

We put the type-safe agent framework from the Pydantic team through a hands-on shakedown to see whether v1 holds up in real production Python.
What is Pydantic AI and who built it?
Pydantic AI is a type-safe Python agent framework that treats every LLM call as a typed, validated function call, built by the same team behind Pydantic, the validation library that underpins most major AI SDKs. If you have written Python in the last five years, you have almost certainly used Pydantic transitively: its v2 validation core sits inside the OpenAI SDK, the Anthropic SDK, Google’s ADK, LangChain, and LlamaIndex. Pydantic AI is that team’s answer to the question of what an agent framework looks like when validation is the foundation rather than an afterthought.
The pitch is narrow and opinionated. Instead of handing you a blank canvas of nodes and edges, Pydantic AI models an Agent as a typed object with typed dependencies, typed tools, and a typed output. Your IDE and your static type checker see the whole flow, so an entire class of “the model returned a dict that did not have the key I expected” failures moves from runtime to write-time. According to the official v1 announcement, the framework had crossed 15 million downloads before v1 even shipped.
This Pydantic AI review is a hands-on read of the framework as it stands at the end of May 2026: where it is genuinely production-ready, where it quietly punts to other tools, and whether the type-safety thesis survives contact with a real workload.
Is Pydantic AI production-ready in 2026?
Yes, Pydantic AI is production-ready: it shipped v1 on September 4, 2025 with an explicit API-stability guarantee, 100% test coverage, and a feature set built around real production failure modes rather than demos. The v1 release commits the team to not breaking your code for at least six months, and to continuing security fixes for v1 for a minimum of six months after a future v2 lands. For a category as churny as agent frameworks, a written stability policy is itself a production feature.
The v1 feature set reads like a list compiled from incident reports. Human-in-the-loop tool approval lets you flag specific tool calls to require sign-off before they execute, optionally conditioned on the call arguments or conversation history, so an autonomous agent cannot quietly run an expensive or destructive action. Durable execution, via a first-class Temporal integration (with Restate also supported), lets an agent survive API timeouts, exceptions, and process restarts and resume exactly where it left off with no manual checkpointing.
