


Nvidia still owns roughly three-quarters of data-center AI accelerators, but custom ASICs from Google, Amazon, and Microsoft are growing nearly 3x faster than GPUs. Here is the real 2026 split.
What is the AI chip market share in 2026?
In 2026, Nvidia still controls roughly 70 to 75 percent of the data-center AI accelerator market by revenue, AMD holds an estimated 6 to 8 percent, and hyperscaler custom silicon (Google TPU, AWS Trainium, Microsoft Maia, Meta MTIA) collectively sits near 15 to 20 percent and growing fast. That is the headline AI chip market share split, but the single number hides the real story: the pie itself roughly doubled, so even Nvidia’s shrinking slice is a much bigger meal than a year ago.
The market context matters. Silicon Analysts pegs the 2026 data-center accelerator market above $200 billion, and Bloomberg Intelligence projects the broader AI accelerator market to exceed $600 billion by 2033, driven by hyperscale spending and ASIC adoption. When a market is compounding this fast, share and revenue can move in opposite directions, which is exactly what is happening to Nvidia.
Two structural shifts define the year. First, AMD has finally become a credible second source with its Instinct MI350 series. Second, and more importantly, custom application-specific chips (ASICs) built by the cloud giants are growing nearly three times faster than merchant GPUs. According to TrendForce data reported in May 2026, custom ASIC shipments are growing about 44.6 percent year over year versus 16.1 percent for merchant GPUs, and ASIC-based servers are on track for roughly 27.8 percent of accelerator server shipments in 2026.
The rest of this article breaks down each player with real revenue figures, explains why the training-versus-inference divide governs everything, and gives you a branded chart of the estimated 2026 split you can cite.

AI chip market share estimates vary widely by methodology. Revenue-share counts dollars (favors Nvidia’s premium pricing); shipment-share counts units (favors cheaper ASICs); and “accelerator” definitions differ on whether networking silicon is included. Every figure below is attributed, and the ranges reflect genuine disagreement among analysts, not sloppiness.
Nvidia’s dominance: shrinking share, surging revenue
$75.2B
Nvidia data-center revenue
Q1 FY2027, +92% YoY (SEC 8-K)
~75%
Nvidia 2026 share
down from ~87% in 2024
595k
CoWoS wafers
Nvidia’s 2026 demand (Morgan Stanley est.)
Nvidia‘s AI chip market share is sliding from a 2024 peak near 87 percent toward roughly 75 percent in 2026, yet its data-center revenue hit a record $75.2 billion in a single quarter, up 92 percent year over year. That figure comes straight from Nvidia’s Q1 FY2027 results filed with the SEC, covering the quarter ended April 2026. Falling share, soaring sales: that paradox is the whole point.
The reason Nvidia keeps winning dollars even as it loses points of share is structural lock-in. CUDA, the software layer every AI researcher learned on, plus NVLink and InfiniBand for chip-to-chip networking, make Nvidia the path of least resistance for frontier model training. Switching costs are enormous: rewriting kernels, re-validating numerics, and re-tuning a training run for a new chip can cost months of engineering time. For a lab racing competitors, that is time it cannot afford.
Nvidia’s Blackwell generation (the B200 and the GB200 / GB300 rack-scale systems) extended that lead into 2026. Demand for the full system, including Spectrum-X Ethernet and NVLink, is what pushed the data-center line to a record. Morgan Stanley has estimated Nvidia alone will consume roughly 595,000 CoWoS advanced-packaging wafers in 2026, more than the entire industry’s total demand in 2024, which is a blunt measure of how much of TSMC’s most constrained capacity Nvidia commands.
So the bear case is not that Nvidia is in trouble. It is that the parts of the market growing fastest, namely cost-sensitive inference at hyperscale, are precisely the parts where customers have both the volume and the engineering budget to design around Nvidia. That is the opening AMD and the ASIC builders are driving through.
“Nvidia’s share is falling and its revenue is at a record high. Both are true because the market roughly doubled underneath it.”
Alatirok analysis
The estimated 2026 AI chip market share split
By revenue, the best-supported 2026 estimate puts Nvidia near 73 percent, AMD around 7 percent, Google TPU near 8 percent, AWS Trainium and Inferentia near 5 percent, Microsoft Maia and Meta MTIA near 3 percent combined, and all other vendors near 4 percent. These are mid-point estimates synthesized from Silicon Analysts, TrendForce, and Tom’s Hardware reporting; treat them as directional, because no single auditor counts every internal hyperscaler chip the same way.
