placement, the dynamic-content-first mistake, TTL trade-offs, and the cross-provider cost math that decides whether a 1-hour write ever pays back.
What prompt caching actually does and why agents need it
Prompt caching lets a provider skip re-processing the identical leading tokens of a request and bill them at roughly one-tenth the normal input rate, so an agent that reuses a fixed system prompt and tool schema on every turn can cut input costs by up to 90%. For a chatbot answering one-off questions this is a marginal optimization. For an agent, it is structural: agents replay a large, near-static context (system instructions, tool definitions, retrieved documents, prior turns) on every single step of a loop, and without caching you pay full freight for the same tokens hundreds of times.
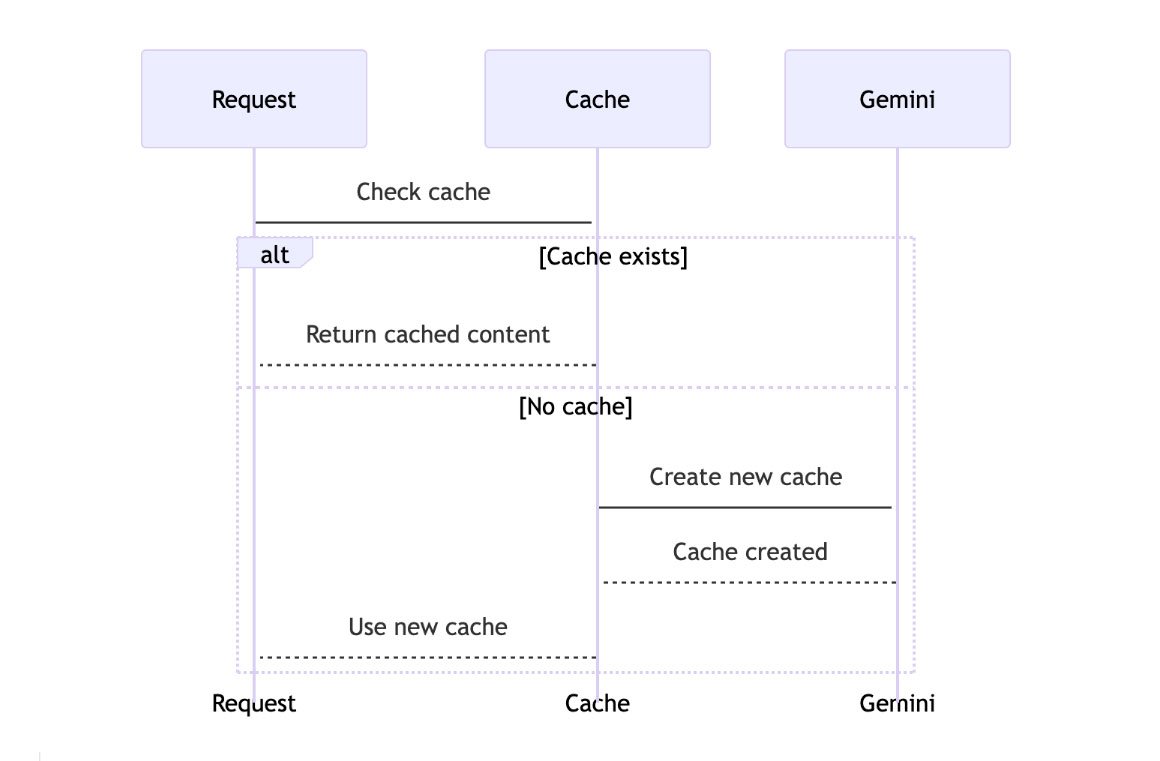
The mechanism is a prefix match. The provider hashes the leading byte sequence of your request; if a recent request shared the same prefix, the already-computed key/value attention state is reused instead of recomputed. The model still ‘sees’ those tokens, but you are billed the cached rate. The catch that trips up almost everyone is the word prefix: caching only works left-to-right from the start of the prompt. The moment a single token differs, every token after it is a cache miss.
That single fact drives every decision in this guide. Where you put your cache breakpoints, how you order static versus dynamic content, which TTL you pick, and how the cost math shakes out across Anthropic, OpenAI, and Google all reduce to one question: how long can you keep the leading bytes of your request byte-for-byte identical across calls?
Caching rewards a long, stable prefix and a short, volatile suffix. Your entire job as an engineer is to keep everything that changes per-request at the very end of the prompt.
