

From Seoul to Santiago, governments are funding homegrown foundation models and national compute. We map the 2026 sovereign AI race country by country.
What is sovereign AI, and why is every country building it?
Sovereign AI is a nation’s ability to build and run artificial intelligence on its own infrastructure, with its own data, in its own languages — without depending on foreign clouds or foreign-owned models. NVIDIA, whose chips power most of these programs, defines it as producing AI “using its own infrastructure, data, workforce and business networks,” with CEO Jensen Huang framing it as a way to “codify your culture, your society’s intelligence, your common sense, your history.”
Four forces are driving the sovereign AI race in 2026, and most national programs cite all four. Data residency keeps regulated health, financial and government data inside national borders. Language and culture close the performance gap that frontier models trained mostly on English and Global North data leave for Korean, Hindi, Arabic, Spanish and 1,000-plus underserved languages. National security reduces reliance on systems that a foreign government could restrict or surveil. And industrial policy treats AI compute the way the 20th century treated steel and semiconductors — as strategic capacity worth subsidizing.
The pattern is remarkably consistent across continents: a government picks national champions, funds a homegrown foundation model, and pairs it with subsidized GPU clusters so local startups can train without renting from hyperscalers. What differs is scale, openness and how much each program leans on Meta’s Llama or Alibaba’s Qwen as a base. The rest of this map walks the major sovereign AI programs region by region. Funding figures and benchmarks move fast; treat every number here as a 2026 snapshot, attributed to its source.
Nearly every national program follows the same three steps: (1) designate champions and fund a domestic foundation model, (2) stand up subsidized national GPU clusters, (3) anchor data residency and local-language performance as the headline justification. The differences are scale and how much each leans on open weights.
The sovereign AI map: a country-by-country comparison
As of 2026, at least seven major jurisdictions — South Korea, Japan, India, Saudi Arabia, the UAE, the European Union and Chile (for Latin America) — run funded sovereign AI programs combining national models with public compute. The table below maps the flagship models, headline funding and compute commitments for each. Figures are drawn from government and company announcements and are best treated as directional.
