

DeepSeek V3 did more than post strong benchmark results. It gave the open-weight camp a concrete, high-profile proof point: a very large mixture-of-experts model, released with downloadable weights, that DeepSeek said was trained for about $5.6 million in final training compute and then followed by DeepSeek-R1, a reasoning model that quickly entered the mainstream AI conversation. The claims around cost need careful handling, and the market reaction often outran the facts. Still, the release changed how developers, investors, and closed-model competitors talk about the economics of advanced models. For broader context on deployment tradeoffs, see our open-source vs. closed AI agents analysis and our look at where Anthropic and OpenAI each lead.
DeepSeek V3 was the release that made open weights impossible to dismiss
671B
Total parameters in DeepSeek-V3
Per DeepSeek’s release materials
37B
Activated parameters per token
Per DeepSeek’s release materials
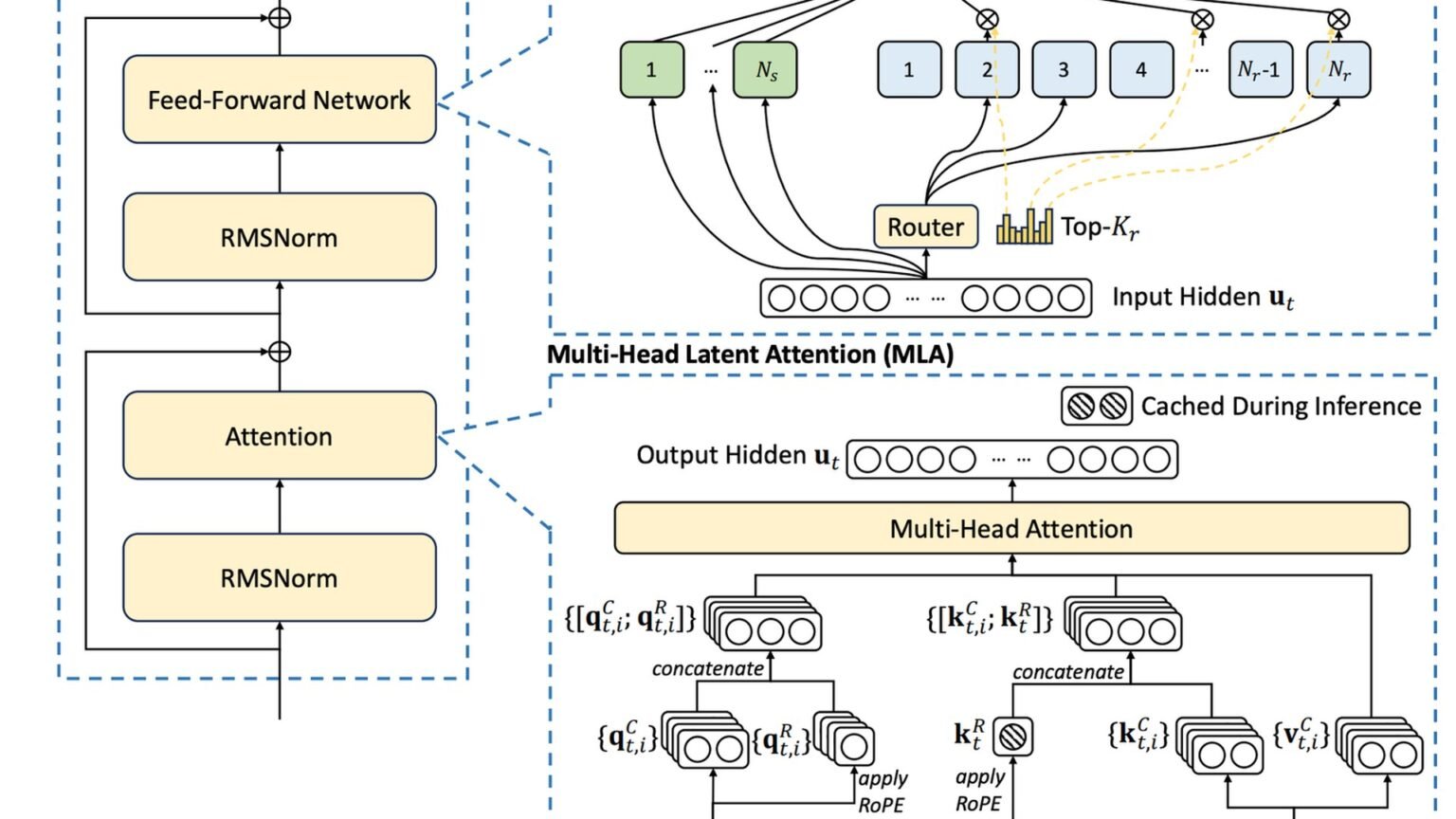
DeepSeek published DeepSeek-V3 on December 26, 2024, framing it as a 671B-parameter mixture-of-experts model with 37B activated parameters for each token. That architecture detail mattered because it pointed to a different scaling story than the one many outsiders had internalized from dense frontier models: very large total parameter counts, but a much smaller active footprint at inference time.