The chart below is the clearest way to see it. Notice how the custom-silicon segments, when added together, already rival AMD’s standalone position and are growing far faster. That is the structural shift capital allocators are watching: not whether AMD takes a few points from Nvidia, but whether the cloud giants collectively normalize a world where a quarter of inference never touches a merchant GPU at all.
A crucial caveat: revenue share flatters Nvidia because its chips carry premium pricing and fat margins, while a Trainium or a TPU is largely an internal cost item for Amazon or Google and is priced to undercut. On a unit-shipment basis, custom ASICs already look much larger, which is why TrendForce’s 27.8 percent ASIC server share figure and the 73 percent Nvidia revenue figure can both be true at once. They measure different things.
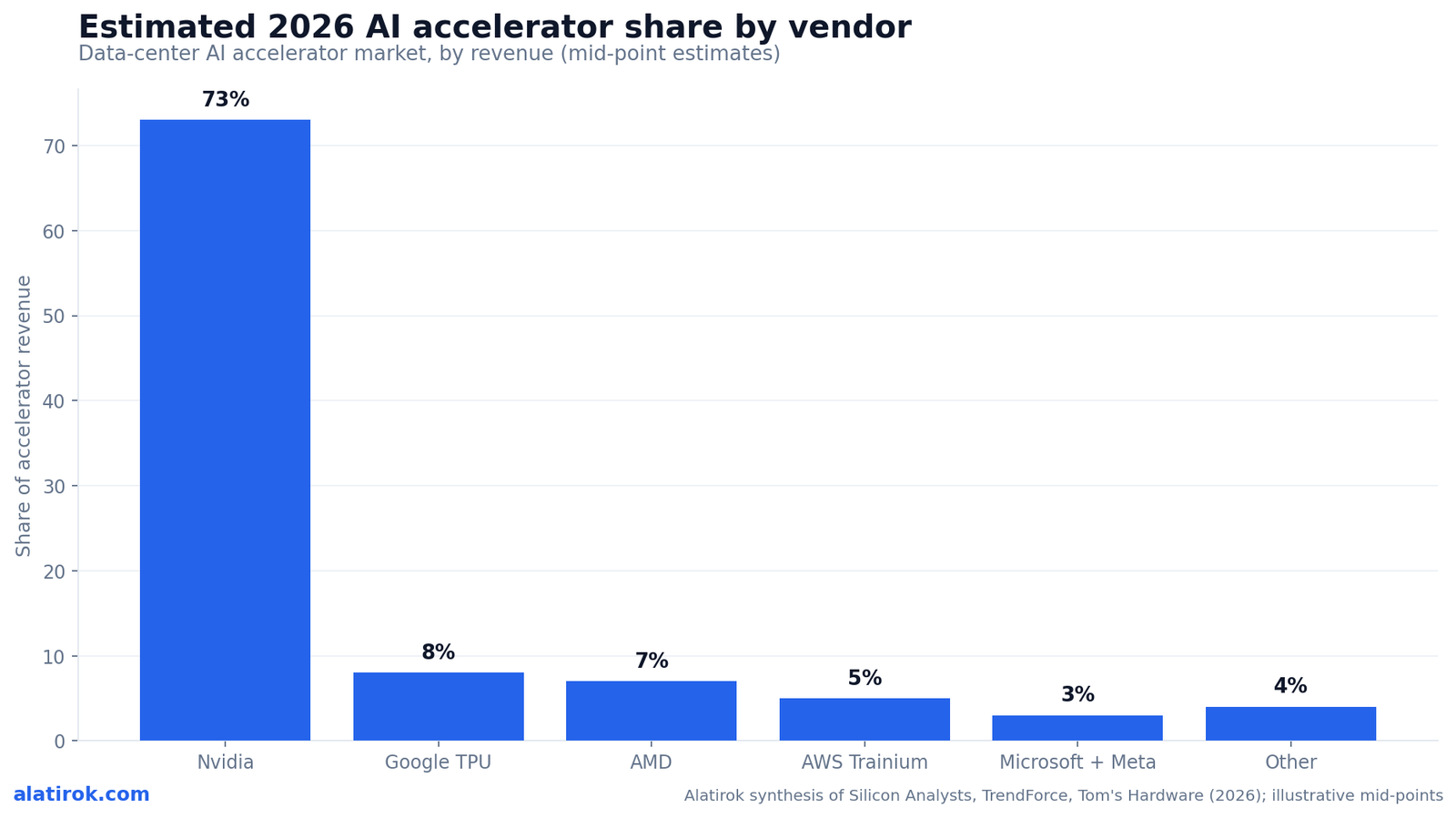
There is no audited, universally agreed AI chip market share table for 2026. Analyst estimates for Nvidia range from about 70% to 86% depending on whether the count is revenue or units and what counts as an ‘accelerator.’ We show mid-points and flag the spread rather than pretend to a precision the data does not support.
