


A neutral, latency-budget-first decision table for production RAG: Jina v3, Cohere Rerank 4, Voyage 2.5 and Zerank 2 compared on accuracy, latency, cost and self-host.
Which is the best reranker model 2026, really?
There is no single best reranker model 2026 — the right choice is decided by your latency budget first, then accuracy, cost and data residency. For sub-200ms production RAG, Jina Reranker v3 is the only top-tier model that fits; for accuracy-maximized pipelines that can absorb ~600ms, Cohere Rerank 4 Pro and Voyage Rerank 2.5 lead; for self-hosting and data residency, open-weight Jina v3 or Zerank are the answers.
Every incumbent guide gets this wrong in the same way. The leaderboards (Agentset, AIMultiple) hand you raw ELO and nDCG@10 columns and let you assume the top row wins. The vendor guides (ZeroEntropy, Jina, Cohere) each conclude that their own reranker is best. None of them start where a builder actually starts: with a request budget and a deployment constraint.
A reranker is a cross-encoder (or, increasingly, a listwise model) that re-scores the candidate documents your vector search already pulled, so the most relevant chunks land at the top before they hit the LLM context. It is the single highest-leverage accuracy upgrade in a RAG pipeline — and, inconveniently, it is also a synchronous hop that the user waits on. That tension is the whole story.
So we built the comparison the incumbents skipped: a latency-budget-first decision table across the four models builders actually shortlist in 2026 — Cohere Rerank 4 Pro, Voyage Rerank 2.5, Jina Reranker v3, and Zerank 2 — scored on accuracy, latency, cost-per-query, multilingual reach, and self-host vs API-only. Pick your budget, read across, ship.
Reranker comparison table: accuracy, latency, cost and self-host
The short version: Jina v3 owns the sub-200ms frontier and is the only one you can self-host freely; Cohere 4 Pro and Voyage 2.5 trade ~3x the latency for marginally higher accuracy; Zerank 2 tops the ELO board but is non-commercial-licensed and API-gated for production.
All four cluster within a few points on quality once your retrieval top-k is reasonable. They do not cluster on latency or licensing — that is where the real decision lives. The table below is the artifact to bookmark.
Two caveats on reading it. First, latency figures are average end-to-end for a representative ~100-document, short-query rerank; your numbers move with document length and candidate count (more on that below). Second, ELO and nDCG@10 measure relevance ranking on benchmark corpora, not your corpus — treat a sub-15-point ELO gap as a tie.
