


Seven LLM gateways, ranked for engineers wiring multi-provider routing in 2026 — the real self-host-vs-SaaS tradeoff, latency overhead, fallback under outages, and a clear pick-when verdict.
What is the best LLM gateway in 2026?
The best LLM gateway in 2026 is LiteLLM if you self-host, OpenRouter if you want the fastest multi-provider access with no infrastructure, and Portkey if you need built-in guardrails and governance. Those three cover roughly 90% of teams, but the honest answer depends on one load-bearing decision you have to make before reading a single feature table: do you want to operate the proxy yourself, or pay someone to run it?
Everything else — model count, dashboards, prompt management — is downstream of that. A gateway sits on the hot path between your application and every model provider, normalizing them to one OpenAI-compatible API, handling retries and fallback when a provider 500s, and giving you one place to track spend and enforce policy. The problem with most “best LLM gateway” lists is that they’re written by gateway vendors who crown themselves, list features in a grid, and never tell you what the choice actually costs you in latency, lock-in, or operational toil.
This ranking is for the engineer wiring multi-provider routing right now and deciding self-host versus SaaS proxy. We rank seven real options on the four things that decide it in production: deployment model, latency overhead the proxy adds, fallback and retry behavior under a provider outage, and total cost. We also cover Cloudflare AI Gateway, Kong, and AWS Bedrock — three serious production options the vendor comparisons routinely omit because they don’t fit a tidy three-way fight.

Do you want to run the proxy yourself? Yes, and you already have Postgres + Redis -> LiteLLM. No, you want zero infra and the most models fastest -> OpenRouter. You need PII redaction, jailbreak detection, and audit trails in the gateway layer -> Portkey. Everything else is a tiebreaker.
LLM gateway comparison table: LiteLLM vs Portkey vs OpenRouter and more
The fastest way to read the field: LiteLLM and Portkey’s gateway are open-source and self-hostable; OpenRouter and Cloudflare are SaaS-first; Kong and Bedrock are infrastructure you likely already run. The decision matrix below maps each gateway to deployment model, provider/model reach, pricing, built-in guardrails, and native fallback — plus the one situation each one wins.
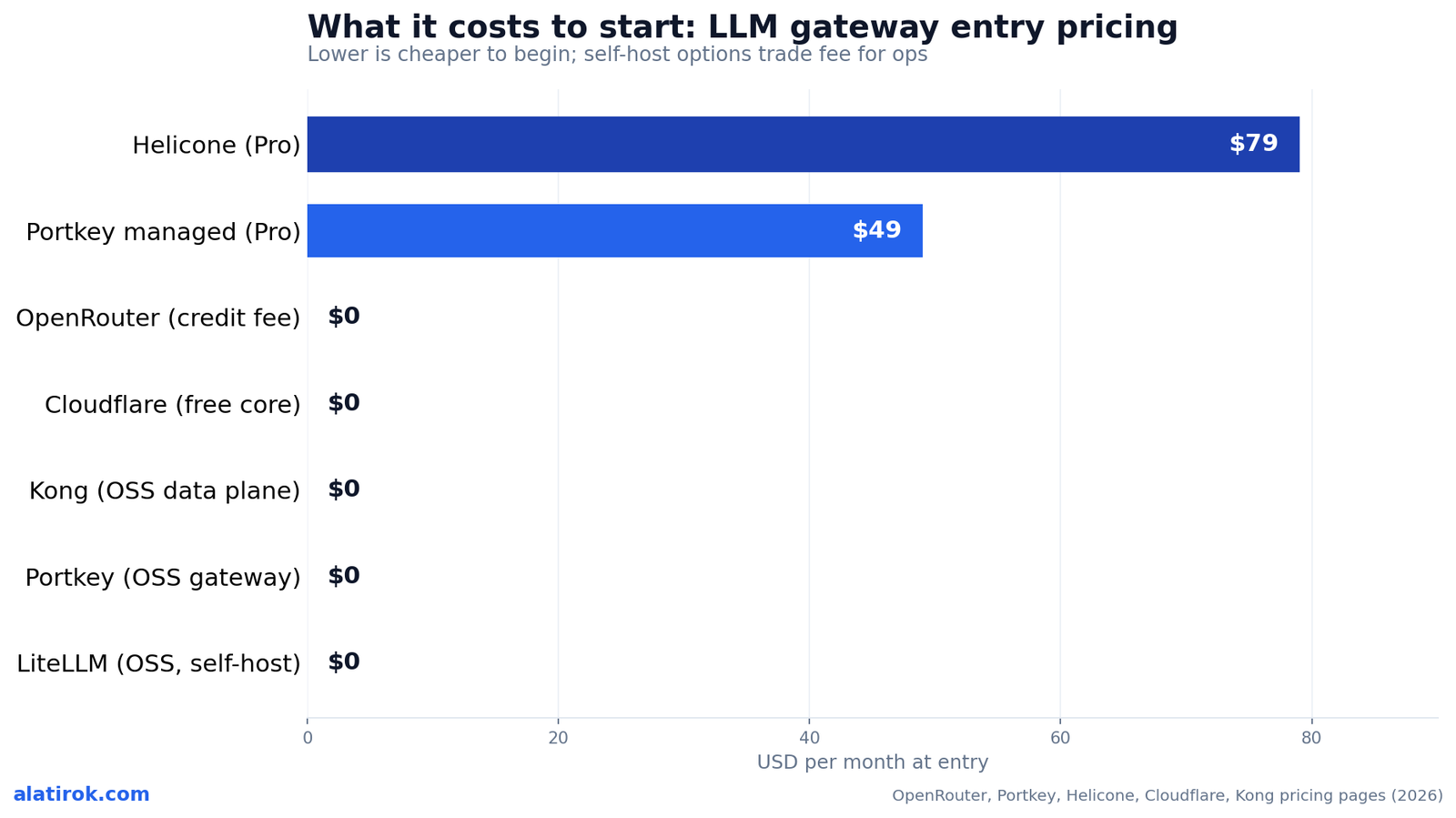