AMD’s push: MI350 makes it a real second source
AMD turned its AI accelerators into a multibillion-dollar line in 2026, posting $5.8 billion in data-center revenue in Q1 2026 (up 57 percent year over year) on the strength of its Instinct MI350 series, with analysts at HSBC projecting AMD AI chip sales could reach roughly $15 billion for the full year. For the first time, buyers have a genuine alternative to Nvidia that runs a comparable software stack.
The competitive lever is memory and price. The MI350 ships with up to 288GB of HBM3E, considerably more than a comparable Nvidia part, which matters for serving very large models where the entire weight set has to fit in memory to avoid expensive sharding. AMD has paired that with aggressive total-cost-of-ownership positioning aimed squarely at inference, the workload where it does not need to beat Nvidia’s training ecosystem to win business.
The customer roster is what makes 2026 different from prior false starts. Microsoft, Meta, and OpenAI have all committed to AMD Instinct deployments, and Meta has signaled plans to deploy up to 6 gigawatts of AMD Instinct GPUs over time, with its first one-gigawatt deployment built around a custom MI450-based system. When the largest AI buyers in the world dual-source on purpose, that is a durable position, not a one-quarter blip.
The honest limitation: AMD’s ROCm software ecosystem, while much improved, still trails CUDA in breadth, tooling, and the long tail of optimized kernels. For frontier training, most labs still default to Nvidia. AMD’s 2026 win is to own a real, growing share of inference and of memory-bound serving, and to be the credible second source that keeps Nvidia’s pricing honest.
| Chip | Vendor | Key spec | 2026 status / figure |
|---|---|---|---|
| Blackwell B200 / GB300 | Nvidia | Rack-scale NVLink + CUDA | $75.2B data-center revenue, Q1 FY2027 |
| Instinct MI350 | AMD | Up to 288GB HBM3E | $5.8B data-center rev Q1 2026, +57% YoY |
| TPU v7 Ironwood | 192GB HBM3E, 7.37 TB/s | GA since Nov 2025; ~4.3M units est. 2026 | |
| TPU 8t / 8i | Split train / inference, 2nm-class | Unveiled April 2026, GA later in 2026 | |
| Trainium3 | AWS | 2.52 PFLOPS FP8, 144GB HBM3E | Chips business >$20B run rate |
| Maia 200 | Microsoft | 216GB HBM3E, ~750W, 3nm | Deployed in Azure from Jan 2026 |
| MTIA 400 / 500 | Meta | Up to 512GB HBM (500) | Internal inference + ranking |
The custom-silicon surge: where the real share shift is
44.6%
ASIC shipment growth
2026 YoY, vs 16.1% for GPUs (TrendForce)
1M+
Trainium deployed
AWS; chips business >$20B run rate
~4.3M
Google TPU units
estimated 2026 shipments
The fastest-moving force in the 2026 AI chip market share map is not AMD; it is hyperscaler custom silicon, where ASIC shipments are growing about 44.6 percent year over year versus 16.1 percent for merchant GPUs and are on track for roughly 27.8 percent of accelerator-server shipments. Google, Amazon, Microsoft, and Meta are designing their own chips to escape Nvidia’s margins and to tune silicon for the exact models they run at scale.
Google is furthest along. Its seventh-generation TPU, Ironwood (v7), reached general availability in November 2025 with 192GB of HBM3E and 7.37 TB/s of bandwidth, and Google claims roughly 44 percent lower total cost of ownership per chip versus a comparable Nvidia GB200 server. In April 2026 Google went further, unveiling an eighth generation split into a TPU 8t for training and a TPU 8i for inference, with the training part claimed at 2.8x the performance-per-dollar of Ironwood. Industry estimates put Google’s total TPU shipments near 4.3 million units in 2026.
Amazon’s Trainium is the other heavyweight. AWS has said its chips business is running above a $20 billion annual revenue run rate, that it has deployed more than one million Trainium processors, and that customer commitments tied to Trainium exceed $225 billion. Crucially, Anthropic, whose Claude models are a flagship customer, runs production workloads on Trainium, proving the chips handle frontier-class inference and not just internal housekeeping. Trainium3 delivers about 2.52 PFLOPS of FP8 compute with 144GB of HBM3E and is positioned at roughly half the cost of equivalent Nvidia hardware.