“The reranker is usually the slowest synchronous hop in a RAG request. Pick it against a stopwatch, not a leaderboard.”
Surya Koritala, founder of Cyntr and Loomfeed
| Model | Quality (ELO / nDCG@10) | Avg latency | Deployment | List / pricing | Best for |
|---|---|---|---|---|---|
| Jina Reranker v3 | 61.94 nDCG@10 (BEIR); ~81.3% Hit@1 | ~188 ms | Open-weight, self-host (HF / GGUF / MLX) + API | Open weights; pay-per-token API | Sub-200ms latency budgets, data residency, multilingual |
| Cohere Rerank 4 Pro | 1629 ELO | ~614 ms | API-only (closed) | ~$2 / 1k searches; Model Vault $5–10/hr | Accuracy-max enterprise RAG, semi-structured JSON |
| Voyage Rerank 2.5 | 1544 ELO; high nDCG@10 | ~613 ms | API-only (closed) | $0.05 / 1M tokens; first 200M free | Accuracy + generous free tier, embedding co-stack |
| Zerank 2 | 1638 ELO (leaderboard #1) | ~265 ms | Self-hostable weights + API | CC BY-NC 4.0 (non-commercial weights) | Research / internal eval; not free for commercial self-host |
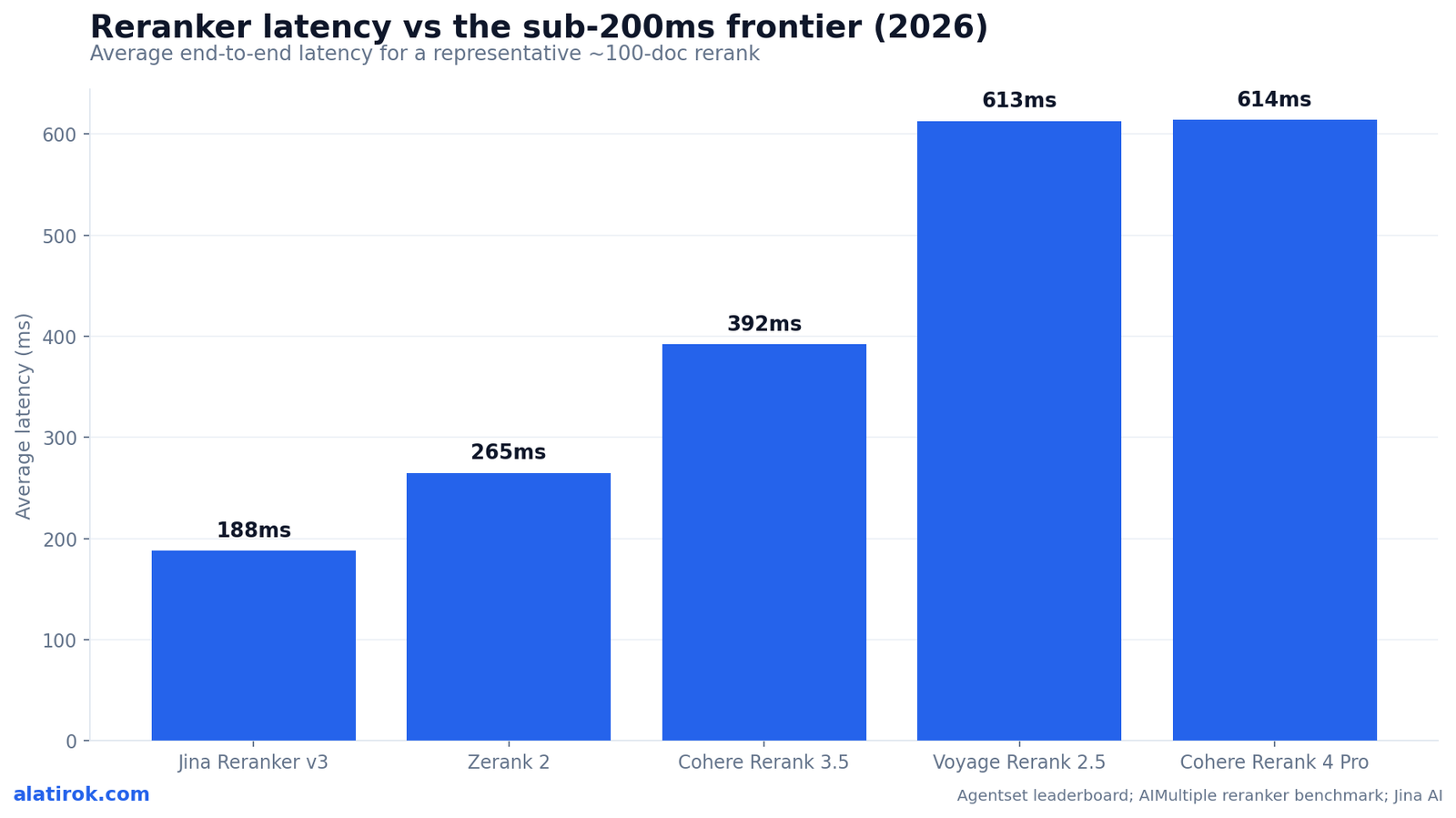
Reranker latency benchmark: why sub-200ms is the real axis
Reranking is the moment in a RAG pipeline where milliseconds compound, because it runs synchronously between retrieval and generation — the user is already waiting. Jina Reranker v3 hits roughly 188ms for a top-tier rerank, while Voyage Rerank 2.5 and Cohere Rerank 3.5 land around 595–614ms on the same kind of workload, making latency, not nDCG, the deciding variable for interactive apps.
Here is the number that reframes the whole decision: reranking 100 candidate documents can take anywhere from ~100ms to ~7 seconds depending on document length and query complexity (AIMultiple). That two-order-of-magnitude spread is far wider than the accuracy spread between models. A pipeline that feels instant or feels broken is usually decided by reranker latency, not retrieval recall.
Jina v3 gets to ~188ms partly through architecture — it is a 597M-parameter listwise model (built on Qwen3-0.6B) that scores up to 64 documents together in a single 131k-token forward pass, rather than running N independent cross-encoder passes. Zerank 2 sits around 265ms. Cohere 4 Pro (~614ms) and Voyage 2.5 (~613ms) are the accuracy-leaning end of the field, not the latency-leaning end.
Translate that into product terms. If your reranker is on the critical path of a synchronous chat or search response, you have roughly a 200ms budget before it becomes the thing users notice. If reranking happens in a batch job, an async pre-compute, or behind a streaming buffer, the 600ms models are completely fine and you should optimize for accuracy and cost instead.