A few numbers worth pinning down before you trust any grid. OpenRouter advertises 400+ models across 60+ providers at provider token prices plus a 5.5% fee on credit purchases, with 25+ free models and no monthly minimum. Portkey’s open-source gateway routes 1,600+ model variants with 50+ guardrails and went fully Apache 2.0 in March 2026; the managed control plane starts free and goes to $49/mo. Helicone’s free tier is 10K requests/month with Pro at $79/mo. These are the figures that move the decision, and they change — re-check the pricing pages before you commit.
“The gateway is a hop on your hot path. Every millisecond and every 500 it adds is yours to own.”
Surya Koritala, founder of Cyntr and Loomfeed
| Gateway | Deploy model | Providers / models | Pricing model | Built-in guardrails | Fallback + retry | Pick it when |
|---|---|---|---|---|---|---|
| LiteLLM | Self-host (SDK + proxy); managed tier exists | 100+ providers | Open-source, you operate (Postgres + Redis at scale) | Partial (hooks, integrations) | Yes — router order + retries + fallbacks | You self-host and want an OpenAI-compatible standard |
| OpenRouter | SaaS only | 60+ providers / 400+ models | Provider price + 5.5% credit fee, no minimum | No | Yes — automatic provider fallback | You want the most models, fastest, with zero infra |
| Portkey | Self-host (Apache 2.0) or managed | 250+ providers / 1,600+ models | OSS free; managed free -> $49/mo | Yes — 50+ guardrails, PII, jailbreak | Yes — conditional routing + fallbacks | You need guardrails and governance in the gateway |
| Helicone | Cloud or self-host | Provider-agnostic proxy | Free 10K req/mo -> $79/mo | Partial | Yes (gateway mode) | You want observability-first; note maintenance mode |
| Cloudflare AI Gateway | SaaS (edge) | Multi-provider passthrough | Free core; logs capped 100K/mo (Free) | Limited | Yes — caching + fallback | You want edge caching and rate limiting, free to start |
| Kong AI Gateway | Self-host (OSS data plane) / enterprise | Multi-LLM via plugins | OSS free; AI features need Enterprise | Yes — PII (20 categories), prompt guards | Yes — load balance + circuit breaking | You already run Kong for your API gateway |
| AWS Bedrock | Managed (AWS) | First-party + partner models | AWS usage-based | Guardrails for Bedrock | Yes — Intelligent Prompt Routing (GA) | You’re AWS-native and want in-cloud failover |
1. LiteLLM — best self-hosted LLM gateway
LiteLLM is the best LLM gateway for teams that self-host, because it is the de facto OpenAI-compatible standard: an open-source Python SDK and proxy that normalizes 100+ providers behind one endpoint, with routing, spend tracking, and access control you run in your own VPC. If you’ve ever seen a tool say “point it at any OpenAI-compatible base URL,” LiteLLM is what fills that slot for everything that isn’t literally OpenAI.