The dynamic-content-first mistake that kills your hit rate
The most common and most expensive prompt caching bug is placing dynamic content (a timestamp, a user ID, a session UUID, retrieved chunks) before your static system prompt, which invalidates the cache on every request and drops your hit rate to near zero. Because caching is prefix-based, a single varying token near the front of the prompt poisons everything that follows it. A 6,000-token system prompt that should cost you the cache-read rate instead gets fully re-billed because someone prepended a 12-character timestamp.
The fix is an ordering discipline, not a feature toggle. Sort your prompt blocks from most-stable to least-stable, front to back. Tool definitions and the system persona change rarely, so they go first. A large retrieved document that is stable for a session goes next. The current user message, the live timestamp, and per-request metadata go dead last. The cache breakpoint then lands on the boundary between the stable prefix and the volatile tail.
Watch for the silent variants of this mistake. JSON key ordering that is non-deterministic across serializations. A ‘Current time: …’ line injected into the system prompt ‘for context.’ Tool schemas regenerated in a different order each boot. Few-shot examples shuffled for ‘diversity.’ Each of these changes the leading bytes and quietly converts your cache reads back into full-price writes. The code block below shows the wrong and right orderings side by side.
from anthropic import Anthropic
client = Anthropic()
# WRONG: a live timestamp at the front invalidates the entire prefix
# every single request -> ~0% cache hit rate.
bad_system = [
{"type": "text", "text": f"Current time: {now_iso()}"}, # changes every call
{"type": "text", "text": BIG_STATIC_SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"}}, # never gets to cache
]
# RIGHT: stable content first, volatile content last,
# breakpoint on the last STABLE block.
good_system = [
{"type": "text", "text": BIG_STATIC_SYSTEM_PROMPT}, # stable
{"type": "text", "text": STABLE_POLICY_AND_TOOLS_DOC,
"cache_control": {"type": "ephemeral"}}, # breakpoint here
]
resp = client.messages.create(
model="claude-opus-4-8",
max_tokens=1024,
system=good_system,
messages=[
# The volatile, per-request content lives at the very end.
{"role": "user", "content": [
{"type": "text", "text": f"[Current time: {now_iso()}]\n{user_turn}"}
]},
],
)
print(resp.usage) # inspect cache_read_input_tokens vs cache_creation_input_tokensWhere to place cache breakpoints (the rules that actually matter)
On the Claude API you get up to four cache breakpoints per request, they must follow the request hierarchy (tools, then system, then messages), and each one should sit on the last block that stays identical across calls. A breakpoint is not ‘cache from here forward’ in isolation; it marks the end of a cacheable prefix. The provider then checks up to 20 blocks backward from each breakpoint to find a previously cached entry, so you do not have to mark every block, only the boundaries that matter.
The practical pattern for an agent is two breakpoints. Put the first on the end of your tool definitions, which essentially never change. Put the second on the end of your stable conversation context, just before the live turn. This gives you a long-lived outer cache for tools and a shorter-lived inner cache that grows as the conversation does. The four-breakpoint ceiling exists so you can do incremental caching of a growing message history, marking each new stable turn as it becomes part of the fixed prefix.
Mind the minimum cacheable length. On current large models the floor is meaningful: Claude Opus 4.8, 4.7, 4.6, and 4.5 require at least 4,096 tokens before a block is eligible, while Sonnet 4.6 and 4.5 cache from 1,024. Below the threshold nothing errors; you just silently get no caching, with both cache_creation_input_tokens and cache_read_input_tokens reading zero in the usage object. If your prefix is short, pad it with content you would send anyway rather than fragmenting it across breakpoints.
OpenAI and Gemini behave differently here, and the difference is worth internalizing. OpenAI’s prompt caching is fully automatic on GPT-5-family models with no cache_control parameter at all; if a request reuses a prefix the platform already computed, the cached tokens bill at the reduced rate with no code change and no write premium. Gemini offers both implicit caching (automatic) and explicit caching (you create a cache resource and reference it), charges hourly storage on explicit caches, and counts cache hits in 128-token increments above a per-model minimum.
