


Anthropic’s $1.5B payout reset the price of pirated training data. Here is the full ledger of AI copyright settlements, per-work damages, and the labels, papers, and publishers still fighting.
What the AI copyright lawsuit settlement 2026 wave actually established
$1.5B
Total Bartz v. Anthropic settlement
Largest copyright recovery in U.S. history
$3,000
Net payment per work
Across 482,460 covered books
91.3%
Claim rate
440,490 of 482,460 works claimed
$70B+
Theoretical statutory exposure
At up to $150,000 per willful work
The defining AI copyright lawsuit settlement 2026 milestone is Bartz v. Anthropic: a $1.5 billion class settlement covering 482,460 books at roughly $3,000 per work, the largest copyright recovery in U.S. history. It did not resolve whether training an AI model on copyrighted text is fair use. It resolved something narrower and more expensive: that acquiring your training corpus from pirate shadow libraries carries a price, and that price is now public.
That distinction matters more than the headline number. Judge William Alsup had already ruled in mid-2025 that training Claude on lawfully acquired books was transformative. What pushed Anthropic to the table was the separate allegation that it downloaded roughly 7 million copies from LibGen and PiLiMi over BitTorrent. With statutory damages reaching $150,000 per willfully infringed work, the company’s theoretical exposure exceeded $70 billion. A $1.5 billion settlement was, in the words of one widely cited analysis, a ‘speeding ticket.’
The settlement also produced something the industry had never had: a per-work clearing price. Strip out the up-to-25% attorney fee request (about $375 million), administrative costs, and $50,000-per-plaintiff service awards, and rights-holders net roughly $3,000 per title. When 440,490 of 482,460 eligible works were claimed, a 91.3% claim rate against a typical class-action rate near 10%, the math held close to that $3,000 figure. Every AI lab now has a number to model against.
The final fairness hearing took place May 14, 2026 before Judge Araceli Martínez-Olguín, who took the matter under submission after the case was reassigned from Alsup. The settlement administrator is scheduled to calculate distributions by June 11, 2026. Approval looked likely; the judge barely pressed counsel on the deal’s contours.

Bartz did not criminalize AI training. It priced the difference between buying your training data and pirating it. Provenance, not abstinence, is the takeaway.
AI copyright exposure by the dollar: the settlement ledger
Two numbers anchor Anthropic‘s 2026 copyright ledger: the $1.5 billion it agreed to pay book authors, and the $3.1 billion a coalition of music publishers is now demanding on top of it. Together they show that a single AI company can face billion-dollar claims across multiple media simultaneously, and that one settlement does nothing to close the others.
On January 28, 2026, Universal Music Publishing Group, Concord, and ABKCO filed a fresh suit accusing Anthropic of ‘flagrant piracy’ of song lyrics, identifying 20,517 specific works, from ‘Sweet Caroline’ to ‘Bennie and the Jets,’ allegedly ingested via the same BitTorrent shadow-library method at issue in Bartz. The complaint, seeking up to roughly $3.1 billion, names CEO Dario Amodei and cofounder Benjamin Mann as having personally directed the acquisition. Music Business Worldwide called it potentially the single largest non-class-action copyright case in U.S. history.
The chart below puts the two figures side by side. The books settlement is a known, agreed number. The publishing claim is a demand, not a verdict, but it sits on the same factual spine, which is exactly why it is dangerous: if the torrenting allegations are proven for books, they are hard to un-prove for lyrics.