Operationally, it’s honest about being software you run. The router supports ordered deployments (order=1, order=2…), per-level retries that escalate to the next tier, and configured fallbacks when everything in a model group fails — the default is 3 retries per model group. Critically, LiteLLM exposes an x-litellm-overhead-duration-ms response header so you can measure exactly what the proxy adds to each request; published benchmarks put median overhead around 78ms on an EC2 g5.xlarge, and simple-shuffle routing is the recommended low-overhead default. At a few hundred requests per second, you’ll want Postgres and Redis behind it and a patching cadence for the Python proxy.
The catch is that those things are your job. There’s no SLA, no one to page, and tuning throughput past a few hundred RPS is real work. But you own the data plane completely, there’s no per-token markup, and the OpenAI-compatible surface means the rest of your stack — observability, eval harnesses, agent frameworks — just works.
Pros
Cons
2. OpenRouter — fastest multi-provider access (and its 5.5% markup)
OpenRouter is the best LLM gateway when you want the widest model access with zero infrastructure: one OpenAI-compatible endpoint to 400+ models across 60+ providers, billed at provider token prices plus a flat 5.5% fee on credit purchases, with no monthly minimum and 25+ free models. It is the fastest on-ramp in the category — sign up, buy credits, change a base URL, and you’re calling Claude, GPT, Gemini, and Llama through one key with automatic provider fallback.
The 5.5% is the number that decides whether OpenRouter stays in your stack. It’s charged when you purchase credits, not per request, and it’s genuinely cheap relative to the convenience: consolidated billing, a unified key, and failover across providers without you operating anything. For prototypes, spiky workloads, and anything where engineering time costs more than the markup, that math is overwhelmingly in OpenRouter’s favor.
Where it stops being optimal is steady, high-volume production. 5.5% on a six-figure annual inference bill is real money you could reclaim by self-hosting LiteLLM and going direct to providers — and OpenRouter is SaaS-only, so you can’t run it in your VPC for data-residency or air-gapped requirements. It also has no built-in guardrails layer. The clean pattern: start on OpenRouter, watch the bill, and migrate routing to LiteLLM when the markup, not the calendar, says it’s time.
OpenRouter’s 5.5% is on credit purchases, not a per-token surcharge on top of marked-up rates — token prices match going direct to the provider. That makes it the cheapest credit-purchase fee in the category, but it still compounds at high volume. Model the annualized number, not the per-call one.
3. Portkey — best LLM gateway for guardrails and governance
Portkey is the best LLM gateway when policy is the point: it bundles routing across 1,600+ model variants with 50+ built-in guardrails — PII redaction, jailbreak detection, content checks — plus audit trails and governance, and as of March 2026 the entire gateway is open-source under Apache 2.0. That last change matters: you can now self-host the core routing and guardrails for free and only pay for the managed control plane (analytics, prompt management, enterprise governance) if you want it.
This is the layer LiteLLM and OpenRouter don’t natively give you. If you’re in a regulated domain, shipping agents that touch customer data, or need to prove to a security review that prompts are screened and logged, Portkey’s guardrails being in the gateway — not bolted on in application code — is the differentiator. The company reports governing over 1 trillion tokens daily and $180M+ in annualized spend, so the routing path is battle-tested at scale.
Pricing on the managed side is a free prototyping tier, $49/mo for production, and custom enterprise. The trade-off versus LiteLLM is that you’re adopting Portkey’s worldview and its config surface; the trade-off versus OpenRouter is that you’re operating more (if self-hosting) or paying for a control plane. But if your blocker is “we can’t ship without guardrails,” nothing else on this list answers it as directly out of the box.
You don’t have to choose routing OR guardrails. A common 2026 pattern is LiteLLM for routing in the VPC with Portkey’s now-Apache-2.0 gateway or Kong’s PII plugins composed in for policy — keep the tw4-7. Helicone, Cloudflare AI Gateway, Kong, and Bedrock — the options vendors omit
The three-way LiteLLM-vs-Portkey-vs-OpenRouter fight ignores four production-grade options, and for some teams one of them is the right answer. Vendor blogs skip these because they don’t fit a clean narrative — but if you already run Kong, live on Cloudflare’s edge, or are AWS-native, the best gateway might be infrastructure you already own.
Helicone (#4) leads with observability — one line of code and it captures everything your LLM app does, in gateway or proxy mode, cloud or self-hosted, free up to 10K requests/month and $79/mo for Pro. Caveat worth knowing: after Mintlify’s acquisition in March 2026, Helicone moved into maintenance mode, so weigh roadmap risk before betting a long-lived integration on it.