| Capability | Anthropic (Claude API) | OpenAI (GPT-5 family) | Google (Gemini) |
|---|---|---|---|
| Activation | Explicit cache_control breakpoints | Automatic, no code change | Implicit (auto) or explicit cache resource |
| Cache read price | 0.1x base input | ~0.1x base input (90% off) | 0.1x base input (Gemini 2.5+) |
| Cache write premium | 1.25x (5m) or 2x (1h) | None | None on read; explicit adds hourly storage |
| Breakpoints / control | Up to 4 per request | None (prefix auto-detected) | Explicit cache handle or implicit |
| Min cacheable tokens | 1,024-4,096 by model | 1,024 | >=1,024 (varies by model); 128-token hit increments |
| TTL control | 5m default, 1h via ttl + beta header | Provider-managed (minutes) | Configurable on explicit caches |
TTL trade-offs and the 1-hour write premium
On Anthropic, the default cache lives 5 minutes and its write costs 1.25x base input, while the optional 1-hour cache write costs 2x base input, so the longer TTL only pays back if the cached prefix is read at least two more times inside that hour. The 1-hour window is opt-in: you add ttl to the cache_control object and send a beta header. Get the math wrong and you pay double for a prefix that expires unused; get it right on a steady high-frequency agent and you eliminate cold-start re-writes that would otherwise recur every few minutes.
The break-even logic is simple arithmetic. Without caching, N reuses of a prefix cost N times the base rate. With a 1-hour cache, you pay 2x once to write plus 0.1x per read; that beats paying full price once you have read the cache about twice (2 + 0.1N < N+1 solves to N > ~1.1). With the 5-minute cache you pay 1.25x to write, so you come out ahead after a single reuse. The 1-hour window’s value is therefore not lower per-read cost (the read rate is identical) but avoiding repeated writes during quiet gaps in traffic.
