

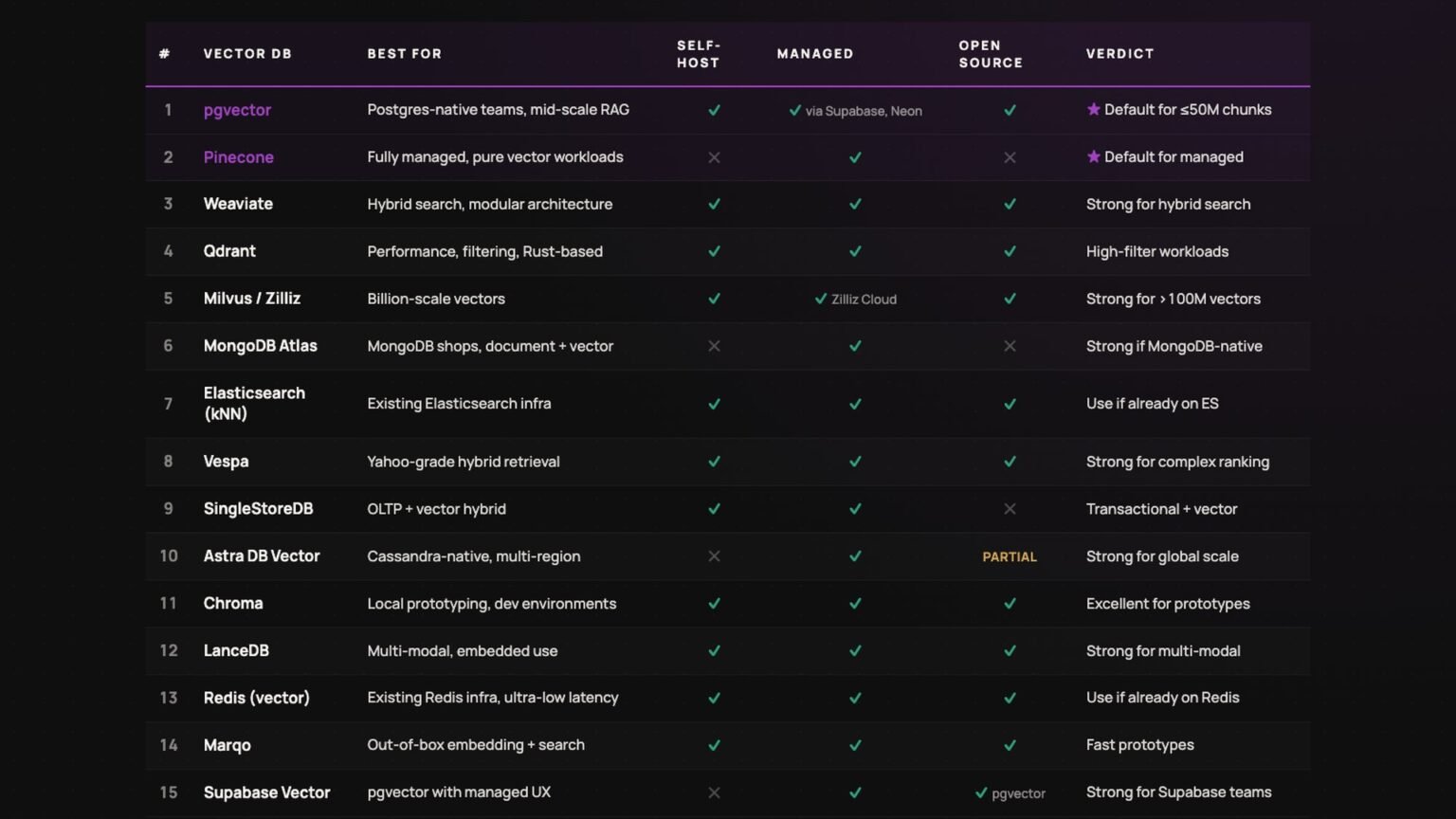
This vector database comparison 2026 looks at Pinecone, Weaviate, Qdrant, Chroma, and pgvector through the lens that matters for agent builders: a roughly 6× spread in managed pricing and a roughly 4× spread in measured latency on similar workloads. The short version is simple: under 10M vectors, localhost economics still dominate; from 10M to 1B, architecture and ops model matter more than marketing; above 1B, you should widen the shortlist beyond the five tools in this piece.
The market in one screen: price, latency, and deployment model
$25/mo
Lowest managed entry tier
Weaviate Cloud entry pricing
~12ms
Fastest cited p99 at 10M vectors
Qdrant in the supplied May 2026 measurements
~45ms
Pinecone cited p95 before extra network overhead
Plus roughly 10–20ms network latency in the supplied benchmark framing
The useful way to read a vector database comparison 2026 is not to ask which product is best in the abstract. It is to ask which one matches your scale tier, your tolerance for infrastructure work, and whether vector retrieval is a sidecar to an existing Postgres app or the core of a retrieval system. The data points below make that trade-off concrete.