Interactive, user-waiting RAG: stay under ~200ms total reranking — Jina v3 territory. Async, batch, or buffered-stream RAG: spend the latency, optimize for accuracy and cost — Cohere or Voyage territory.
Cohere Rerank vs Jina reranker: closed accuracy vs open speed
Cohere Rerank vs Jina reranker is the cleanest fork in the decision: Cohere Rerank 4 Pro is a closed, API-only model tuned for top-end accuracy (1629 ELO) and rich enterprise inputs, while Jina Reranker v3 is open-weight, self-hostable, multilingual, and roughly 3x faster at ~188ms. Choose Cohere for managed accuracy-max; choose Jina for latency, residency, and cost control.
Cohere’s strengths beyond the ELO score are operational. A Cohere rerank “search unit” is one query against up to 100 documents, and documents over 500 tokens are auto-chunked with each chunk scored separately — so long, messy enterprise documents get handled without you writing chunking logic. Cohere Rerank also handles multilingual queries and semi-structured JSON fields, which matters when your corpus is support tickets or product records rather than clean prose.
Jina v3’s strengths are structural. It ships open weights on Hugging Face (plus GGUF and MLX builds for Apple Silicon), supports 93 languages, posts 61.94 nDCG@10 on BEIR, and — critically — never requires a document to leave your infrastructure. For regulated data (health, finance, EU residency), that single property can be the entire decision, regardless of a few ELO points.
The honest trade: with Cohere you rent accuracy you cannot reproduce, version-pin to a frozen snapshot, or run inside a VPC without their Model Vault ($5–10/hr per instance). With Jina you own the model but inherit the GPU ops, autoscaling, and the work of actually hitting 188ms in your own stack. Neither is universally better — they optimize for different constraints.
Pros
Cons
Voyage rerank vs Cohere, and Zerank vs Cohere Rerank 4
Voyage rerank vs Cohere is nearly a wash on the accuracy/latency axis — Voyage Rerank 2.5 (1544 ELO, ~613ms) and Cohere Rerank 4 Pro (1629 ELO, ~614ms) are both API-only and both ~600ms — so the tiebreakers are pricing model and whether you already run Voyage embeddings. Zerank vs Cohere Rerank 4 is the opposite story: Zerank 2 actually tops the ELO board (1638 vs 1629) and is faster (~265ms), but its weights are CC BY-NC 4.0, which blocks commercial self-host.
Voyage’s pricing is the most builder-friendly of the closed options: $0.05 per million tokens for rerank-2.5 ($0.02 for the lite variant), with the first 200M tokens free per account. Voyage counts tokens as (query tokens x number of documents) + sum of all document tokens, so cost scales with candidate count — another reason to rerank 25–40 docs instead of 100. If you already embed with Voyage, keeping the reranker in the same stack reduces vendor surface area.
Cohere bills by the “search” (one query, up to 100 docs) at roughly $2 per 1,000 searches on the consumption tier, or per-instance via Model Vault. For high-QPS, small-candidate workloads the per-search model can be cheaper and more predictable than per-token; for low-QPS, large-document workloads Voyage’s free tier and token pricing often win. Model the two against your actual query shape — the crossover point is real.
Zerank 2 is the leaderboard darling and deserves a clear-eyed note: its top ELO (1638) and ~265ms latency look ideal, but the CC BY-NC 4.0 license means you cannot legally self-host the weights in a commercial product. In practice that makes Zerank a strong choice for internal evaluation, research, and benchmarking — and a model you consume via API rather than self-host — when shipping commercially. Read the license before you architect around it.
Zerank 2’s chart-topping ELO comes with a CC BY-NC 4.0 (non-commercial) weights license. Great for internal eval and research; not a free commercial self-host. If “open source reranker alternatives to Cohere” is your real requirement, Jina Reranker v3 is the commercially-usable open-weight pick.
Which reranker model should I use? A latency-budget decision tree
Pick by your hardest constraint, in this order: (1) data residency — must documents stay in your infra? Then Jina v3 self-hosted. (2) Latency — is reranking on a synchronous, user-waiting path under ~200ms? Then Jina v3. (3) Accuracy-max with async tolerance? Then Cohere Rerank 4 Pro or Voyage Rerank 2.5. (4) Cost-sensitive with a Voyage embedding stack? Then Voyage Rerank 2.5 and its 200M free tokens.
Start with the constraint you cannot negotiate. Data residency is binary — either documents can leave your network or they cannot — so it overrides everything else and points you straight to a self-hosted open-weight model. Jina v3 is the commercially-usable answer there; Zerank’s non-commercial license takes it off the table for shipped products.