This is exactly the trap behind one of 2026’s most-discussed caching incidents. Around early March 2026 (the regression traces to roughly March 6-8) Claude Code’s default cache TTL silently dropped from 1 hour to 5 minutes. Long coding sessions that previously held a warm cache across pauses now re-wrote the prefix repeatedly, and an analysis attached to GitHub issue #46829 estimated a ~17% average overpayment over the affected period, with March overpayment as high as ~26% and some users hitting their 5-hour subscription quota limits for the first time. The April 2026 Claude Code update restored the longer window via the ENABLE_PROMPT_CACHING_1H environment variable, which works across the API key, Bedrock, Vertex, and Foundry configurations.
The lesson for agent builders is to make TTL an explicit, monitored decision rather than an inherited default. If your agent fires steadily every few seconds, the 5-minute cache rarely expires between calls and the 1-hour premium is wasted money. If your agent is bursty with multi-minute gaps but high reuse within a session, the 1-hour write is cheaper than eating a fresh write on every burst. Measure your actual inter-request gap distribution before choosing.
“The 1-hour cache does not make reads cheaper. It makes writes rarer. Buy it only when your traffic has gaps longer than five minutes.”
On the Anthropic TTL trade-off
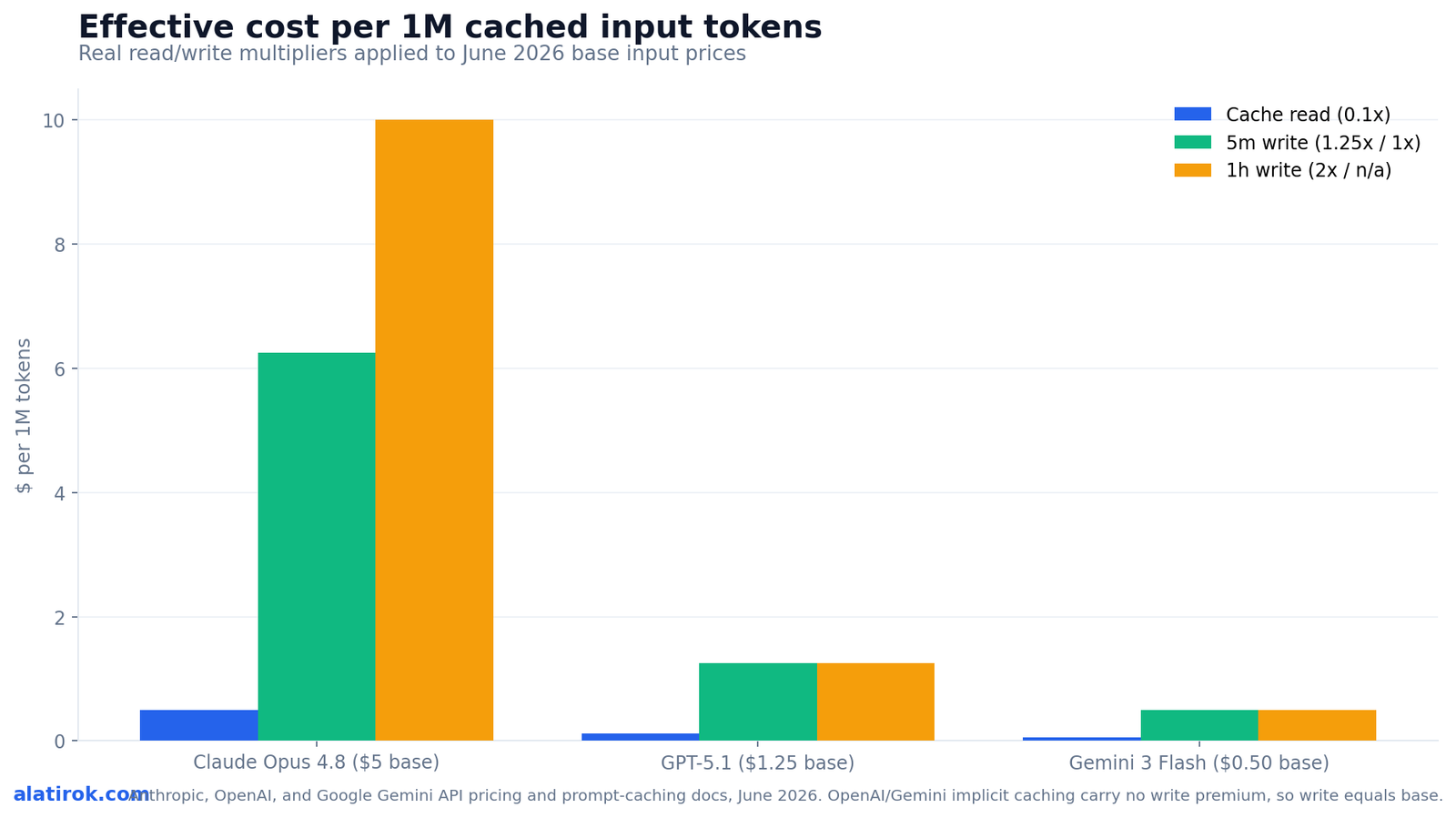
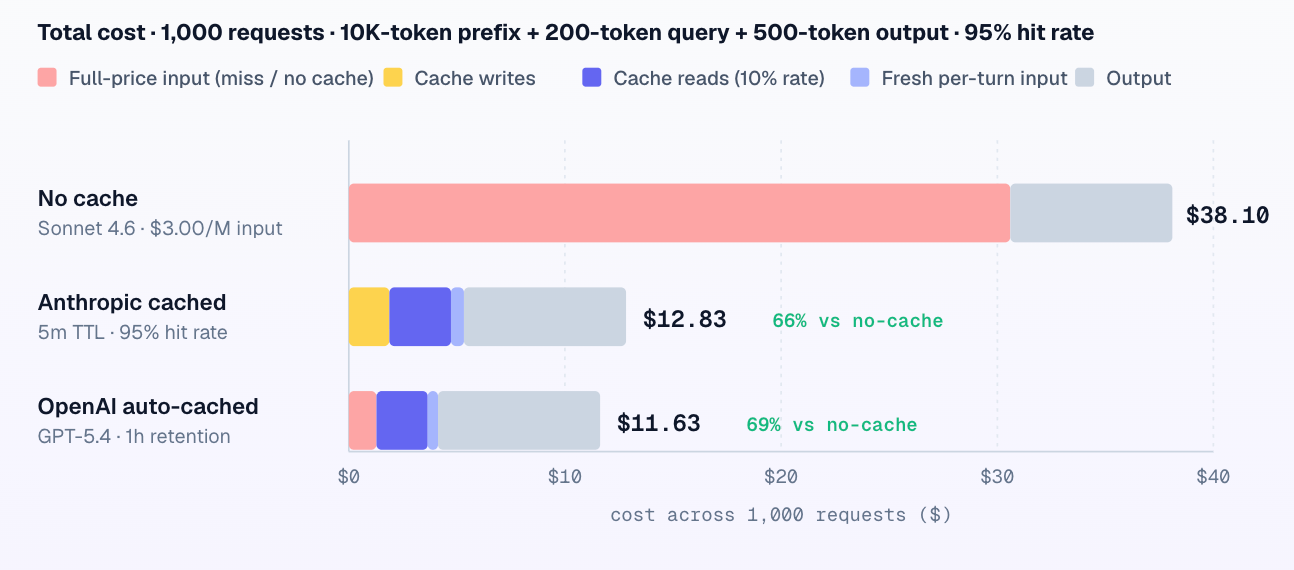
Cross-provider cost math: what a cached token really costs
0.1x
Cache read multiplier
vs base input, all three providers
2x
Anthropic 1h cache write
1.25x for the 5-minute default
~$21.60
Saved per day
on a $24/day uncached system prompt
~2
Reads to break even
on Anthropic’s 1h write premium
Because cache reads bill at roughly 0.1x base input on all three providers, the cheapest cached token belongs to whichever model has the lowest base input price, but Anthropic’s write premium changes the break-even point in a way OpenAI and Gemini implicit caching do not have. The chart below applies the real multipliers to real June 2026 base input prices: Claude Opus 4.8 at $5/MTok, GPT-5.1 at $1.25/MTok, and Gemini 3 Flash at $0.50/MTok. The write-versus-read gap is what determines whether caching is a no-brainer or a calculated bet.