The company paired the release with open weights and a permissive license. In practice, that meant developers and researchers could inspect, run, and adapt the model in ways that are not available with API-only systems. For the open-weight community, V3 was not just another benchmark entry. It was evidence that a model positioned near the top tier of public evaluations could arrive outside the closed-lab distribution model.
The follow-on release amplified the effect. On January 20, 2025, DeepSeek announced DeepSeek-R1, describing it as a first-generation reasoning model and publishing both the main model and distilled variants. That sequence mattered more than either launch in isolation. V3 established the base-model credibility; R1 turned DeepSeek into a live reference point in the reasoning race.

📌 What is firmly verifiable. DeepSeek’s own release materials state that V3 is a 671B MoE model with 37B activated parameters, and that R1 was released in January 2025 with open-weight variants. Those claims are directly documented on DeepSeek’s official news pages.
“DeepSeek-V3 achieves a significant breakthrough in inference speed over previous models.”
DeepSeek-V3 release announcement
| Model | Release date | What DeepSeek said it shipped | Why it mattered |
|---|---|---|---|
| DeepSeek-V3 | 2024-12-26 | 671B MoE model, 37B activated parameters, open weights | Showed a frontier-scale open-weight base model could compete seriously |
| DeepSeek-R1 | 2025-01-20 | Reasoning model plus distilled variants | Extended the story from base-model quality to reasoning performance |
The $5.6 million training-cost claim changed the conversation, even with caveats
$5.576M
DeepSeek’s stated final-run training cost for V3
Company-reported estimate
2.788M
H800 GPU hours
Company-reported for V3 pre-training
The number mattered because it reset priors
The most repeated number from the V3 launch was not a benchmark score. It was cost. DeepSeek’s technical materials said the final training run for V3 used 2.788 million H800 GPU hours, which the company translated to roughly $5.576 million. That figure spread quickly because it appeared to undercut a core assumption behind the closed-model moat: that only the best-capitalized labs could afford to train systems near the frontier.
That does not mean the number should be treated as a full accounting of what it took to build DeepSeek-V3. Analysts and researchers noted that the figure described the final training run rather than every cost associated with research iteration, prior experiments, data work, engineering labor, and broader infrastructure. Those objections are material. A final-run compute number is not the same thing as total program cost.
Still, the distinction did not erase the strategic signal. Even if the headline figure was narrower than many readers assumed, DeepSeek had shown enough efficiency to force a repricing of expectations. The open-weight thesis no longer depended on the claim that open models would merely trail the frontier at lower cost. V3 suggested that open-weight teams could narrow the gap much faster than incumbents and investors had modeled.
⚠️ What remains disputed. The widely cited $5.6 million figure refers to DeepSeek’s stated cost for the final V3 training run, not a universally accepted estimate of total development cost. Readers should not treat it as a complete all-in budget unless a source explicitly says so.
| Claim | Source status | What readers should infer |
|---|---|---|
| 2.788M H800 GPU hours | Stated by DeepSeek | Verifiable as the company’s claim |
| ~$5.576M training cost | Stated by DeepSeek | Verifiable as a final-run compute estimate |
| Total cost to create V3 was $5.6M | Not established by official materials | Too broad without additional evidence |
R1 turned a model release into a market event
$600B
Approximate one-day Nvidia market value loss reported by Reuters
January 27, 2025
If V3 reframed the economics discussion, R1 turned DeepSeek into a market-moving story. DeepSeek’s January 2025 R1 announcement pushed the company into the center of the reasoning-model race, at a moment when investors were already primed to ask whether ever-larger infrastructure spending would translate cleanly into durable product advantage.
The market reaction was immediate and visible. Nvidia shares fell sharply on January 27, 2025, in a selloff widely linked to investor concern that DeepSeek’s progress could weaken the assumption that top-tier AI performance would require the same level of compute intensity and capital concentration the market had been pricing in. Reuters reported that Nvidia lost nearly $600 billion in market value in a single day, the largest one-day loss in U.S. stock market history at the time.
That reaction said as much about market positioning as it did about DeepSeek itself. One Chinese lab’s releases did not invalidate demand for accelerators, and Nvidia continued to argue that inference and post-training demand would remain strong. But the selloff showed how fragile one part of the AI bull case had become: the belief that model quality improvements would map almost directly to more chips, more capex, and more advantage for the largest closed labs.
Pros
Cons
📌 Why Nvidia became the proxy. DeepSeek did not need to threaten Nvidia’s business directly to move the stock. It only had to make investors question whether future model gains would require the same spending trajectory they had been assuming.