If residency is not a hard constraint, latency is the next gate. Map where reranking sits in your request. On a synchronous chat or search response, the ~200ms budget makes Jina v3 the default. Behind a streaming buffer, a batch pipeline, or an async pre-compute, you can spend ~600ms and should optimize for accuracy and cost instead — which is Cohere and Voyage’s home turf.
Then, and only then, look at the leaderboard. Among the ~600ms accuracy-leaners, Cohere 4 Pro edges Voyage 2.5 on ELO, Voyage wins on free-tier economics and token-based pricing, and Cohere wins on long-document auto-chunking and semi-structured inputs. These are real but small differences — far smaller than the latency and licensing gates you already passed through. And before you switch models for accuracy, cut your candidate set: reranking 30 well-retrieved docs usually beats reranking 100 mediocre ones, faster and cheaper.
Reranking is one layer of the retrieval stack. To land the whole pipeline, pair your reranker choice with the right embedding model and vector database, and wire it into a RAG flow that retrieves a generous candidate set, reranks down to a tight top-k, and only then calls the LLM.
One-line answer: default to Jina Reranker v3 for anything interactive or residency-bound; reach for Cohere Rerank 4 Pro or Voyage Rerank 2.5 only when you have an async latency budget and want the lasWhere each reranker breaks in a real pipeline
Every reranker degrades on the same two pressures — long documents and large candidate sets — but they degrade differently, and knowing the failure mode prevents a 200ms model from quietly becoming a 7-second one in production.
Document length is the silent latency multiplier. The ~188ms and ~600ms figures assume short queries and modest documents. Push 3k+ token chunks through and Cohere’s auto-chunking helpfully preserves accuracy but multiplies the effective document count (each chunk is scored, max chunk score wins). Voyage’s token-based billing means cost climbs with document length too. Jina’s 131k-token listwise window absorbs more before it stalls, but a forward pass over very long contexts is still a forward pass.
Candidate count is the other cliff. Latency and cost both scale with how many documents you ask the reranker to score. Teams routinely pass 100 candidates out of habit when a well-tuned retriever delivers the same final answer at top-25. Trimming the candidate set is the cheapest, highest-leverage optimization in the entire pipeline — do it before you change models.
Self-hosted models have a different break point: cold starts, batch inefficiency, and under-provisioned GPUs. Jina v3 at 188ms assumes a warm, properly-batched deployment on adequate hardware. Run it on a cold serverless GPU with batch size 1 and your real latency can be several times the benchmark. The open-weight advantage is real, but it comes with a serving-infrastructure obligation that the API vendors handle for you.
Finally, multilingual and structured-data edges matter at the margins. Cohere explicitly handles semi-structured JSON and multilingual queries; Jina v3 covers 93 languages but is text-only with no native image reranking. If your corpus is multimodal, none of these four is a complete answer today — you are looking at a separate multimodal retrieval design, not a drop-in reranker swap.
My reranker latency spiked in production — what changed?
Almost always one of three things: document length grew (longer chunks = more tokens per pass), candidate count grew (you are reranking 100 docs instead of 30), or a self-hosted model is cold/under-batched. Check candidate count and chunk size first — they are free to fix. For API models, latency creep usually means your documents got longer; trim or pre-chunk them.Do I even need a reranker, or is good embedding retrieval enough?
If your top-k from pure vector search already puts the right answer in the LLM’s context most of the time, a reranker buys you precision at the top of the list — meaningful for terse answers, citations, and tight context budgets. Rerankers typically add 15–40% retrieval accuracy over embeddings alone, but they add a synchronous latency hop. Add one when answer quality is gated by which chunk lands first, not when recall is your problem.Can I mix vendors — Cohere embeddings with a Jina reranker?
Yes. Embedding and reranking are independent stages and the reranker only consumes raw query/document text, not the embedding vectors. Many production stacks pair one vendor’s embeddings with another’s reranker (or a self-hosted reranker) precisely to optimize each stage’s latency, cost, and residency separately. The reranker does not care where your candidates came from.Verdict: the best reranker for RAG depends on your latency budget
Default to Jina v3; reach for Cohere or Voyage only when you have an async latency budget
The best reranker for RAG in 2026 is the one that fits your hardest constraint — residency, then latency, then accuracy and cost — not the one at the top of an ELO board. For most production pipelines that means Jina Reranker v3 by default, with Cohere Rerank 4 Pro or Voyage Rerank 2.5 as the accuracy-max upgrade when you can afford ~600ms.