Notice the asymmetry. OpenAI charges no write premium and no storage fee, so on GPT-5-family models caching is pure upside the instant a prefix repeats; there is no scenario where it costs you more than not caching. Anthropic’s explicit model trades that simplicity for control: you choose exactly what gets cached and for how long, but you accept a 1.25x or 2x write cost that you must amortize. Gemini’s implicit caching mirrors OpenAI’s free upside, while its explicit caching adds an hourly storage charge in exchange for a guaranteed hit when referenced.
Run the worked example that appears across the cost guides. A system prompt large enough to cost $24/day in uncached input drops to about $2.40/day once cached at the 0.1x read rate, a saving of roughly $21.60/day, or about $650/month, on a single agent’s system prompt alone. Multiply that across every agent instance and every tool-heavy turn and caching stops being an optimization and becomes the price of being in business. The break-even series in the chart shows how few reuses it takes for even Anthropic’s 2x write to pay for itself.
A working setup: breakpoints, ordering, and the 1-hour header
To cache reliably on the Claude API, structure tools and system as a stable prefix, mark the last stable block with cache_control, opt into the 1-hour TTL with both the ttl field and the beta header, and verify the hit on every response via the usage object. The code below shows the full request shape an agent loop should send, with two breakpoints (one on tools, one on stable context) and the 1-hour window enabled.
The single most important line is not in the request body at all; it is the assertion on usage. After the first call you expect a non-zero cache_creation_input_tokens (the write) and zero reads. On every subsequent call within the TTL you expect cache_read_input_tokens to dominate and cache_creation_input_tokens to fall to zero. If you ever see creation tokens repeating call after call, your prefix is changing somewhere and you are paying the write premium on a loop, exactly the failure mode behind the Claude Code TTL regression.
For a multi-tenant agent platform, layer cache isolation onto this. As of February 5, 2026, Anthropic isolates caches per workspace within an organization on the Claude API, Claude Platform on AWS, and Microsoft Foundry (beta), while Bedrock and Vertex AI remain organization-level only. Different organizations never share caches anywhere. The practical move is one workspace per tenant: a shared system prefix can be cached and reused safely across requests for that tenant without any risk of a cache hit leaking another tenant’s context.
import anthropic
# The beta header opts into the 1-hour cache window.
client = anthropic.Anthropic(
default_headers={"anthropic-beta": "extended-cache-ttl-2025-04-11"}
)
