

Every frontier model advertises a 1 million token context window. The 2026 benchmarks say most of them reliably use barely half of it. Here is the data — and how to work within the context you actually get.
The 1 million token context window, in one uncomfortable number
50–65%
Effective vs advertised
RULER’s estimate of how much of the window most models reliably use for multi-hop work.
~74%
Best MRCR v2 @ 1M
GPT-5.5’s reported multi-round coreference score at the full million-token window.
~26%
Weakest of the top tier @ 1M
A 2M-advertised model scoring in the 20s on MRCR v2 at 1M — advertised ≠ usable.
Every frontier model in 2026 advertises a 1 million token context window — some claim two or ten million. The marketing implies you can pour a small library into a single prompt and the model will use all of it. The benchmarks say otherwise.
NVIDIA’s RULER benchmark puts the effective context — the length at which a model stays reliable — at roughly 50–65% of the advertised window for most models. A model selling you 1 million tokens is often unreliable for multi-fact work somewhere north of 200,000. The gap between what a model accepts and what it can actually use is the single most underreported number in the spec sheet.
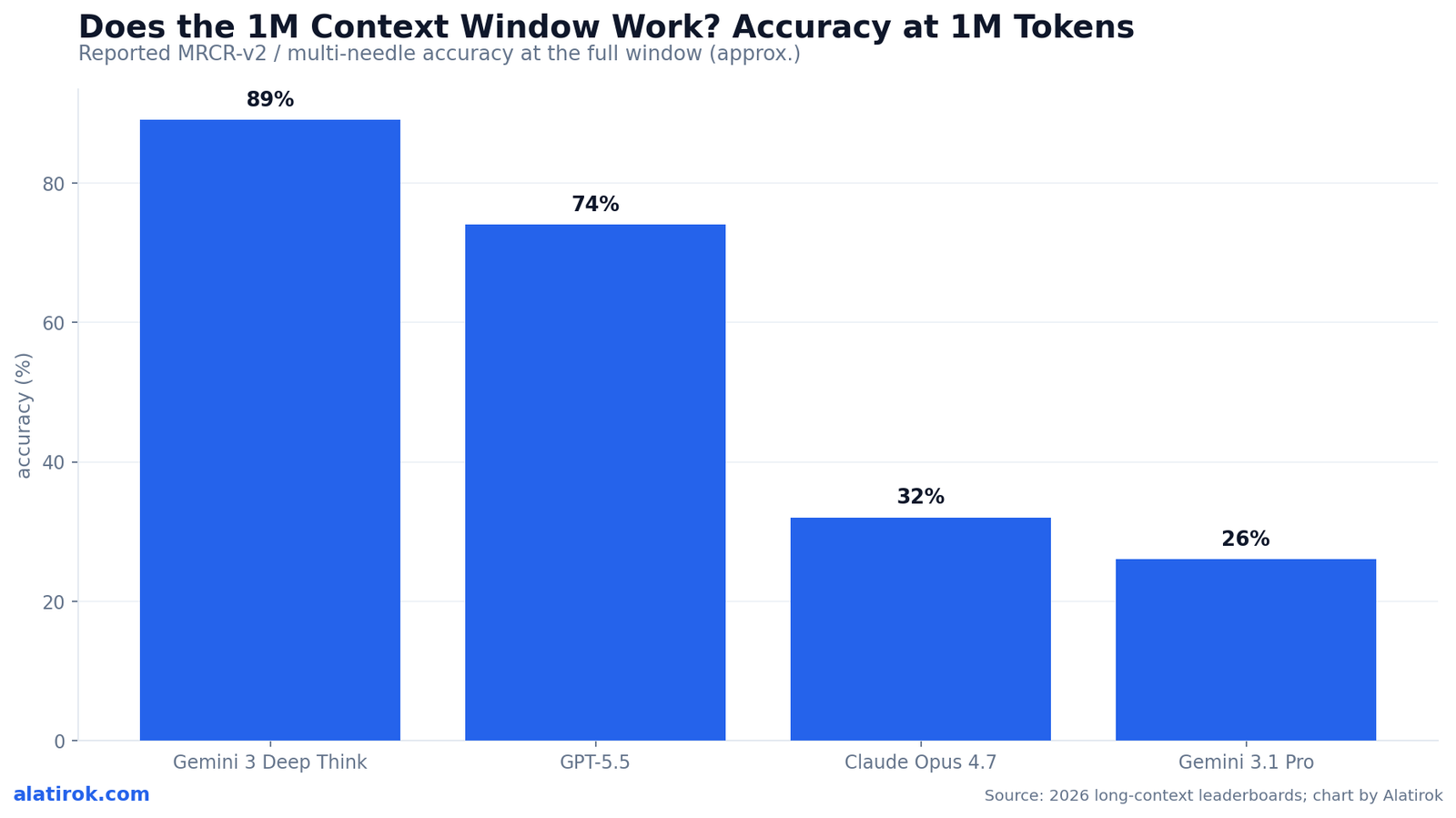
The clearest illustration is MRCR v2, OpenAI’s multi-round coreference benchmark and the closest public test to real long-context work. At the full 1 million token context window, reported 2026 scores spread dramatically: GPT-5.5 around 74%, Claude Opus 4.7 (which advertises 1M) around 32%, and Gemini 3.1 Pro (which advertises 2M) around 26%. Same advertised window; wildly different usable reality.