Cross-link this decision to the rest of your retrieval stack: the embedding model determines candidate recall, the vector database determines retrieval latency, and the reranker determines final precision. Get all three from one decision pass and you ship the whole pipeline, not just a leaderboard pick.
Builder’s take
I run retrieval inside Cyntr’s orchestration engine and Loomfeed’s discussion ranking, so I pick rerankers against a stopwatch, not a leaderboard. The thing nobody tells you: the reranker is usually the slowest synchronous hop in a RAG request, and it sits on the critical path before the LLM even starts streaming.
- Set your latency budget first. If the user is waiting on a synchronous answer, you have ~200ms for reranking before it becomes the bottleneck. That single constraint eliminates more than half the field before you ever look at nDCG.
- The ELO leaderboards are measuring a different game than you are playing. A 9-point ELO gap between Zerank 2 and Cohere 4 Pro is noise once your top-k retrieval is decent; a 400ms latency gap is not.
- Self-host is a data-residency and unit-economics decision, not a quality one. Jina v3 self-hosted on your own GPU has zero per-query API cost and never ships customer documents to a third party. At Cyntr’s volume that math flips hard.
- Rerank fewer documents. Most teams pass 100 candidates when 25-40 would give the same final answer at a third of the latency and cost. Tune top-k before you switch models.
- Closed APIs are fine until they aren’t. Cohere and Voyage are excellent, but you are renting accuracy you cannot reproduce, version-pin, or run in a VPC. Budget for that lock-in the same way you would for any closed dependency.
Frequently asked questions
There is no universal winner — it depends on your latency budget. For sub-200ms interactive RAG, Jina Reranker v3 (~188ms, 61.94 nDCG@10, open-weight) is the standout. For accuracy-maximized async pipelines that can absorb ~600ms, Cohere Rerank 4 Pro (1629 ELO) and Voyage Rerank 2.5 (1544 ELO) lead. For data residency, self-host Jina v3. Pick your hardest constraint first, then read across the comparison table.
Cohere Rerank 4 Pro wins on managed accuracy (1629 ELO), long-document auto-chunking, and semi-structured JSON handling, but it is closed, API-only, and ~614ms. Jina Reranker v3 wins on latency (~188ms), is open-weight and self-hostable, covers 93 languages, and keeps documents in your infrastructure. Choose Cohere for hands-off accuracy-max; choose Jina for interactive latency, data residency, and marginal cost control.
Jina Reranker v3 is the only top-tier reranker that clears the ~200ms interactive frontier, at roughly 188ms for a representative rerank. It uses a listwise architecture that scores up to 64 documents together in one 131k-token forward pass. Zerank 2 is next at ~265ms, while Cohere Rerank 4 Pro and Voyage Rerank 2.5 sit near ~600ms and are better suited to async or buffered pipelines.
Yes. Jina Reranker v3 is the leading commercially-usable open-weight option — self-hostable via Hugging Face, GGUF, and MLX, with 93-language support and 61.94 nDCG@10 on BEIR. Note that Zerank 2, despite topping the ELO leaderboard, ships under a CC BY-NC 4.0 non-commercial license, so it is not a free commercial self-host. For a shipped product, Jina v3 is the open alternative to Cohere’s closed API.
Voyage Rerank 2.5 costs $0.05 per million tokens (rerank-2.5-lite is $0.02), with the first 200M tokens free per account, billed as (query tokens x docs) + all document tokens. Cohere bills by the search — one query against up to 100 documents — at roughly $2 per 1,000 searches on the consumption tier, or per-instance via Model Vault ($5–10/hr). High-QPS small-candidate loads favor Cohere’s per-search model; low-QPS or document-heavy loads often favor Voyage’s free tier and token pricing.
Reranking time scales with document length and candidate count. Scoring 100 short documents can finish in ~100ms; scoring 100 long documents with a complex query can take up to ~7 seconds because every document is run through the model. The two biggest levers you control are candidate count (rerank 30 docs, not 100) and chunk size. Trimming both is the cheapest production optimization before you ever switch reranker models.
Primary sources
- Best Rerankers for RAG Leaderboard (ELO, nDCG, latency) — Agentset
- Reranker Benchmark: Top 8 Models Compared — AIMultiple
- jina-reranker-v3 model card — Jina AI
- jina-reranker-v3: Last but Not Late Interaction for Document Reranking — arXiv
- Ultimate Guide to Choosing the Best Reranking Model — ZeroEntropy
- How Does Cohere’s Pricing Work — Cohere
- Cohere Pricing — Cohere
- Voyage AI Pricing — Voyage AI
Last updated: June 2, 2026. Related: Agent Infrastructure.