Two structural divides stand out. The Gulf states (Saudi Arabia, UAE) are competing on raw compute scale — hundreds of thousands of GPUs — while Korea and India compete on model count and language coverage. And the openness split is sharp: India’s Sarvam and Chile’s Latam-GPT ship open weights, whereas several Korean and Gulf models remain closed or enterprise-gated.
| Country / Region | Flagship national model(s) | Headline public funding | Compute commitment |
|---|---|---|---|
| South Korea | EXAONE 4.0 (LG), HyperCLOVA X (Naver), A.X K1 (SKT), Solar (Upstage), VARCO (NC), Motif | ~$380M to 5 champion consortia; AI in 2026 budget ~KRW 10.1tn | 50,000+ NVIDIA GPUs across National AI Computing Center and Korean clouds |
| Japan | Sakana AI models; GENIAC-funded foundation models (Preferred Networks, others) | ~¥387B for domestic AI in FY2026; >¥10tn over 7 years to FY2030 (semiconductor + AI) | NEDO/GENIAC-sponsored GPU clusters for grantees |
| India | Sarvam-105B and Sarvam-30B (Feb 2026); 12 govt-funded model teams incl. BharatGen | IndiaAI Mission ~Rs 10,372cr (~$1.25B) | 34,000 GPUs live at subsidized rates; 100,000-GPU target end-2026 |
| Saudi Arabia | ALLaM (Arabic LLM), via HUMAIN | State-backed via PIF (HUMAIN); multi-billion-dollar chip deals | 18,000 GB300 in phase 1; up to 500MW of AI factories over 5 years |
| UAE | Falcon / Falcon-H1 Arabic (TII), via G42 | $1.5B Microsoft equity in G42; sovereign-scale capex | Hyperscaler-class Abu Dhabi compute; 5GW US-UAE campus planned |
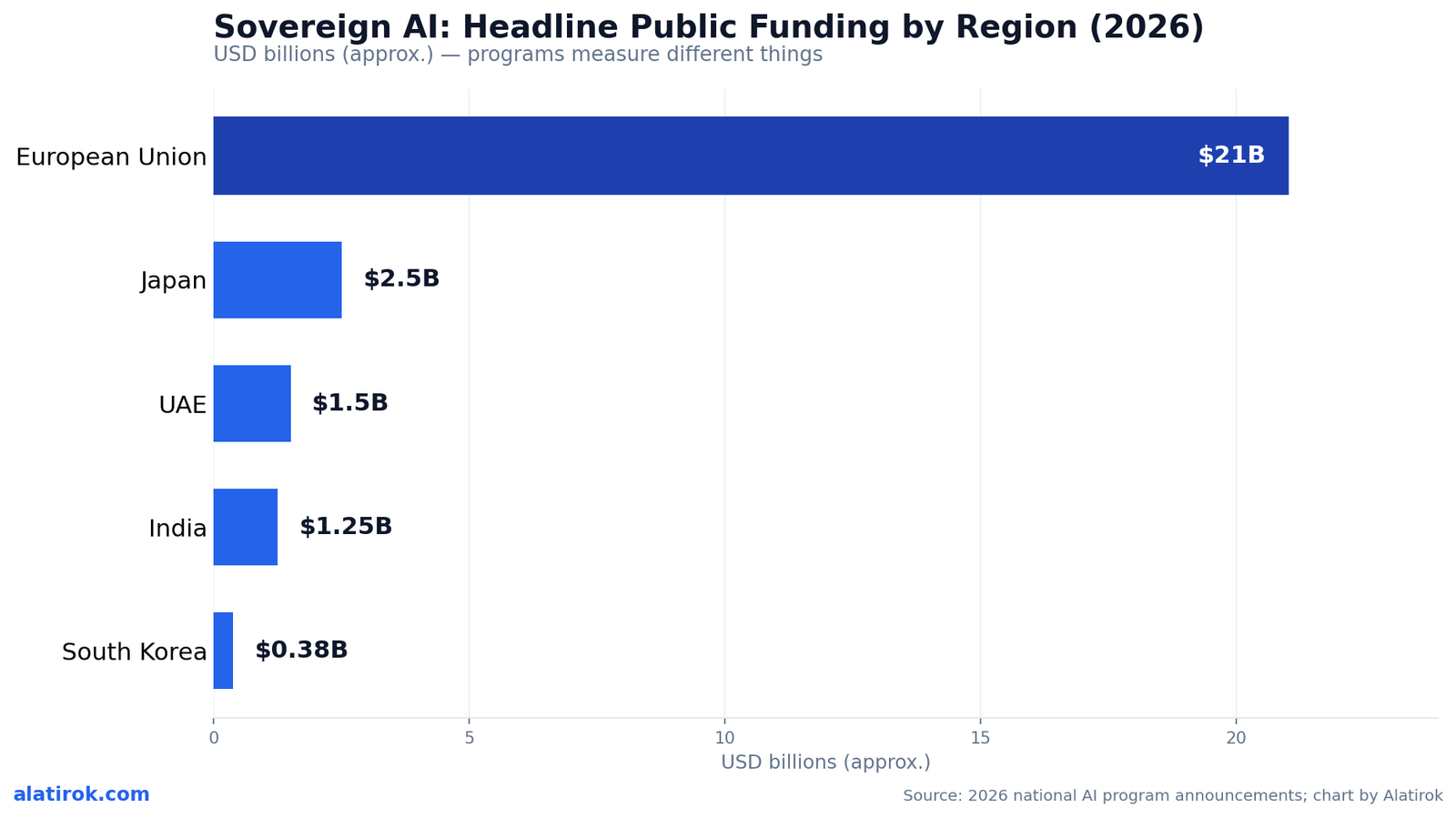
| European Union | OpenEuroLLM and other consortia (no single champion) | InvestAI: €20B for gigafactories within a €200B mobilization | Up to 4-5 AI gigafactories, each 100,000+ AI processors |
| Chile / Latin America | Latam-GPT (Llama 3.1 70B base) | CENIA + CAF funded; regional public good | U. of Tarapacá supercomputing center (~$10M) |
Asia’s sovereign AI leaders: Korea, Japan and India
South Korea, Japan and India are the most advanced sovereign AI programs outside the US and China, each pairing multiple national models with billions in public compute funding. Korea is the clearest example of the champion model: its Ministry of Science and ICT selected five consortia — led by Naver, SK Telecom, LG, NC and Upstage — and allocated roughly $380 million to compete in a tournament that will narrow the field over time. The Stanford AI Index counts South Korea among the top producers of notable models, with eight in its latest tally, and the lineup spans LG’s EXAONE 4.0, Naver’s HyperCLOVA X, SKT’s 500-billion-scale A.X K1, Upstage’s Solar, NC’s VARCO and Motif’s reasoning model.