Three patterns stand out from the May 2026 comparisons cited here. First, managed entry pricing starts low, but meaningful production workloads separate quickly. Second, self-hosted systems still lead on raw latency in many tests because they avoid some network overhead and expose more tuning surface. Third, the product category has split into two camps: databases that want to be a dedicated retrieval layer, and extensions or local-first tools that win by staying close to the rest of your application.

Use pgvector or Chroma below 10M vectors, then graduate to Qdrant, Weaviate, or Pinecone when scale, tenancy, or managed operations become the bottleneck.
“Qdrant offers the best price-performance ratio in 2026.”
Editorial framework provided for this comparison
| Product | Managed pricing signal | Self-host option | Editorial read |
|---|---|---|---|
| Pinecone | Starter free up to limits; Standard ~$80/mo for 500-user workload | No | Best fit when you want a fully managed dedicated vector service |
| Weaviate | $25/mo entry tier | Yes | Cheapest managed entry and strongest native hybrid-search story |
| Qdrant | $45/mo for 500-user workload | Yes | Best price-performance balance for new projects |
| Chroma | Free OSS; Chroma Cloud beta pricing | Yes | Great local and prototype ergonomics, less proven at larger scale |
| pgvector | Included with Postgres; ~$40/mo RDS instance handles 500 users | Yes | Excellent when vector search belongs inside an existing Postgres stack |
Latency and features: where the products actually separate
Benchmarks are always conditional, but the supplied measurements are still useful because they compare similar index sizes and embedding dimensions. On a 10M-vector, 1536-dimension workload, Qdrant leads the cited p99 numbers at about 12ms, followed by Weaviate at about 16ms and Milvus at about 18ms. Pinecone is cited at about 45ms p95, with another 10–20ms of network latency depending on topology. pgvector is a special case: on localhost and smaller datasets it can be extremely competitive, but the supplied guidance says performance degrades above roughly 5M vectors.
Features matter just as much as raw speed. In this vector database comparison 2026, Weaviate stands out because it is the only major vector database in the supplied matrix with native hybrid search. Pinecone, Qdrant, and pgvector can all support related retrieval patterns, but the ergonomics and built-in support differ. Chroma remains attractive for local development and lightweight deployments, though its managed story is still earlier than the others.
“Weaviate is the only major vector database with native hybrid search.”
Editorial framework provided for this comparison
Why does hybrid search matter for agent retrieval quality?
Hybrid search combines lexical signals such as BM25 with dense vector similarity. That matters when your corpus includes exact identifiers, product names, error codes, or short queries where pure semantic similarity can miss obvious matches. In the supplied feature matrix, Weaviate is the only major product marked with native hybrid search support, which is a meaningful differentiator for enterprise search and agent workflows that mix natural language with structured terms.
How does HNSW indexing actually work in practice?
HNSW builds a layered graph that lets approximate nearest-neighbor search skip large parts of the index while preserving high recall. In practice, teams tune graph density and search breadth to trade memory and build time against latency and recall. That is one reason self-hosted systems such as Qdrant and pgvector can perform very differently depending on configuration, hardware locality, and dataset shape.
| System | Latency metric | Measured result | Context |
|---|---|---|---|
| Qdrant | p99 | ~12ms | 10M vectors, 1536-dim |
| Weaviate | p99 | ~16ms | 10M vectors, 1536-dim |
| Milvus | p99 | ~18ms | 10M vectors, 1536-dim |
| Pinecone | p95 | ~45ms | Plus ~10–20ms network latency |
| pgvector | n/a | Localhost wins under 10M vectors | Degrades above ~5M in supplied guidance |
Pinecone verdict: best managed dedicated vector service, but not the price leader
Pinecone remains the cleanest answer for teams that want a dedicated vector database without running their own cluster. Its appeal is operational simplicity: managed cloud, multi-tenancy, filtering, and a product built around vector retrieval rather than adapted from a general-purpose database. For teams that value vendor-managed operations over infrastructure flexibility, that still matters.
The trade-off is visible in both price and latency. In the supplied numbers, Pinecone’s Standard tier lands around $80 per month for a 500-user workload, which is materially above Weaviate Cloud‘s entry point and above Qdrant Cloud for the same workload framing. The cited benchmark also puts Pinecone behind the fastest self-hosted options on latency. In a vector database comparison 2026, that makes Pinecone easiest to recommend when managed service quality is the first requirement, not when raw price-performance is.
