

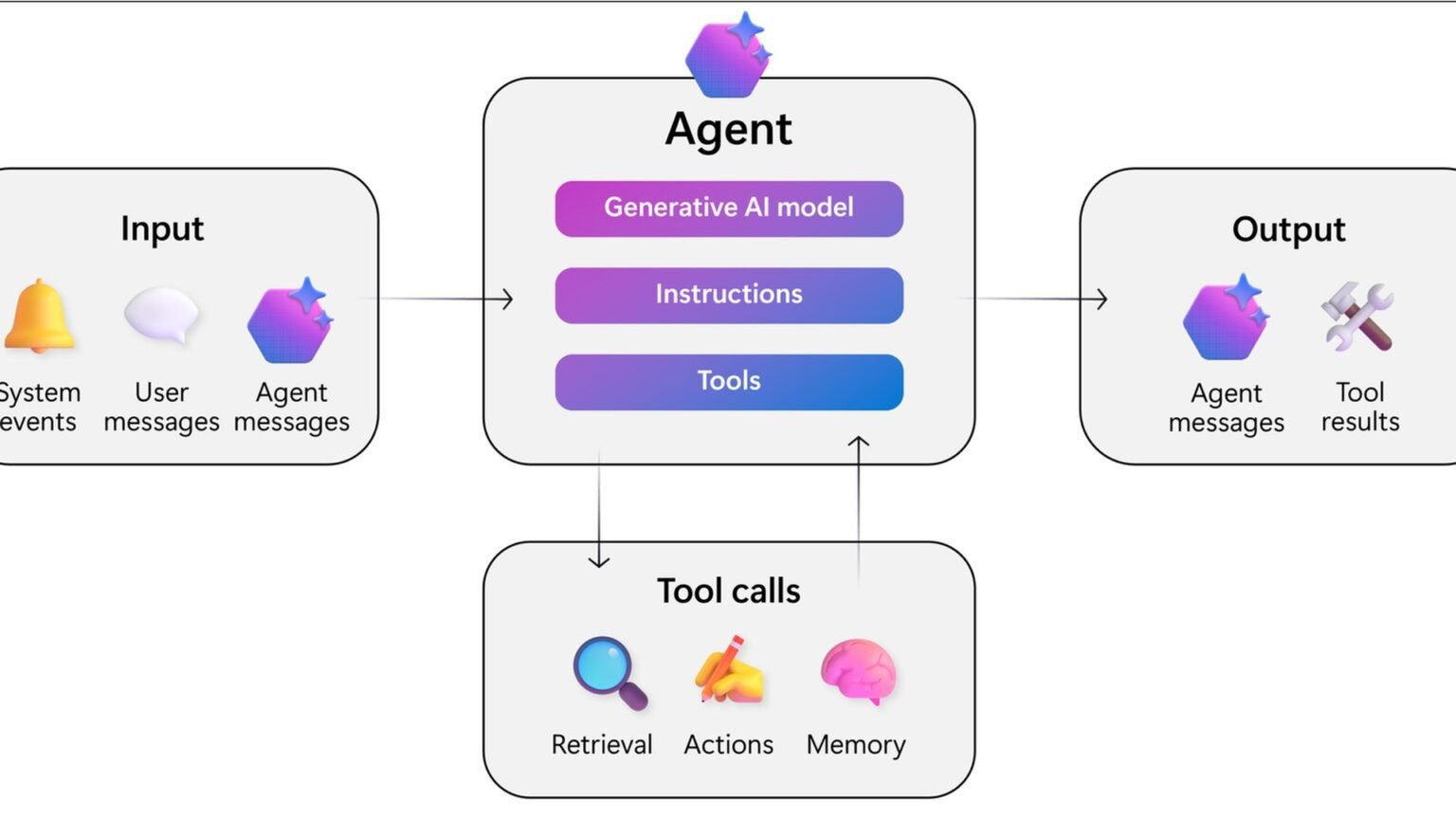
AI agent adoption is the most-asked question in engineering all-hands across the Fortune 500 right now. AI agent pilots are easy to start and hard to operationalize. The real work begins when a team asks whether an agent can deliver measurable value, stay inside policy, recover from failure, and remain replaceable if the stack changes. This Q&A covers the questions operators, platform teams, and security reviewers ask before putting agents into production, with references to real guidance from providers including OpenAI, Anthropic, LangSmith, and Microsoft Azure Architecture Center.
1) AI agent adoption — what problem should an agent solve first?
Start with a narrow workflow that already has a measurable baseline, not a vague ambition to “automate knowledge work.” Microsoft’s guidance on AI agent design patterns emphasizes matching the agent pattern to a bounded task and clear control flow rather than treating agents as general-purpose replacements for software systems. The best first candidates are repetitive, high-volume processes with structured inputs, clear success criteria, and low blast radius if the output is wrong. If you cannot define the trigger, the allowed actions, and the success metric in one page, the scope is still too loose.

2) How do we know the ROI is real and not just demo-driven?
Do not approve an agent on anecdotal productivity gains alone. Measure cycle time, completion rate, error rate, escalation rate, and cost per successful task before and after deployment, then compare that against the fully loaded cost of the workflow today. OpenAI’s agents guidance and Anthropic’s agent documentation both point teams toward tool use and structured workflows, which makes it easier to instrument outcomes instead of judging the system by vibes. If the business case depends on perfect autonomy, it is probably too fragile for production.
3) AI agent adoption fallback — what happens when the agent fails?
Every production agent needs a fallback path before it needs a launch date. Anthropic explicitly recommends building with clear stopping conditions, tool permissions, and human handoff patterns, because agents will encounter ambiguity, missing data, and tool errors. Your fallback should define when the system retries, when it asks for clarification, when it routes to a human, and when it stops without taking action. If there is no graceful degradation path, you are not deploying an agent, you are gambling with operations.