Microsoft and Meta round out the field. Microsoft’s Maia 200, announced in January 2026 and now deployed in Azure data centers, is a 3nm inference chip with 216GB of HBM3E in a roughly 750W envelope, serving models including OpenAI’s GPT-5.2 with claimed 30 percent better performance-per-dollar than Microsoft’s prior fleet generation. Meta’s MTIA line, used for ranking and inference, scales to as much as 512GB of HBM on the upcoming MTIA 500. None of these chips are sold on the open market, which is the catch for everyone who is not a cloud giant.
Why hyperscalers design their own chips instead of buying Nvidia
Three reasons: cost, fit, and control. Cost, because a TPU or Trainium is an internal bill of materials rather than a margin-loaded purchase, so each chip Google or Amazon runs internally avoids paying Nvidia’s gross margin. Fit, because a hyperscaler knows the exact model shapes and inference patterns it serves and can tune memory, interconnect, and number formats accordingly. Control, because owning the silicon roadmap insulates a cloud from Nvidia’s allocation decisions and pricing. The trade-off is enormous up-front design cost and dependence on partners like Broadcom and Marvell for the hard physical-design work.The Broadcom and Marvell angle most coverage misses
The ASIC surge is also a co-design boom. Broadcom and Marvell together control roughly 95 percent of the custom AI ASIC co-design market. Broadcom reported $8.4 billion in AI semiconductor revenue in Q1 FY2026, carries a backlog above $70 billion, and targets AI chip revenue above $100 billion in 2027; Marvell projects up to $11 billion in AI ASIC revenue for 2026. So when you read that Google or Meta or OpenAI is ‘building its own chip,’ a large share of the economics flows to these two design houses behind the scenes.What is actually shifting: training versus inference
The cleanest way to understand the entire 2026 AI chip market share contest is to split it into training and inference: Nvidia still owns frontier training thanks to CUDA and NVLink, while custom ASICs and AMD are taking real share in inference, which is where the dollars and the unit volume are increasingly concentrated. Almost every shift on the chart above maps onto this one divide.
Training is winner-take-most for Nvidia because it is bursty, software-intensive, and unforgiving. A frontier run wants the most mature toolchain, the fastest interconnect, and the fewest surprises, and that is CUDA plus NVLink plus InfiniBand. Inference is the opposite: it is steady-state, enormous in aggregate volume, and ruthlessly cost-sensitive. When you are serving billions of tokens a day, a 30 to 50 percent lower cost per token from a Trainium or a Maia chip compounds into hundreds of millions of dollars, and the engineering cost to port is worth paying.
This is why the split matters for capital. The market segment growing fastest in 2026 is inference, and inference is exactly where Nvidia’s moat is shallowest. Google’s decision to ship separate TPU 8t and 8i chips, one for training and one for inference, is an explicit bet on this divide. So is Microsoft positioning Maia 200 purely as an inference accelerator and AMD aiming MI350’s memory advantage at serving large models.
The takeaway for builders and investors alike: do not read ‘Nvidia loses share’ as ‘Nvidia loses.’ Read it as the market bifurcating. Nvidia keeps the high-margin training crown; AMD and the ASIC builders carve out the high-volume inference base; and the total addressable market grows fast enough that, for now, almost everyone’s revenue rises at once.
Pros
Cons
Train where the ecosystem is deepest (Nvidia), serve where the cost-per-token is lowest (ASICs and AMD). That single rule explains nearly every move on the 2026 AI chip market share map.
What this means for buyers, builders, and investors
Nvidia leads, but 2026 is the year the AI chip market stopped being a monopoly
If you are not a hyperscaler, your practical 2026 choice is still Nvidia versus AMD, because TPUs, Trainium, Maia, and MTIA are not sold on the open market; custom silicon only changes your costs indirectly, through the cloud prices you pay. That is the most important and least-stated implication of the whole AI chip market share debate.
For builders running agents and inference workloads, the actionable move is to benchmark cost-per-token across clouds rather than fixating on chip brand. The same model served on AWS Trainium, Google TPU, or an Nvidia instance can differ by 30 to 50 percent in cost, and that gap, not the spec sheet, is what hits your margin. Treat the chip as an implementation detail of the cloud and optimize the bill.