Cloudflare AI Gateway (#5) is free at its core — analytics, caching, rate limiting, and reliability features for a one-line change — with the Free plan logging capped at 100,000 events/month (1M on Workers Paid). Its semantic-aware caching can cut latency dramatically on repeated requests, and 2026 added unified billing so you can pay third-party model usage through your Cloudflare invoice. Best when you want edge caching and rate limiting first and routing second.
Kong AI Gateway (#6) extends Kong’s enterprise API gateway with 60+ AI plugins: semantic routing, semantic caching, prompt guards, PII sanitization across 20 categories and 9 languages, plus load balancing with circuit breaking. The OSS data plane is Apache 2.0 and free to self-host, but the advanced AI features (semantic caching, deep analytics, compliance tooling) require Kong Enterprise. The obvious pick if Kong already fronts your APIs. AWS Bedrock (#7) isn’t a third-party gateway, but with Intelligent Prompt Routing now generally available and managed inference profiles offering in-region/global failover, it’s a legitimate routing-and-fallback layer for AWS-native shops — often wired together with LiteLLM as the Bedrock-fronting fallback target.
Helicone
Best for: Teams that want logging and analytics on the LLM path, fast
What works
Watch out for
Cloudflare AI Gateway
Best for: Apps already on Cloudflare wanting caching and cost control
What works
Watch out for
Kong AI Gateway
Best for: Enterprises standardized on Kong’s API gateway
What works
Watch out for
AWS Bedrock
Best for: Shops standardized on AWS wanting in-cloud failover
What works
Watch out for
What latency and fallback actually cost you (the part vendors skip)
A gateway adds latency and a new failure mode to every request, and choosing the best LLM gateway means budgeting for both — not just counting features. This is the analysis missing from self-crowning vendor posts, and it’s the part that bites you in production.
On latency: a self-hosted proxy is an extra network hop plus processing time. LiteLLM’s published median overhead is around 78ms on a g5.xlarge with simple-shuffle routing, and it exposes x-litellm-overhead-duration-ms so you can verify your own number rather than trust a benchmark. Edge gateways like Cloudflare can go the other direction — cached responses skip the provider entirely and cut latency by up to ~90% on repeats — but only for cacheable, repeated requests. SaaS proxies like OpenRouter add the round-trip to their infrastructure, which is usually negligible but is not zero and is outside your control.
On fallback: this is where a gateway earns its place. When a provider rate-limits or 500s mid-incident, you want automatic reroute, not a paged engineer. LiteLLM’s ordered-deployment fallback with per-level retries, OpenRouter’s automatic provider fallback, Portkey’s conditional routing, Kong’s circuit breaking, and Bedrock’s regional failover all solve this — but the quality differs. Test it deliberately: kill a provider in staging and watch whether requests reroute, how many retries fire, and what your p99 does under the storm. A gateway you haven’t failure-tested is a single point of failure wearing a reliability costume.
Self-host vs SaaS proxy: the verdict
Self-host? -> LiteLLM. Fastest access? -> OpenRouter. Need guardrails? -> Portkey.
Self-host an LLM gateway when you need data residency, want no per-token markup, and already run Postgres and Redis — that’s LiteLLM. Use a SaaS proxy when speed-to-first-call and zero ops matter more than the fee — that’s OpenRouter. Reach for a policy-heavy gateway when guardrails are a shipping blocker — that’s Portkey. The cost crossover is the thing to model: OpenRouter’s 5.5% is trivial at low volume and meaningful at high volume, while LiteLLM’s “free” carries real operational cost that’s trivial at high volume and annoying at low volume.
Don’t over-index on model count. 400 versus 1,600 models sounds decisive but almost no team uses more than a handful in production — routing quality, fallback behavior, and observability matter far more than the headline number. And remember the four omitted options: if you already live on Cloudflare, run Kong, or build on AWS, the best gateway may be the one you’re already paying for.
The composability point is the one I’d leave you with. These are not mutually exclusive. Routing and guardrails are separate decisions, and the strongest 2026 stacks treat them that way — LiteLLM or Bedrock for routing, Portkey or Kong for policy, Helicone or Cloudflare for caching and observability. Pick the load-bearing layer first, then compose.