Pinecone
Best for: Teams prioritizing managed operations over lowest cost or self-host flexibility
What works
Watch out for
When is Pinecone worth paying more for?
Pinecone makes the most sense when your team wants a managed vector layer and does not want to self-host, tune indexes, or operate another stateful service. If your application is retrieval-heavy and your team values a dedicated managed product over the lower cost of self-hosting Qdrant or extending Postgres with pgvector, Pinecone can still be the right answer.
Weaviate verdict: best if native hybrid search is non-negotiable
Weaviate’s clearest differentiator is not just that it is fast enough or available as both managed and self-hosted. It is that the supplied matrix marks it as the only major vector database here with native hybrid search. If your retrieval stack needs BM25 plus dense vectors without stitching together multiple systems, Weaviate deserves a very close look.
The economics are also attractive. The editor-supplied pricing puts Weaviate Cloud at $25 per month for entry, the cheapest managed tier in this comparison. The cited p99 latency at around 16ms is also competitive. That combination makes Weaviate one of the strongest all-rounders in this vector database comparison 2026, especially for search-heavy agent products where exact term matching and semantic retrieval need to coexist.
Weaviate
Best for: Enterprise search and agent retrieval systems mixing lexical and semantic search
What works
Watch out for
Choose Weaviate when hybrid retrieval quality matters more than shaving the last few milliseconds.
Qdrant verdict: the best default for new projects
Qdrant is the easiest product to recommend to most teams starting fresh. It supports managed cloud and self-hosting, posts the best cited p99 latency in the supplied benchmark at about 12ms, and lands at about $45 per month for the 500-user workload framing. The editor’s call is blunt and hard to argue with: Qdrant offers the best price-performance ratio in 2026.
That matters because many agent teams do not need the most polished managed-only experience, and they do not want to force vector retrieval into Postgres before they know their scale envelope. Qdrant gives them a dedicated retrieval system with a straightforward migration path from local or self-hosted deployments to managed cloud. In this vector database comparison 2026, it is the most balanced answer for teams in the 10M to 1B vector band.
Qdrant ⭐ Editor’s Pick
Best for: New projects that want a dedicated vector database without overpaying for managed convenience
What works
Watch out for
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance, PointStruct
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="docs",
vectors_config=VectorParams(size=1536, distance=Distance.COSINE),
)
client.upsert(
collection_name="docs",
points=[PointStruct(id=1, vector=[0.1]*1536, payload={"title": "Hello"})],
)
hits = client.search(collection_name="docs", query_vector=[0.1]*1536, limit=5)
What makes Qdrant the best self-hosted option today?
The supplied framework places Qdrant as the best self-hosted choice in the 10M to 1B range. The reasons are straightforward: strong measured latency, managed and self-hosted deployment paths, hybrid search support in the feature matrix, and low enough infrastructure requirements that a small VPS can reportedly handle millions of vectors for roughly $30–50 per month.
How should teams think about multi-region deployment trade-offs?
Multi-region deployment is less about a single benchmark number and more about where your application servers, embedding pipeline, and users sit relative to the vector store. Managed services reduce operational burden, but network distance can erase some benchmark wins. Self-hosting can improve locality and cost, but it shifts replication, failover, and observability onto your team.
Chroma verdict: best local-first developer experience, but still an earlier cloud story
Chroma remains popular because it is simple, open source, and easy to drop into local retrieval workflows. For prototypes, notebooks, and small agent systems, that matters more than benchmark bragging rights. The supplied pricing note is also straightforward: the open-source version is free, while Chroma Cloud pricing is still in beta territory.
The limitation is scale confidence. In the supplied feature matrix, Chroma lacks hybrid search, lacks multi-tenancy, and has a much smaller reported deployment envelope than Pinecone, Weaviate, or Qdrant. That does not make it a bad product. It means Chroma is best treated as a local-first or early-stage choice in this vector database comparison 2026, not the default answer for larger multi-tenant production systems.
Chroma
Best for: Developers who want a free OSS vector store for local apps and early-stage agent prototypes
What works
Watch out for
pgvector verdict: best when you already have Postgres
pgvector wins by removing a system, not by adding one. If your application already runs on Postgres, the extension lets you keep vectors, metadata, filtering logic, and transactional application data in one place. The cost signal in the supplied notes is compelling too: pgvector is included with Postgres, and an RDS instance around $40 per month can handle the 500-user workload framing.