Japan runs its program through METI’s GENIAC initiative, which gives grantees access to government-sponsored GPU clusters via NEDO. Tokyo’s Sakana AI — which raised $135 million at a $2.65 billion valuation to build culturally aligned models for finance and defense — is the highest-profile recipient, alongside firms like Preferred Networks. METI’s FY2026 budget earmarks roughly ¥387 billion for domestic AI including foundation models, inside a longer framework promising more than ¥10 trillion in public support through FY2030 across AI and semiconductors.
India’s sovereign AI push is the most compute-aggressive in the region relative to its starting point. The IndiaAI Mission, funded at about Rs 10,372 crore (~$1.25 billion), put 34,000 GPUs online at subsidized rates (as low as ~Rs 115-150 per GPU-hour) and targets 100,000 GPUs by the end of 2026. Its landmark deliverable arrived in February 2026: Bengaluru’s Sarvam AI launched Sarvam-105B, a mixture-of-experts model trained from scratch on 12 trillion tokens using domestic compute, supporting all 22 official Indian languages with a 128,000-token context window — released open-source under Apache 2.0.
Korea: five champions, one tournament
The Korean program is deliberately competitive: five consortia were funded, an evaluation in late 2025 narrows them, and only a couple are expected to survive to 2027. This forces a real model race rather than spreading subsidies thin. Models range from LG’s reasoning-focused EXAONE to Upstage’s efficient Solar MoE and SKT’s 500B-parameter A.X K1.Japan: compute grants over a single champion
Rather than crown one model, Japan’s GENIAC subsidizes compute and matchmaking for many grantees, betting on an ecosystem. Sakana AI’s defense-and-finance focus shows the security framing driving sovereign demand. The headline ~$6.6B-class figures often cited refer to multi-year, cross-sector commitments — read them as program envelopes, not single-year model budgets.India: open weights as a sovereignty strategy
By open-sourcing Sarvam-105B, India makes its national model a public good that any Indian startup can fine-tune on subsidized GPUs — turning sovereignty into ecosystem leverage rather than a closed asset. The 100,000-GPU end-2026 target is ambitious; treat it as a stated goal, not a guaranteed delivery date.The Gulf and the EU: compute scale versus coordination
The Gulf states are buying their way to sovereign AI through raw compute, while the EU is trying to coordinate its way there through pooled gigafactories — two very different bets. Saudi Arabia’s HUMAIN, a Public Investment Fund company, anchors Crown Prince Mohammed bin Salman’s Vision 2030 with an Arabic LLM family (ALLaM) and a hardware program that starts with an 18,000 GB300 Grace Blackwell supercomputer and scales toward 500MW of AI factories over five years. The UAE’s G42 plays a parallel role with the Falcon model family from the Technology Innovation Institute — including Falcon-H1 Arabic — backed by $1.5 billion in Microsoft equity and an Abu Dhabi compute footprint that, with a planned 5GW US-UAE campus, puts the Gulf among the largest AI-compute jurisdictions outside the US and China.