Advertised context = the most tokens the model will accept. Effective context = the length at which it stays accurate on your task. In 2026 these differ by 30–60 points for multi-fact retrieval past 200K tokens.
What the benchmarks actually measure (so you can read them)
Long-context scores only mean something if you know which test produced them. Three benchmarks dominate 2026, and they get progressively harder.
Needle-in-a-Haystack (NIAH) hides one sentence in a long document and asks the model to find it. It is easy, largely saturated, and the source of most ‘1M tokens!’ marketing — a model can ace NIAH and still be useless for real work. RULER extends NIAH into thirteen tasks across retrieval, multi-hop tracing, aggregation, and question answering; models that ace NIAH routinely fall apart on RULER at the same length. MRCR v2 gives the model a long synthetic conversation and asks it to retrieve specific instances of a repeated request — the closest public proxy for real multi-fact long-context work.
| Benchmark | What it tests | Difficulty | What a high score means |
|---|---|---|---|
| NIAH | Find one planted sentence | Easy (saturated) | The model can retrieve a single fact — little more |
| RULER | 13 tasks: retrieval, multi-hop, aggregation, QA | Hard | The model handles structured multi-fact work at length |
| MRCR v2 | Retrieve specific instances in a long dialogue | Hard (realistic) | Closest proxy to real long-context production tasks |
| NoLiMa | Retrieval without literal lexical matches | Hard | The model reasons, not just string-matches |
The 1 million token context window scores, 2026
Here is the picture at the full million-token window, drawn from 2026 long-context leaderboards. Treat the exact figures as moving targets — they shift with every model release — but the pattern is stable and it is the point.
One model breaks the pattern. Gemini 3 Deep Think holds near-perfect retrieval through the full window — reported single-needle NIAH around 99% and multi-needle near 89% at 1M, with Google’s long-context pipeline widely seen as roughly a year ahead. For everyone else, none performs at 1M as well as it does at 200K.
“Every frontier model advertises a million tokens. Their effective windows for multi-fact work differ by 50 points.”
2026 RULER / MRCR v2 leaderboards
| Model | Advertised window | MRCR v2 @ 1M (approx.) | Practical read |
|---|---|---|---|
| Gemini 3 Deep Think | 1M+ | Near-perfect single-needle; ~89% multi-needle | The genuine long-context leader |
| GPT-5.5 | ~1M | ~74% | Strong, but degrades past ~400K on multi-fact |
| Claude Opus 4.7 | 1M (beta) | ~32% | Excellent ≤200K; thin at the full window |
| Gemini 3.1 Pro | 2M | ~26% | Huge window, low usable depth for multi-fact |
Why the 1 million token context window degrades
The drop-off is not a bug in one model; it is a property of how attention behaves over very long sequences. Three effects compound.
A vendor’s needle-in-a-haystack demo at 1M tokens tells you almost nothing about your task. Re-run the test with YOUR documents and YOUR question before trusting the window.
Lost in the middle
Models attend most strongly to the start and end of the context and deprioritize the middle. A fact buried at the 50% mark of a million-token prompt is the one most likely to be missed — documented since the 2023 ‘Lost in the Middle’ study and still present in 2026 models.