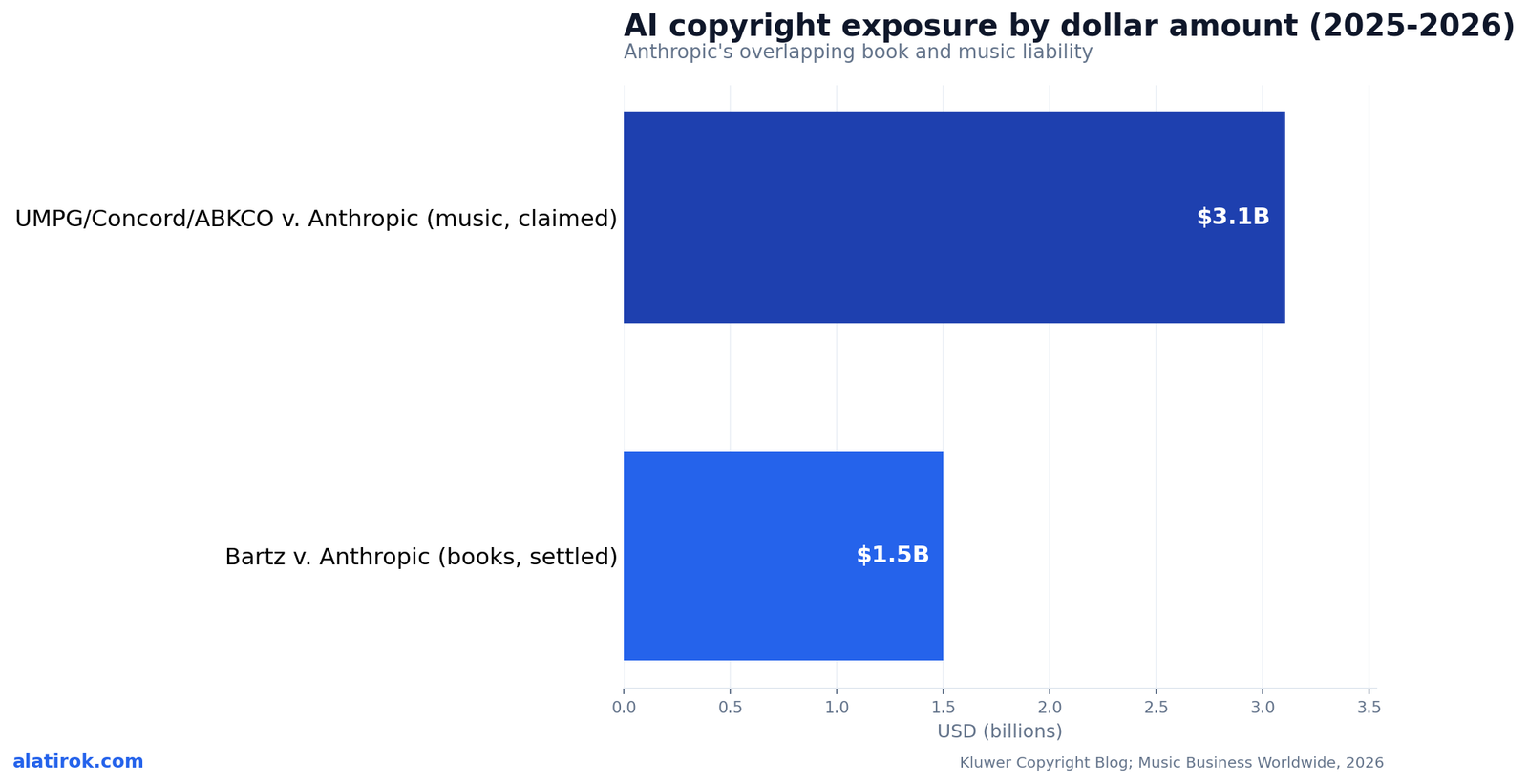
“Settlement is not a moat. Paying one class of rights-holders does not extinguish a different rights-holder in a different medium.”
The lesson of Anthropic’s overlapping 2026 dockets
Who has settled and who is still fighting: the status matrix
As of May 2026, the AI copyright map splits cleanly: book and music settlements are clustering, while news and image disputes remain in open court, and one major label, Sony Music, has settled with nobody. The table below tracks five AI defendants across the four contested media, anchored to a litigation tracker that monitored roughly 166 cases in April and 177 by late May.
The pattern is medium-specific. Music labels are settling fast and pairing settlements with licensing, because a licensed AI platform is a new revenue line they would rather own than litigate. Book authors took a cash class settlement. News publishers and image libraries, by contrast, are pressing for precedent: the New York Times wants a ruling, not a check, and Getty has now lost the core of its UK copyright claim while keeping its U.S. case alive.
Read the matrix as a snapshot of leverage. ‘Settled’ means a price was agreed. ‘Active’ means the parties still believe a ruling will move that price. ‘Decided-in-part’ means a court has already spoken and narrowed the fight.
The 166-to-177 case count spans copyright, privacy, scraping, and biometric claims across 54 defendants, verified weekly from primary dockets. Roughly 114 are copyright-specific. Treat any single ‘total’ as a moving number.
| Defendant | Books | Music | News | Images |
|---|---|---|---|---|
| Anthropic | Settled ($1.5B) | Active ($3.1B claim) | — | — |
| OpenAI | Active (output claims live) | — | Active (NYT, ≥$1B) | — |
| Suno | — | Settled (Warner) / Active (Sony) | — | — |
| Udio | — | Settled (UMG) / Active (Sony) | — | — |
| Stability AI | — | — | — | Decided-in-part (UK) / Active (US) |
Books: the output door OpenAI could not close
Anthropic settled the books fight, but OpenAI is still in it, and on October 27, 2025 Judge Sidney Stein handed authors their most important procedural win to date by refusing to dismiss claims that ChatGPT’s outputs themselves infringe. That ruling, in the consolidated In re OpenAI / Authors Guild litigation, kept alive a theory far more threatening to AI labs than the training-data question.