The European Union is the structural outlier. It has no single national champion; instead, its sovereign AI strategy runs through the InvestAI initiative, which dedicates €20 billion to building four or five AI gigafactories within a broader €200 billion mobilization. Each gigafactory is specced for 100,000-plus AI processors, and in January 2026 the Council strengthened the EuroHPC Joint Undertaking’s mandate to deploy them. Europe’s bet is that pooled, cross-border compute plus consortia like OpenEuroLLM can deliver sovereignty without picking winners — though the model layer remains its weakest link.
The contrast matters for anyone deploying sovereign AI. The Gulf offers vast, fast in-region capacity but fewer mature open national models; the EU offers strong governance and language diversity but slower, committee-driven compute. Buyers choosing where to host regulated workloads are effectively choosing between these two philosophies.
“The Gulf is buying compute by the gigawatt; Europe is legislating it by committee. Both are sovereign AI — they just disagree on whether sovereignty is hardware or governance.”
Alatirok analysis
Latin America’s model: Chile, Latam-GPT and the open-weights path
60+
institutions behind Latam-GPT
Across 20+ countries; ~200 specialists, coordinated by CENIA in Chile
70B
Latam-GPT parameters
Built on Meta Llama 3.1; open, region-focused
105B
Sarvam (India) parameters
MoE, ~9B active; trained from scratch on 12T tokens, Apache 2.0
500MW
Saudi HUMAIN AI factories
Over five years; phase 1 = 18,000 GB300 GPUs
Latin America’s sovereign AI strategy is regional, not national: Chile’s CENIA coordinated Latam-GPT, an open large language model launched in February 2026 for the whole region rather than one country. Presented on February 10, 2026 by CENIA with the development bank CAF, the Chilean government, AWS and Data Observatory, Latam-GPT is built on Meta’s Llama 3.1 70B base and trained on a corpus of Spanish- and Portuguese-language and regional knowledge spanning 20 Latin American countries and Spain. The project drew on more than 60 institutions and roughly 200 specialists.
The framing is explicitly about closing a representation gap. Most frontier models train on Global North data, leaving Latin American dialects, idioms and local knowledge underrepresented. Latam-GPT positions the region to move “from primarily consuming foundation models to also building and shaping them,” with governance grounded in local contexts and an open architecture that reduces dependency on closed proprietary systems. The University of Tarapacá in Arica built a supercomputing center — the first of its kind in the region capable of training large models domestically.
Latam-GPT is the clearest proof that sovereign AI does not require frontier-scale budgets. By fine-tuning open Llama weights and pooling regional institutions, a coalition with modest funding produced a credible national-class model. That open-weights, coalition path — also visible in India’s Apache-licensed Sarvam — is the most replicable template for the dozens of countries that cannot match Gulf or US compute spending.
What sovereign AI means for builders and buyers in 2026
Sovereign AI is now infrastructure policy, not a moonshot
For builders, the practical takeaway is that 2026 sovereign AI turns ‘where does inference run’ into a first-class procurement requirement, and most national models are open-weight derivatives you can integrate without rebuilding your stack. Because programs from Korea to Chile increasingly fine-tune Llama or Qwen, your existing safety, evaluation and prompt-injection tooling generally carries across national models — the integration work is routing, data residency and in-country endpoints, not retraining.
For buyers, the decision is now about jurisdiction and openness as much as benchmarks. A regulated European bank, a Gulf ministry and an Indian startup face genuinely different sovereign AI menus: pooled EU gigafactory capacity with strong governance, vast in-region Gulf compute with fewer open models, or India’s subsidized GPUs plus an open national model. The right choice depends on which of the four drivers — data residency, language, security, industrial policy — dominates the use case.
The risk to watch is the gap between announced and delivered compute. India’s 100,000-GPU target, Saudi Arabia’s 500MW buildout and the EU’s gigafactories are commitments, not finished facilities, and timelines routinely slip. Plan integrations against announced dates plus a buffer — the political will behind sovereign AI is durable even when the hardware arrives late.