The caveat is velocity. The repository was on v1.104.0 as of May 29, 2026 — more than a hundred point releases inside the v1 line in roughly eight months. The stability guarantee covers the public API, but that cadence means you should pin versions, read the changelog before upgrading, and treat “fast-moving” as a thing to manage in CI, not a thing to trust blindly.
v1 means no breaking changes to your code for at least six months, plus six months of security fixes after a future v2. That is a stronger written commitment than most agent frameworks offer — but pin your version anyway, because the point-release cadence is aggressive.
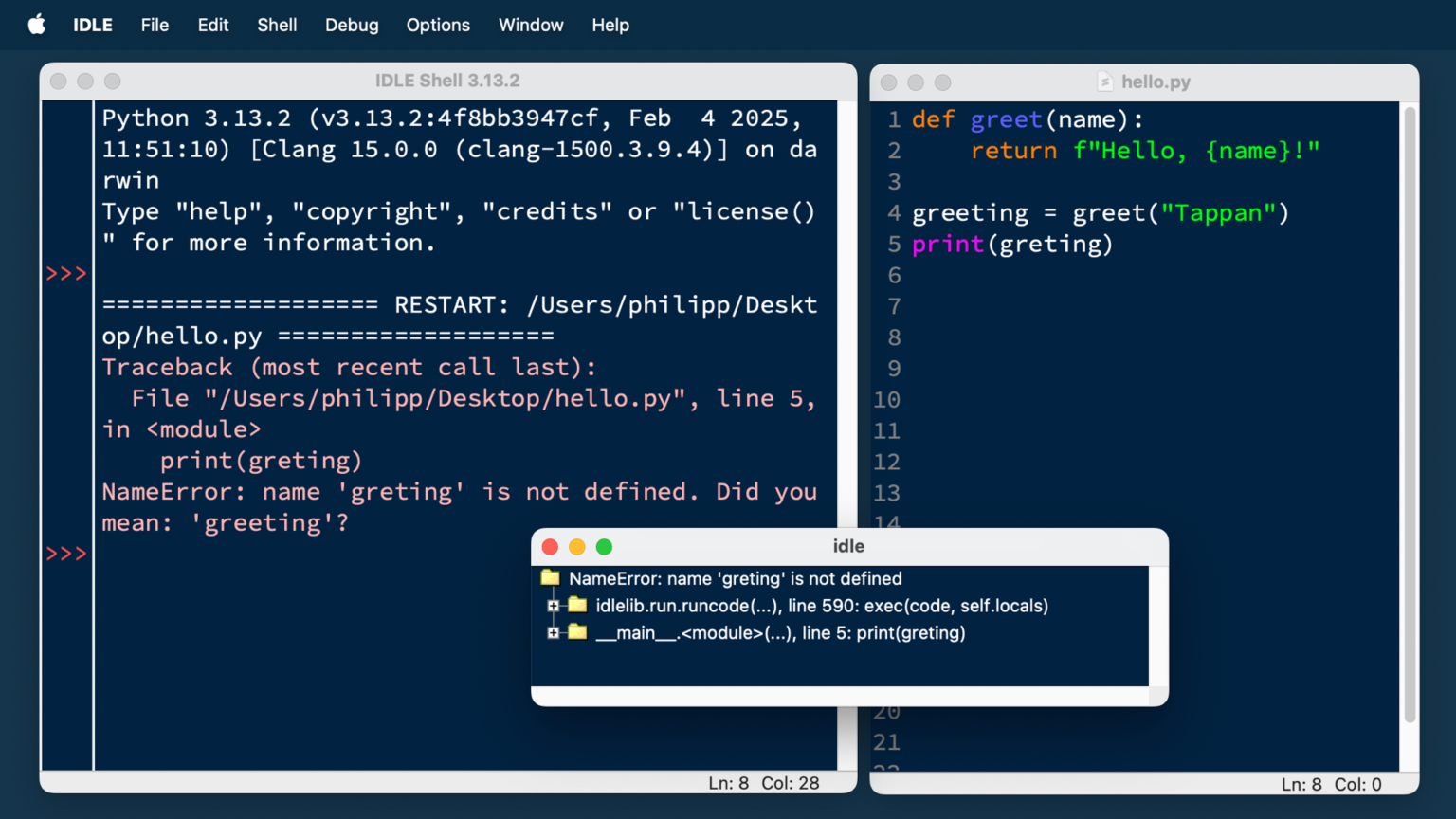
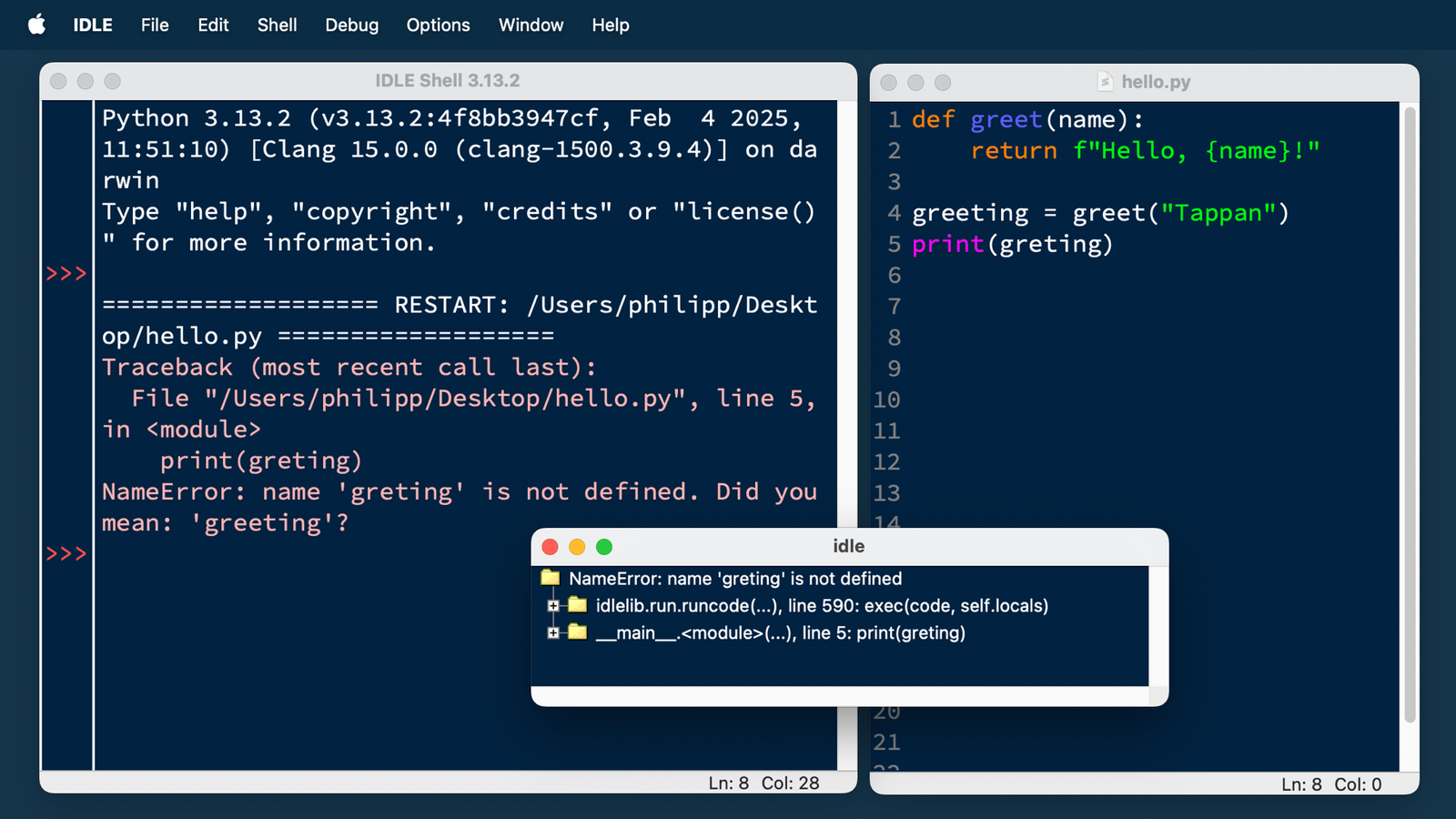
Hands-on: building a typed agent with structured outputs
The core developer experience is the strongest argument in this Pydantic AI review: you define an output schema as a Pydantic model, pass it to the Agent, and the framework validates and re-prompts until the model returns data that matches. There is no fragile string parsing and no “hope the JSON is valid” step. The agent’s output is typed end to end, so your editor autocompletes the fields and your type checker flags mistakes before you ship.
A minimal agent is genuinely a few lines. The example below mirrors the canonical pattern from the official repository, extended to show a structured output and a dependency-injected tool. Dependencies flow through RunContext, which is the detail that makes agents testable: instead of reaching for a global database handle, you pass the dependency in, and you can swap it for a fake in tests.
Observability is close to free. Adding logfire.configure() and logfire.instrument_pydantic_ai() gives you OpenTelemetry-compliant traces of the model used, tokens consumed, every tool call’s inputs and outputs, validation results, and total latency. Pydantic Logfire is a general-purpose OpenTelemetry platform, so you are not locked into a proprietary tracing format — you can point the same spans at any OTel backend.
from dataclasses import dataclass
from pydantic import BaseModel
from pydantic_ai import Agent, RunContext
import logfire
# One-time, near-free observability
logfire.configure()
logfire.instrument_pydantic_ai()
# Typed dependencies, injected via RunContext (testable!)
@dataclass