Most fair-use debate has focused on the input side: is it lawful to train on copyrighted books at all? Stein’s opinion opened the output side. He pointed to two ChatGPT responses summarizing George R.R. Martin novels and found a reasonable jury could conclude they were ‘substantially similar’ to the originals because they reproduced copyrightable elements, setting, plot, and characters. He pointedly did not decide fair use; courts reserve that for summary judgment.
Why this matters for builders: a training-fair-use win does not immunize a model that regurgitates protected expression on demand. The two questions are legally distinct, and the output theory is the one that survives even if labs eventually win on training. Class certification now looms in the same case, which would dramatically raise the stakes by aggregating thousands of authors into a single damages pool, exactly the dynamic that drove Anthropic to settle.
OpenAI faces this on two fronts at once: the authors’ output claims and the New York Times’s parallel newspaper case, both in the Southern District of New York, both moving toward summary-judgment-stage decisions in 2026.
Training fair use and output infringement are separate fights. A lab can win the first and still lose the second. Stein’s October 2025 ruling is the reason output similarity is now the live frontier.Music: settle-and-license is beating litigate-and-wait
The music industry has chosen a different exit than authors: instead of cash-only class settlements, the major labels are pairing settlements with licensing deals that turn AI music generators into business partners. Two of the three majors have already crossed that line.
Universal Music Group settled with Udio on October 29, 2025, agreeing to co-develop a ‘walled-garden’ AI music platform launching in 2026, with UMG artists able to opt into training in exchange for compensation on both data usage and generated outputs. Warner Music followed on November 25, 2025, settling with Suno in a deal that included a multi-million-dollar payment, a licensing partnership, new models with download restrictions and an opt-in voice/likeness program, and Suno acquiring Warner’s Songkick concert-discovery platform.
Sony Music is the holdout. It has settled with neither Suno nor Udio and is litigating both, the Suno case in Massachusetts and the Udio case in the Southern District of New York, while seeking discovery into the confidential Warner-Suno terms. A pivotal fair-use ruling on Sony’s cases is expected in summer 2026, with a key Suno summary-judgment hearing slated for July. Suno and Udio argue training on recordings is transformative fair use; Sony argues it is infringement at industrial scale.
The strategic split is instructive. Settling labels get a new licensed revenue stream and a seat at the table. Sony is betting that a favorable precedent is worth more than an early check, the same calculation the New York Times is making in news.
Pros
Cons
News and images: where the precedent fights are still live
News and images are the two media where rights-holders are deliberately refusing to settle, betting that a court ruling will be worth more than any negotiated payout. Here the AI copyright lawsuit settlement 2026 trend reverses: nobody is cashing out.
In news, the New York Times’s suit against OpenAI and Microsoft, filed in December 2023, alleges the unauthorized copying of millions of articles and seeks damages described as reaching into the billions, with the tracker logging a claim of at least $1 billion. Discovery has been bruising: OpenAI lost a privacy fight that put roughly 20 million ChatGPT conversation logs on a path toward the plaintiffs, and the case has moved toward summary-judgment-stage resolution in 2026. The Times wants a ruling that training on its journalism without a license is infringement, a precedent that would reverberate across every news-trained model.
In images, Getty Images delivered a cautionary tale for rights-holders. On November 4, 2025, the High Court of England and Wales largely rejected Getty’s copyright claims against Stability AI, holding that Stable Diffusion’s model weights are not an infringing ‘copy’ under UK law, after Getty had abandoned its primary copyright and database-right claims when it conceded the training did not occur in the UK. Getty salvaged only a narrow, ‘historic and extremely limited’ trademark win over watermarks. Its separate U.S. case, refiled in the Northern District of California, remains active, with fact discovery scheduled to close September 18, 2026.
The split outcome explains why the next twelve months matter so much. A clean rights-holder win in NYT v. OpenAI or Sony’s music cases would push every AI lab toward licensing. A clean defense win, like Getty’s UK loss, would embolden labs to keep training and litigating rather than pay.
Cash settlements bind only the parties to them. A favorable ruling binds an entire jurisdiction. The Times, Sony, and Getty are each spending on litigation to buy precedent, not just damages.
What builders should actually do with this in 2026
Provenance is now priced. Output is now litigated.
The operational takeaway for anyone shipping AI products is that data provenance has graduated from a compliance checkbox to a balance-sheet line item with a known unit price. Bartz turned ‘where did your training data come from’ into a question with a $3,000-per-work answer.
First, log acquisition. Anthropic’s fatal exposure came from how it obtained books, torrenting shadow libraries, not from the act of training. Lawfully sourced corpora drew a fair-use ruling in Anthropic’s favor; the pirated ones drew a $1.5 billion bill. The single highest-leverage control you have is a verifiable record of where every training document came from.