Builder’s take
I build Cyntr, an agent-orchestration runtime, and Loomfeed, and the sovereign AI wave is the single biggest shift in where my customers want their inference to physically run. Two years ago nobody asked which jurisdiction a model lived in; in 2026 it is the first question on the procurement call. The map below is not abstract geopolitics to me — it determines which models I can route to and where the GPUs sit.
- Sovereignty is a deployment requirement, not a model-quality argument. When I wire a national model into Cyntr, the win is data residency and an in-country endpoint, not a benchmark — build your routing layer so you can swap a frontier model for a local one per tenant without touching app code.
- Treat every national model as Llama- or Qwen-derived until proven otherwise. Latam-GPT and many sovereign efforts fine-tune open weights, so your safety, eval and prompt-injection harness carries over — do not rebuild it per country.
- Compute timelines slip but funding commitments rarely reverse. I plan integrations against announced GPU-online dates plus 6-12 months, because the political will (Korea, India, the Gulf) is durable even when the hardware is late.
- The real moat for a runtime like mine is policy on every path — multi-tenant isolation, per-region routing and audit. Sovereign buyers care more about that than about which 105B model you call underneath.
Frequently asked questions
Sovereign AI is a country’s capacity to develop and operate artificial intelligence on its own infrastructure, using its own data and languages, without depending on foreign clouds or foreign-controlled models. NVIDIA defines it as producing AI with a nation’s own infrastructure, data and workforce, and the goal is to protect local language, culture, security and economic capacity.
As of 2026, major funded sovereign AI programs run in South Korea, Japan, India, Saudi Arabia, the UAE, the European Union and Chile (coordinating Latam-GPT for Latin America). China and the United States also have large national AI ecosystems, though they are usually treated separately from the sovereign-AI-for-smaller-nations framing.
Four reasons recur across nearly every program: data residency (keeping regulated data in-country), language and cultural performance (frontier models underperform on Korean, Hindi, Arabic and Spanish), national security (reducing reliance on foreign-controlled systems), and industrial policy (treating AI compute as strategic capacity). Most national programs cite all four at once.
Sarvam-105B is India’s first sovereign foundation model at scale, launched in February 2026 by Bengaluru-based Sarvam AI under the IndiaAI Mission. It is a mixture-of-experts model trained from scratch on 12 trillion tokens, supports all 22 official Indian languages with a 128,000-token context window, and was released open-source under the Apache 2.0 license.
Latam-GPT is the first open large language model built for Latin America and the Caribbean, launched on February 10, 2026 and coordinated by Chile’s CENIA with development bank CAF. Built on Meta’s Llama 3.1 70B base by more than 60 institutions across 20-plus countries, it proves that sovereign AI is achievable through open weights and regional coalitions rather than frontier-scale budgets.
Commitments vary widely and figures move quickly. India’s IndiaAI Mission is funded at about Rs 10,372 crore (~$1.25 billion), Korea allocated roughly $380 million to its five model consortia, the EU’s InvestAI dedicates €20 billion to AI gigafactories, and Saudi Arabia’s HUMAIN is building up to 500MW of AI factories over five years. These are mostly multi-year envelopes and stated targets, not delivered capacity.
Primary sources
- What Is Sovereign AI? — NVIDIA
- South Korea debuts foundation model in sovereign AI push — Computer Weekly
- Why Sarvam’s new 105B model marks a shift in India’s sovereign AI ambitions — Business Standard
- Launch of the First Open LLM for Latin America and the Caribbean: LATAM-GPT — Access Partnership
- HUMAIN and NVIDIA Announce Strategic Partnership to Build AI Factories in Saudi Arabia — NVIDIA Newsroom
- AI Factories — InvestAI and the AI Gigafactories — European Commission
Last updated: May 31, 2026. Related: Capital.