For investors, the signal is that Nvidia’s revenue can keep growing even as its share declines, so ‘share is falling’ is not a short thesis on its own. The more interesting exposure is the picks-and-shovels layer: TSMC’s advanced packaging (CoWoS), high-bandwidth memory suppliers, and the ASIC co-design duopoly of Broadcom and Marvell, all of whom get paid no matter which chip badge wins.
For 2027, the questions to watch are whether AMD’s MI400 generation and ROCm can close the training gap, whether Google’s TPU 8t finally makes external customers comfortable training off Nvidia, and whether the inference market grows large enough that custom silicon’s share gains start denting Nvidia’s revenue and not just its percentage. Until one of those breaks, expect the same pattern: Nvidia dominant, AMD climbing, custom silicon surging, and the pie growing fast enough to feed them all.
Builder’s take
I buy and benchmark accelerator time for Cyntr and Loomfeed, so the AI chip market share debate is not abstract for me. It shows up on the invoice every month. Here is what the 2026 numbers actually mean for anyone running agents at scale.
- Nvidia’s ‘declining’ share is the most misread stat of the year. Going from 87 to 75 percent of a market that roughly doubled means Nvidia sold far more silicon, not less. Share down, revenue way up.
- The real split is training versus inference. Frontier training still runs on Nvidia because CUDA and NVLink are a moat. Inference is where TPUs, Trainium, and Maia are quietly eating in, and inference is where most of my spend lives.
- If you are not a hyperscaler, custom silicon barely exists for you. You cannot buy a Trainium or a TPU outside AWS and Google Cloud. For everyone else the practical choice is still Nvidia versus AMD, and AMD’s MI350 finally makes that a real choice on price.
- Watch Broadcom and Marvell, not just the chip badges. The ASIC surge is really a co-design boom, and those two firms capture most of the margin behind Google, Meta, and OpenAI silicon.
- My rule for 2026: train where the ecosystem is deepest, serve where the cost-per-token is lowest. That single split explains the entire market-share map below.
Frequently asked questions
Estimates put Nvidia at roughly 70 to 75 percent of data-center AI accelerator revenue in 2026, down from a peak near 87 percent in 2024. Despite the lower share, Nvidia’s revenue is at record highs because the overall market roughly doubled; its data-center segment alone reported $75.2 billion in Q1 FY2027, up 92 percent year over year.
AMD is gaining ground but has not closed the gap. In Q1 2026 it posted $5.8 billion in data-center revenue, up 57 percent year over year, driven by the Instinct MI350, and HSBC projects roughly $15 billion in AI chip sales for the full year. AMD’s MI350 offers more on-chip memory and lower cost, making it a credible second source for inference, but its ROCm software still trails Nvidia’s CUDA for frontier training.
Custom AI chips, or ASICs, are accelerators a company designs for its own workloads rather than buying off the shelf. The major examples in 2026 are Google’s TPU (Ironwood v7 and the new 8t/8i), Amazon’s AWS Trainium, Microsoft’s Maia 200, and Meta’s MTIA. They are built with co-design partners Broadcom and Marvell and are used inside each company’s cloud rather than sold on the open market.
Because the market is growing faster than any one vendor can capture. The 2026 data-center accelerator market exceeds $200 billion, so Nvidia can lose percentage points to AMD and custom silicon while still selling far more chips than the year before. Share down and revenue up are both true at the same time.
They are a real threat in inference but not yet in training. Custom ASIC shipments are growing about 44.6 percent year over year versus 16.1 percent for merchant GPUs, and ASIC-based servers may reach about 27.8 percent of accelerator-server shipments in 2026. However, Nvidia still dominates frontier model training because of CUDA and NVLink, and most custom chips target high-volume, cost-sensitive inference instead.
If you are not a hyperscaler, your real choice is Nvidia versus AMD, since TPUs, Trainium, and Maia are only available inside their owning clouds. The practical approach is to benchmark cost-per-token across AWS, Google Cloud, and Nvidia-based instances; the same model can differ 30 to 50 percent in cost. Train where the software ecosystem is deepest and serve where the cost per token is lowest.
Primary sources
- Nvidia Q1 FY2027 results (8-K) — U.S. SEC / Nvidia
- AMD Q1 2026 data center revenue — DatacenterDynamics
- Custom AI ASIC state of play, May 2026 — Tom’s Hardware
- Custom AI chips outpace Nvidia GPU growth in 2026 — Tech Times
- Google launches training and inference TPUs — CNBC
- Nvidia AI accelerator market share 2024-2026 — Silicon Analysts
- Bloomberg Intelligence AI accelerator market forecast — Bloomberg
Last updated: May 31, 2026. Related: Capital.