Builder’s take
I run Cyntr’s orchestration engine and Loomfeed’s AI layer through a gateway, so this isn’t theoretical for me. The thing nobody on the vendor blogs says out loud: the gateway is a hop on your hot path. Every millisecond and every 500 it adds is yours to own. Here’s how I actually decide.
- If you already run Postgres and Redis, self-hosting LiteLLM is close to free and gives you the OpenAI-compatible surface everything else assumes — that’s my default for anything past a prototype.
- OpenRouter’s 5.5% is the cheapest credit-purchase fee in the category, and for the first month of a project, the time it saves dwarfs the markup. Migrate off it when the bill, not the calendar, tells you to.
- Treat guardrails as a separate decision from routing. You can run LiteLLM for routing and bolt Portkey’s now-Apache-2.0 gateway or Kong’s PII plugins on for policy — don’t buy a SaaS tier just to get a regex.
- Measure the overhead header on day one. LiteLLM exposes x-litellm-overhead-duration-ms; if you can’t see your proxy’s added latency, you’re flying blind into your own p99.
- Helicone going into maintenance mode after the Mintlify acquisition is a reminder: pick a gateway whose project will outlive your integration, or pick one you can fully self-host and fork.
Frequently asked questions
An LLM gateway is a proxy that sits between your app and one or more model providers, normalizing them to a single (usually OpenAI-compatible) API while handling routing, retries, fallback, spend tracking, and policy. You need one the moment you call more than one provider, want automatic failover when a provider has an outage, or need a single place to track cost and enforce guardrails. For a single-provider prototype, you can skip it.
Pick LiteLLM if you want to self-host an open-source, OpenAI-compatible proxy and already run Postgres and Redis. Pick OpenRouter if you want the fastest access to the most models with zero infrastructure and accept a 5.5% fee on credit purchases. Pick Portkey if you need built-in guardrails, PII redaction, and governance in the gateway layer — and note its gateway went fully open-source (Apache 2.0) in March 2026, so you can self-host it as well.
A self-hosted proxy adds a network hop plus processing time — LiteLLM’s published median overhead is around 78ms on an EC2 g5.xlarge with simple-shuffle routing, and it exposes an x-litellm-overhead-duration-ms header so you can measure your own number. SaaS proxies like OpenRouter add a round-trip to their infrastructure, usually small but outside your control. Edge gateways like Cloudflare can reduce latency on cached, repeated requests by up to ~90%.
At low or spiky volume, yes — the fee is charged on credit purchases (not as a per-token surcharge on marked-up rates), token prices match going direct to the provider, and the convenience of one key, consolidated billing, and automatic fallback usually outweighs the markup. At steady high volume, model the annualized cost: 5.5% on a six-figure inference bill is real money you could reclaim by self-hosting LiteLLM and calling providers directly.
For self-hosting without a markup, LiteLLM. For guardrails and governance, Portkey (now Apache 2.0). For observability-first, Helicone (free to 10K requests/month, though in maintenance mode after the Mintlify acquisition). For edge caching and rate limiting, Cloudflare AI Gateway (free core). For teams already on Kong or AWS, Kong AI Gateway or Amazon Bedrock with Intelligent Prompt Routing.
Self-host (LiteLLM, or Portkey/Kong’s open-source data planes) when you need data residency, want no per-token markup, or already operate Postgres and Redis — you trade vendor fees for operational ownership. Use a SaaS proxy (OpenRouter, Cloudflare, managed Portkey) when time-to-first-call and zero ops matter more than the fee, or when you don’t want to patch and scale a proxy yourself. The cost crossover, not the feature list, usually decides it.
Primary sources
- 6 best LLM gateways for developers in 2026 — Braintrust
- OpenRouter Pricing (5.5% fee, 400+ models, 60+ providers) — OpenRouter
- Portkey’s Gateway is Now Fully Open Source — GlobeNewswire
- Portkey-AI/gateway (1,600+ LLMs, 50+ guardrails, Apache 2.0) — GitHub
- Latency Overhead Troubleshooting (x-litellm-overhead-duration-ms) — LiteLLM Docs
- BerriAI/litellm (100+ LLM APIs, OpenAI format) — GitHub
- Cloudflare AI Gateway Pricing — Cloudflare Docs
- Kong AI Gateway — Kong
- Helicone Pricing — Helicone
- Use Amazon Bedrock Intelligent Prompt Routing — AWS Machine Learning Blog
- Best AI LLM Routers and OpenRouter Alternatives in 2026 — Pinggy
Last updated: June 2, 2026. Related: Agent Infrastructure.