Single-needle success ≠ multi-needle or reasoning
Finding one planted sentence (NIAH) is far easier than tracking several interacting facts (RULER/MRCR) or summarizing the whole haystack. A model can retrieve a single needle at 1M tokens and still collapse on multi-needle MRCR at 128K — and a model can ace retrieval and still hallucinate when asked to summarize the same document.
Attention dilution and cost
As the window grows, attention spreads thinner and signal-to-noise falls — which is why work like DeepSeek V4 argues million-token context needs efficient attention, not just a bigger number. Longer prompts also cost more and run slower, so wasted context is wasted money.
How to actually use a long context window
Verdict: the window is real — the advertised size is not your working size
The 1 million token context window is a real capability — you just have to use it like an engineer, not a marketer. This is the playbook.
1. Budget to the effective window, not the advertised one
For multi-fact work, plan around ~50–65% of the advertised limit. If a model advertises 1M, treat ~400-500K as the zone where accuracy is still trustworthy, and validate even that.
2. Put critical facts at the start and the end
Exploit the recency/primacy bias instead of fighting it. Lead with the instructions and the must-not-miss facts, and repeat the key constraint at the end. Never bury the decisive detail in the middle.
3. Prefer retrieval for anything large
For corpora bigger than the effective window, a retrieval (RAG) step that pulls the relevant 20K tokens beats stuffing 1M — higher accuracy, lower latency, lower cost. Use the big window for genuinely interconnected context, not as a substitute for search.
4. Separate retrieval from reasoning
If the task needs both finding facts and reasoning over them, consider two passes: one to extract the relevant spans, a second to reason over the much smaller extract. Asking one giant prompt to do both is where multi-needle scores fall apart.
5. Test on your own data
Benchmarks generalize poorly to your domain. Build a small RULER-style test from your real documents and your real questions, and measure where YOUR accuracy falls off. That number, not the spec sheet, is your usable window.
Builder’s take
On Cyntr we stopped trusting the advertised number a long time ago. When a model says it has a 1 million token context window, we budget our prompts to roughly half that for anything involving multiple facts, and we route genuinely large corpora through retrieval rather than stuffing the window. The advertised limit is a ceiling, not a working spec — and treating it as a spec is how you ship a pipeline that silently drops facts.
- Size your real prompts to the EFFECTIVE window (~50-65% of advertised for multi-fact work), not the number on the marketing page.
- Put the facts the model must not miss at the very start and the very end — the middle is where attention goes to die.
- Single-needle ‘it found the sentence’ demos prove almost nothing about whether the model can REASON over the same haystack — test the actual task.
- For anything bigger than the effective window, retrieval beats brute-force stuffing on both accuracy and cost.
Frequently asked questions
Partly. It works for single-fact retrieval near the limit on the strongest models, and Gemini 3 Deep Think holds near-perfect retrieval across the full window. But for multi-fact retrieval and reasoning, most 2026 models are reliable only to roughly 50–65% of their advertised window.
The length at which a model stays accurate on a real task, as opposed to the maximum it will accept. RULER puts effective context around 50–65% of advertised for most frontier models.
On reported benchmarks, Gemini 3 Deep Think leads long-context retrieval, holding near-perfect single-needle and ~89% multi-needle at 1M. GPT-5.5 is strong on MRCR v2; most others degrade well before their advertised limit.
Needle-in-a-Haystack only tests finding one planted sentence. Harder benchmarks like RULER and MRCR v2 test multi-hop tracking, aggregation, and reasoning — where the same model can score far lower at the same length.
For corpora larger than the effective window, retrieval (RAG) usually wins on accuracy, latency, and cost. Reserve the big window for genuinely interconnected context that can’t be chunked cleanly.
Yes. The ‘lost in the middle’ effect means models attend most to the beginning and end of the context. Lead with critical facts and instructions, and repeat key constraints at the end.
Primary sources
- Long-Context LLM Benchmarks 2026: accuracy past 200K tokens — ofox.ai
- Long-Context Benchmarks Leaderboard: MRCR, RULER, LongBench v2 — Awesome Agents
- LLM Context Window Comparison: advertised vs effective — BenchLM.ai
- RULER: What’s the Real Context Size of Your Long-Context LMs? — arXiv (NVIDIA)
- Lost in the Middle: How Language Models Use Long Contexts — arXiv
- Needle Threading: Can LLMs Follow Threads through Near-Million-Scale Haystacks? — arXiv
Last updated: May 31, 2026. Related: Observability.