resp = client.messages.create(
model="claude-opus-4-8",
max_tokens=1024,
tools=[
# ... full tool schema ...
# Breakpoint 1: end of the (very stable) tool definitions.
{"name": "final_tool", "description": "...", "input_schema": {},
"cache_control": {"type": "ephemeral", "ttl": "1h"}},
],
system=[
{"type": "text", "text": BIG_STATIC_SYSTEM_PROMPT},
# Breakpoint 2: end of stable session context, 1-hour TTL.
{"type": "text", "text": STABLE_SESSION_CONTEXT,
"cache_control": {"type": "ephemeral", "ttl": "1h"}},
],
messages=[
# Volatile, per-turn content only -- never cached, always last.
{"role": "user", "content": user_turn},
],
)
u = resp.usage
# On a hit, reads dominate and creation is ~0. Alert if creation repeats.
hit_rate = u.cache_read_input_tokens / max(
1, u.cache_read_input_tokens + u.cache_creation_input_tokens
)
print(f"cache hit rate this call: {hit_rate:.1%}")
assert u.cache_creation_input_tokens == 0 or first_call, \
"Prefix changed -- you are re-writing the cache and paying the write premium"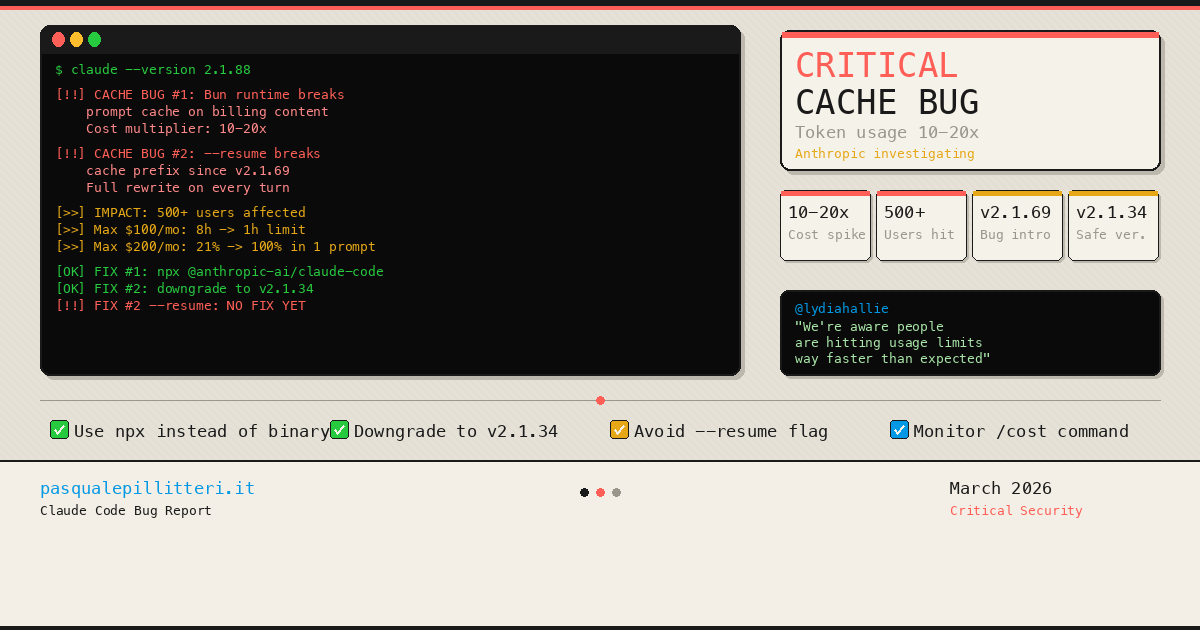
My cache_read_input_tokens is always 0 even though my prompt is huge
Either your prefix changes every call (a timestamp, non-deterministic JSON key order, a regenerated tool schema), or your cacheable block is below the model minimum (4,096 tokens on Opus 4.5-4.8, 1,024 on Sonnet). Diff the raw request bytes across two consecutive calls; the first differing byte is where your prefix breaks.I added ttl: 1h but still see 5-minute behavior / quota spikes
The 1-hour window requires the beta header (anthropic-beta: extended-cache-ttl-2025-04-11) in addition to the ttl field. In Claude Code specifically, set ENABLE_PROMPT_CACHING_1H=1; the early-March 2026 regression (issue #46829) silently reverted the default to 5 minutes until the April update exposed this flag across API key, Bedrock, Vertex, and Foundry.Caching works locally but my multi-tenant platform shows misses
Check your isolation boundary. Anthropic caches are isolated per workspace (Claude API / AWS / Foundry) or per organization (Bedrock / Vertex) as of Feb 5, 2026. If you route tenants through one workspace expecting separate caches, or across workspaces expecting a shared cache, your hit pattern will surprise you. Map one workspace per isolation unit.Should I use OpenAI/Gemini implicit caching or explicit caching?