“Nvidia’s market value plunged by nearly $600 billion on Monday, the deepest ever one-day loss for a Wall Street stock.”
Reuters, January 27, 2025
Why V3 and R1 strengthened the open-weight thesis
Open weights became a strategic choice, not just a budget choice
Before DeepSeek V3, the strongest case for open-weight models was often framed in second-order terms: lower cost, more control, easier customization, less vendor lock-in. Those arguments still matter, especially for enterprises building internal agents and regulated workflows. What DeepSeek added was a first-order performance argument. Open weights were no longer just the practical option for teams willing to trade some quality for flexibility. They looked increasingly like a credible path to state-of-the-art or near-state-of-the-art capability in important categories.
That shift has consequences up and down the stack. Agent builders can fine-tune or distill open models for narrower tasks. Infrastructure vendors can optimize around known model internals instead of opaque APIs. Enterprises can evaluate deployment patterns that keep sensitive workloads inside their own environments. The application layer becomes less dependent on a small set of API providers when strong open-weight alternatives exist.
The strategic implication is not that closed labs stop mattering. OpenAI, Anthropic, and Google still retain advantages in frontier research, product distribution, safety systems, and integrated tooling. Our analysis of where Anthropic and OpenAI are each winning remains relevant because the closed-model leaders still shape the top end of the market. DeepSeek changed the slope of the race, not the fact of competition.
For developers and buyers, the more useful takeaway is that the old binary has weakened. The market is no longer cleanly split between frontier closed models on one side and merely good-enough open models on the other. DeepSeek helped create a middle zone where open-weight systems can be good enough for many production workloads and strategically superior because they are inspectable, portable, and adaptable. That is the terrain explored more broadly in our guide to open-source vs. closed AI agents in 2026.
| Open-weight thesis before V3 | What DeepSeek changed |
|---|---|
| Open models are cheaper and more customizable | Open models can also be central to top-tier performance discussions |
| Closed labs dominate frontier capability | Closed labs still lead in areas, but the gap can narrow faster than expected |
| Open weights are mainly for cost-sensitive teams | Open weights became strategically relevant for mainstream builders and enterprises |
What DeepSeek did not prove
The thesis changed, not the laws of AI economics
The strongest version of the DeepSeek story can drift into overstatement. V3 and R1 did not prove that all frontier-model development is suddenly cheap. They did not prove that data quality, talent concentration, and systems engineering no longer matter. They did not prove that open-weight releases automatically win enterprise adoption. They also did not settle the policy debate around export controls, model diffusion, or the safety tradeoffs of broadly available advanced weights.
There is also a practical deployment gap between publishing weights and operating a reliable product. Closed labs still offer managed APIs, enterprise support, integrated evals, safety layers, and broad ecosystem distribution. Many buyers will continue to prefer those bundles even if an open-weight model is technically competitive.
That is why DeepSeek’s real impact is best understood as a repricing of assumptions rather than a final verdict. The company demonstrated that the frontier is more contestable than many narratives suggested. It showed that efficiency gains can be strategically disruptive. It gave the open-weight movement a flagship moment. None of that means the race is over. It means the moat arguments now require more evidence.
⚠️ Avoid the simplistic read. DeepSeek weakened the claim that only closed labs can produce top-tier models. It did not prove that compute no longer matters or that open-weight models will dominate every layer of the stack.
Frequently asked questions
DeepSeek said DeepSeek-V3 is a 671B-parameter mixture-of-experts model with 37B activated parameters per token, released with open weights. Those details are documented in the company’s official announcement and linked technical materials.
What is verifiable is that DeepSeek’s materials describe about 2.788 million H800 GPU hours for the final V3 training run, which the company translated to roughly $5.576 million. That is not the same as a universally accepted estimate of total development cost. Readers should distinguish the company’s final-run compute claim from broader all-in cost interpretations. See DeepSeek’s V3 announcement for the original framing.
Investors interpreted DeepSeek’s releases as evidence that advanced model performance might be achievable with less compute spending than previously assumed. Reuters reported that Nvidia lost nearly $600 billion in market value on January 27, 2025, amid the DeepSeek-driven selloff. See Reuters’ coverage at this report.
No. DeepSeek strengthened the case that open-weight models can be highly competitive and strategically important, but it did not prove they will dominate every use case. Closed labs still retain advantages in managed products, safety systems, distribution, and some frontier capabilities. For a broader framework, see our analysis of open-source vs. closed AI agents.
Primary sources
- DeepSeek-V3 announcement — DeepSeek
- DeepSeek-R1 announcement — DeepSeek
- DeepSeek main site — DeepSeek
- Reuters: What is DeepSeek and why is it disrupting the AI sector? — Reuters
- Reuters: Nvidia suffers record market-cap loss as DeepSeek sparks AI selloff — Reuters
Last updated: May 20, 2026. Related: Agent Infrastructure.