4) How do we reduce hallucinations enough for production use?
You do not eliminate hallucinations; you design around them. OpenAI and Anthropic both document techniques such as tool use, retrieval, structured outputs, and constrained action spaces so the model is not forced to invent facts or formats from scratch. In practice, the strongest pattern is to let the model reason over verified context and require citations, schema validation, or downstream checks before any consequential action is taken. If the task cannot tolerate occasional uncertainty, keep a human approval gate in the loop.
5) AI agent adoption cost — can we make it predictable enough to budget?
Only if you treat agent runs as variable-cost workflows and instrument them at the step level. Token usage, tool calls, retries, and long context windows can all turn a cheap pilot into an expensive production service, which is why observability platforms such as LangSmith and Helicone focus on tracing and cost visibility. Set hard limits on recursion depth, tool invocation counts, and context size, then monitor cost per completed task rather than cost per request. If finance cannot model the unit economics, procurement will eventually slow the rollout anyway.
6) What security and compliance controls are non-negotiable?
At minimum, teams should answer where data goes, who can access it, what gets retained, and which actions the agent is allowed to take. OpenAI publishes enterprise privacy and security information at openai.com/enterprise-privacy, while Anthropic provides security and compliance documentation at trust.anthropic.com; those documents are the starting point, not the end of the review. The agent should run with least-privilege credentials, scoped tools, auditable logs, and policy checks before sensitive actions. If the system can read everything and do everything, it is not an agent architecture problem anymore, it is an access control failure.
7) AI agent adoption and lock-in — how much are we accepting?
Some lock-in is normal, but accidental lock-in is expensive. If your prompts, tool schemas, evals, and orchestration logic are tightly coupled to one provider’s APIs or one framework’s abstractions, switching later will be painful even if the model quality changes or pricing moves against you. The practical answer is to keep business logic outside the model layer, standardize interfaces where possible, and preserve your datasets, traces, and evaluations in exportable formats. Teams that ignore optionality during the pilot usually rediscover it during renewal negotiations.
8) Which model should we choose for the agent?
Choose the model that meets the task requirements with acceptable latency, reliability, and cost, not the model with the loudest benchmark cycle. Anthropic’s documentation on agents and tools and OpenAI’s agents documentation both make clear that tool use, structured outputs, and workflow design matter as much as raw model capability in many production systems. Run side-by-side evaluations on your own tasks, including failure cases, long-tail inputs, and tool-heavy flows. If you are not testing against your own data and your own success criteria, you are outsourcing judgment to marketing.
9) Do we need an agent framework, or should we build directly on model APIs?
Use a framework when it saves real engineering time on orchestration, tracing, evaluation, or tool management, not because “agents” sounds like a category you are supposed to buy. LangChain, LlamaIndex, and similar stacks can accelerate development, while direct use of provider APIs can reduce abstraction overhead and make debugging simpler. Microsoft’s architecture guidance is useful here because it pushes teams to think in patterns and control boundaries rather than in framework branding. If your team cannot explain what the framework is doing on your behalf, you may be adding complexity faster than capability.
10) How hard will integration be with our existing systems?
Integration is usually the real project. An agent only becomes useful when it can authenticate into business systems, retrieve the right context, call approved tools, and write back results without breaking existing controls. The emerging Model Context Protocol from Anthropic is one attempt to standardize how models connect to tools and data sources, but teams still need to solve identity, permissions, rate limits, and operational ownership in each environment. If the workflow depends on brittle custom connectors, budget for maintenance from day one.
11) AI agent adoption monitoring — what does it look like in production?
Monitoring has to cover more than uptime. You need traces for each run, visibility into prompts and tool calls, task-level success metrics, latency, cost, policy violations, and human override rates; that is exactly why products such as LangSmith and Helicone emphasize observability for LLM applications. The key shift is to monitor behavior, not just infrastructure, because an agent can be technically available while operationally useless. If you cannot replay a bad run and explain why the system made a decision, you do not yet have production-grade observability.
12) How much training and onboarding will our team need?
More than most pilot plans assume, but less than a full platform migration if you keep the scope disciplined. Developers need to learn evaluation, prompt and tool design, failure analysis, and guardrail patterns; operators need to understand escalation paths, approval flows, and what the agent is not allowed to do. OpenAI’s and Anthropic’s documentation both show that successful agent systems are engineered workflows, not self-running black boxes. If users think the agent is either infallible or useless, your onboarding failed in both directions.
Frequently asked questions
Track cost per successful task alongside completion rate. That forces the team to connect model usage, tool calls, retries, and human intervention to a business outcome rather than a raw request count. For implementation guidance, see LangSmith observability docs and OpenAI’s agents guide.
No, but they do need human review for high-risk actions until the workflow is well understood and tightly controlled. Anthropic’s agents and tools documentation recommends clear permissions, stopping conditions, and handoff patterns, which is a practical way to decide where approval is mandatory and where automation is acceptable.
Keep orchestration logic, evaluations, and business rules portable, and avoid burying core workflow behavior inside provider-specific features unless the payoff is obvious. Teams should also preserve traces and test sets they can reuse across models. For architectural guidance on designing controllable agent systems, see Microsoft’s AI agent design patterns.
Primary sources
- OpenAI Agents guide — OpenAI
- Anthropic agents and tools documentation — Anthropic
- Microsoft Azure Architecture Center: AI agent design patterns — Microsoft
- LangSmith observability quickstart — LangChain
- OpenAI enterprise privacy — OpenAI
- Anthropic Trust Center — Anthropic
- Helicone — Helicone
- Model Context Protocol — Model Context Protocol
Last updated: May 20, 2026. Related: Agent Infrastructure.