The caveat is scale. The supplied editorial guidance says plainly that pgvector is excellent for <5M vectors. The broader framework extends that idea: under 10M vectors, pgvector and Chroma win on localhost economics and simplicity; above that, dedicated vector systems usually pull ahead. In a vector database comparison 2026, pgvector is the right answer when vector search is a feature inside a Postgres app, not when retrieval infrastructure is the product.
pgvector
Best for: Teams already standardized on Postgres that want simple, low-cost vector search
What works
Watch out for
pgvector is strongest when vectors stay close to application data and dataset size remains modest.
CREATE EXTENSION vector;
CREATE TABLE docs (id bigserial PRIMARY KEY, embedding vector(1536), title text);
CREATE INDEX ON docs USING hnsw (embedding vector_cosine_ops);
INSERT INTO docs (embedding, title) VALUES ('[0.1, 0.2, ...]', 'Hello');
SELECT id, title, embedding <=> '[0.1, 0.2, ...]' AS distance
FROM docs ORDER BY embedding <=> '[0.1, 0.2, ...]' LIMIT 5;
“pgvector is excellent for <5M vectors."
Editorial framework provided for this comparison
When should I switch from pgvector to a dedicated vector DB?
Switch when one of three things happens: your vector corpus grows enough that index build times, memory pressure, or query latency start to dominate; your retrieval workload needs dedicated tenancy or operational isolation; or your search requirements outgrow what is comfortable to maintain inside Postgres. The supplied framework puts the practical handoff around the move from sub-10M datasets toward the 10M to 1B band.
Scale-tier framework: under 10M, 10M–1B, and above 1B
Best overall: Qdrant for new projects; pgvector if you already have Postgres
The most useful conclusion from this head-to-head is that the shortlist changes with scale. Under 10M vectors, pgvector and Chroma are often the best answers because localhost performance, zero or near-zero incremental cost, and simple developer workflows beat the complexity of introducing a dedicated retrieval service. That is especially true if your team already runs Postgres.
From 10M to 1B vectors, the field narrows to Qdrant, Pinecone, and Weaviate. Qdrant is the best self-hosted default and the best overall price-performance pick. Pinecone is the cleanest managed dedicated service. Weaviate is the one to favor when native hybrid search is central to quality. Above 1B vectors, the editorial framework supplied for this piece says the shortlist should expand to distributed systems such as Vespa and Milvus, which are the only production-grade options called out for that tier.
Pros
Cons
| Feature | Pinecone | Weaviate | Qdrant | Chroma | pgvector |
|---|---|---|---|---|---|
| Managed cloud | ✓ | ✓ | ✓ | beta | RDS |
| Self-host | ✗ | ✓ | ✓ | ✓ | ✓ |
| Hybrid search (BM25+dense) | partial | ✓ native | ✓ | ✗ | manual |
| Multi-tenancy | ✓ | ✓ | ✓ | ✗ | partial |
| Filtering | ✓ | ✓ | ✓ | ✓ | SQL |
| Largest reported deployment | 5B+ | 1B+ | 1B+ | <100M | ~50M |
Which should you pick?
If you only need one sentence from this vector database comparison 2026, use this one: pick the database that matches your scale tier and operating model, not the one with the loudest benchmark chart. Most teams below 10M vectors should start simpler than they think. Most teams above that threshold should choose between Qdrant, Weaviate, and Pinecone based on ops preference and retrieval requirements.
| Use case | Best pick | Why | Runner-up |
|---|---|---|---|
| Existing Postgres app, modest vector workload | pgvector | Lowest complexity and strong economics when vectors live with app data | Chroma |
| New agent project, self-host or flexible deployment | Qdrant | Best price-performance ratio and strongest cited latency | Weaviate |
| Managed service first, minimal ops | Pinecone | Dedicated managed vector service with multi-tenancy | Weaviate |
| Hybrid lexical + semantic retrieval | Weaviate | Only major option here with native hybrid search in the supplied matrix | Qdrant |
| Prototype, local notebook, free OSS workflow | Chroma | Simple local-first setup and free open-source path | pgvector |
| Massive distributed deployment above 1B vectors | Look beyond this five-product shortlist | The supplied framework points to Vespa and Milvus at this tier | n/a |
Frequently asked questions
Use pgvector when your application already runs on Postgres and vector search is one feature inside that stack rather than a separate retrieval platform. The extension is documented at pgvector on GitHub, and it fits especially well at smaller scales according to the framework used in this comparison.
Primary sources
- Pinecone official site — Pinecone
- Weaviate official site — Weaviate
- Qdrant official site — Qdrant
- Chroma official site — Chroma
- pgvector GitHub repository — GitHub
- Milvus official site — Milvus
- Vespa official site — Vespa
- Vecstore performance comparison — Vecstore
- DigitalApplied 2026 comparison — DigitalApplied
- GroovyWeb comparison — GroovyWeb
Last updated: May 23, 2026. Related: Agent Infrastructure.