Second, budget for serial, multi-medium exposure. The $3.1 billion music-publishing suit landed after the books settlement, against the same defendant, on the same alleged facts. If your model touched text, lyrics, images, and articles, assume four separate plaintiff classes, not one.
Third, treat outputs as a distinct risk surface. Stein’s ruling means an architecture that can regurgitate protected expression is a liability even if your training survives fair use. Retrieval-with-attribution, output filtering, and similarity guards are not nice-to-haves; they address the one theory that survives a training-side defense win. Watch summer 2026: Sony’s fair-use ruling and the NYT and OpenAI summary-judgment decisions will reprice this entire table.
Builder’s take
I build products that ingest the open web for a living, so I read these dockets the way other founders read term sheets. The Anthropic number is not a fine. It is a market price.
- The lesson of Bartz is provenance, not abstinence. Anthropic did not lose on training, it lost on how it acquired the corpus: torrenting LibGen and PiLiMi. Buy the books, log the source, keep the receipts, and your exposure drops by an order of magnitude.
- Settlement is not a moat. UMG, Concord, and ABKCO filed a fresh $3.1B suit against Anthropic in January 2026, after the books deal. Paying one class does not extinguish a different rights-holder in a different medium. Budget for serial exposure.
- Per-work math is now a real line item. At roughly $3,000 a book, a half-million-title corpus is a $1.5B liability. If you cannot name every source in your training set, you cannot price your own risk, and neither can your acquirer.
- The output door is the scary one. Judge Stein let the ChatGPT output-similarity claims survive. Training fair use is one fight; a model that regurgitates a Game of Thrones plot is a different, harder one. At Cyntr we treat retrieval-with-attribution as the safe default precisely because it sidesteps that door.
Frequently asked questions
Anthropic agreed to pay $1.5 billion to settle Bartz v. Anthropic, the largest copyright recovery in U.S. history. The fund covers 482,460 books at roughly $3,000 per work after attorney fees (up to 25%, about $375 million), administrative costs, and service awards. A 91.3% claim rate kept the per-work payout close to the headline figure.
Rights-holders net approximately $3,000 per title, shared among any co-owners of that work. The figure derives from dividing the $1.5 billion fund across roughly 500,000 eligible books after costs. Because 440,490 of 482,460 eligible works were claimed, the actual payout stayed close to that $3,000 estimate rather than being diluted.
Public litigation trackers logged roughly 166 AI-related cases in April 2026, rising to about 177 by late May across 54 defendants, with roughly 114 classified as copyright-specific. The count spans copyright, privacy, data-scraping, deepfake, and biometric claims and is verified weekly from primary court dockets, so the total moves as cases are filed and resolved.
Universal Music Group settled with Udio on October 29, 2025, and Warner Music settled with Suno on November 25, 2025, both pairing payment with licensing deals and 2026 platform launches. Sony Music has settled with neither and continues litigating both companies, with a pivotal fair-use ruling expected in summer 2026.
No. On January 28, 2026, after the books settlement, Universal Music Publishing Group, Concord, and ABKCO filed a new suit seeking up to roughly $3.1 billion over 20,517 song lyrics allegedly pirated via the same shadow-library method. Settling one class of rights-holders does not extinguish claims from a different rights-holder in a different medium.
On October 27, 2025, Judge Sidney Stein refused to dismiss claims that ChatGPT’s outputs infringe, citing two responses summarizing George R.R. Martin novels that a jury could find substantially similar to the originals. The ruling kept the output-infringement theory alive as a fight distinct from training fair use, and class certification now looms in the case.
Primary sources
- The Bartz v. Anthropic Settlement: Understanding America’s Largest Copyright Settlement — Kluwer Copyright Blog
- Anthropic Settlement Update: 91.3 Percent of Books Claimed — The Authors Guild
- Bartz v. Anthropic Fairness Hearing: Observations and Takeaways — Authors Alliance
- Anthropic to pay authors $1.5 billion in settlement over chatbot training material — NPR
- AI Lawsuit Tracker (2026) — ailawsuittracker.com
- UMG, Concord and ABKCO sue Anthropic for $3bn — Music Business Worldwide
- OpenAI Can’t Dismiss Claims ChatGPT Outputs Infringe Copyrights — Bloomberg Law
- Getty Images v Stability AI: The UK Courts’ First Word on Use of Copyright Works — Paul, Weiss
- Warner Music Group strikes ‘landmark’ deal with Suno — Music Business Worldwide
- Music Industry AI Lawsuits Tracker 2026: Live Status — Chartlex
Last updated: June 1, 2026. Related: Governance.