If you cannot guarantee a stable prefix or you want zero code, implicit/automatic caching (OpenAI GPT-5 family, Gemini implicit) is free upside with no write premium. Use Gemini explicit caching when you have a large, reused context and want a guaranteed hit; you trade an hourly storage fee for the guarantee. On Anthropic you always control caching explicitly via cache_control.Pros, cons, and the decision that scales
Prompt caching is close to free money for any agent with a stable prefix, but Anthropic’s explicit model rewards engineering discipline and punishes sloppy prompt ordering, while OpenAI and Gemini implicit caching trade that control for zero-effort savings. The right choice depends on how much you can stabilize your prefix and how much control you need over what gets cached and for how long.
Pros
Cons
The Claude Code TTL regression cost users ~17% on average precisely because no one was watching cache_creation vs cache_read. Wire that ratio into your dashboards before you ship a caching change, not after.
Builder’s take
I run Cyntr, which fires the same multi-thousand-token system prompt and tool schema at a model thousands of times an hour. Caching is not a nice-to-have there; it is the difference between a viable unit economic and a dead one. A few things I have learned the hard way building Cyntr and Loomfeed:
- Treat your prompt like a build artifact: everything stable goes in a fixed prefix, everything per-request goes at the very end. If you can’t draw a clean line between the two, your hit rate will be garbage no matter how many breakpoints you add.
- Log cache_read_input_tokens vs cache_creation_input_tokens on every call from day one. I have watched a ‘working’ cache quietly drop to a 10% hit rate after a refactor reordered two system blocks, and without the metric you never see it.
- Do the break-even arithmetic before reaching for the 1-hour TTL. On Anthropic a 1h write costs 2x base; if a cached prefix is read fewer than two more times inside the hour, you lost money. For bursty agents the default 5-minute window is usually the right call.
- On a multi-tenant platform, cache isolation is a correctness and a cost question. Anthropic’s move to workspace-level isolation (Feb 5, 2026) means I can map a workspace per tenant and share a cached prefix safely within it, without leaking across tenants.
Frequently asked questions
Prompt caching reuses the already-computed leading tokens (the prefix) of a request so the provider does not reprocess them. Cache reads bill at roughly 0.1x the base input rate on Anthropic, OpenAI GPT-5-family, and Gemini 2.5+ models, a 90% discount. A worked example from provider cost guides shows a $24/day uncached system prompt dropping to about $2.40/day once cached.
Put the breakpoint on the last block that stays identical across requests. Order content from most-stable to least-stable: tools first, then system prompt and stable context, then the volatile per-request message last. On the Claude API you get up to four breakpoints per request and they must follow the tools, system, messages hierarchy; the provider checks up to 20 blocks back from each breakpoint to find a cached entry.
It is placing changing content (a timestamp, user ID, session UUID, or retrieved chunk) before your static system prompt. Because caching is prefix-based, one varying token near the front invalidates everything after it, dropping your hit rate to near zero. The fix is to move all per-request content to the very end of the prompt and cache the stable prefix.
The 1-hour cache write costs 2x base input versus 1.25x for the 5-minute default, while reads cost 0.1x either way. The longer window pays back only if the prefix is read about two more times within the hour, and its real value is avoiding repeated writes during traffic gaps longer than five minutes. For steady, high-frequency agents the 5-minute default is usually cheaper.
Around early March 2026 (roughly March 6-8) Claude Code’s default cache TTL silently dropped from 1 hour to 5 minutes, causing caches to be re-written more often. An analysis in GitHub issue #46829 estimated about 17% average overpayment over the affected period, with some subscription users hitting quota limits. The April 2026 update restored the longer window via the ENABLE_PROMPT_CACHING_1H environment variable.
As of February 5, 2026, Anthropic isolates prompt caches per workspace within an organization on the Claude API, Claude Platform on AWS, and Microsoft Foundry (beta); Bedrock and Vertex AI use organization-level isolation. Different organizations never share caches anywhere. For a multi-tenant platform, mapping one workspace per tenant lets a shared system prefix be cached and reused safely without cross-tenant leakage.
Primary sources
- Prompt caching — Anthropic Claude API Docs
- Pricing — Anthropic Claude API Docs
- Cache TTL silently regressed from 1h to 5m (Issue #46829) — anthropics/claude-code on GitHub
- Prompt caching — OpenAI API Docs
- Context caching – generateContent API — Google AI for Developers
- Gemini Developer API pricing — Google AI for Developers
- Claude Opus 4.8: a modest but tangible improvement — Simon Willison
Last updated: June 1, 2026. Related: Agent Infrastructure.