class Deps:
customer_id: int
db: object # your real DB in prod, a fake in tests
# Typed, validated output -- no string parsing
class SupportReply(BaseModel):
answer: str
needs_escalation: bool
refund_amount: float = 0.0
agent = Agent(
'anthropic:claude-sonnet-4-6',
deps_type=Deps,
output_type=SupportReply,
instructions='Be concise. Escalate anything you are unsure about.',
)
@agent.tool
async def account_balance(ctx: RunContext[Deps]) -> float:
return await ctx.deps.db.balance(ctx.deps.customer_id)
result = agent.run_sync('Can I get a refund?', deps=Deps(customer_id=42, db=db))
print(result.output.needs_escalation) # IDE knows this is a boolWhy RunContext matters for testing
Because dependencies are injected rather than imported, you can run the exact same agent against a fake database in unit tests and a real one in production. The dependency injection system is what turns “agents are hard to test” into ordinary Python testing.Streaming with live validation
Pydantic AI streams structured output continuously and validates as tokens arrive, so you get real-time access to partially-built objects without waiting for the full response — useful for progressive UIs that render fields as they firm up.Pydantic AI vs LangGraph and CrewAI: which should you pick?
Default to Pydantic AI for new production Python agents, reach for LangGraph when you need complex stateful orchestration with cycles and checkpoints, and pick CrewAI when speed of prototyping a multi-agent crew matters more than control. That three-way split is the consensus across 2026 comparison write-ups, and it holds up in practice. The frameworks are not really competing for the same job; they sit at different points on the control-versus-convenience curve.
On raw conciseness, Pydantic AI wins decisively. Independent comparisons cited in the 2026 framework decision guide and elsewhere put a typical chat-style agent at roughly 160 lines in Pydantic AI versus about 280 in LangGraph and 420 in CrewAI. LangGraph’s verbosity is the cost of its strength: it hands you a blank canvas to draw explicit state graphs, branches, loops, and human-in-the-loop interrupts, which is exactly what you want for long-running, branchy workflows and exactly what you do not want for a simple typed tool-calling loop.
Treat eye-catching cost and bug-count benchmarks with caution. Some write-ups claim a single project caught 23 bugs at write-time and cost $390 versus $1,088 for an equivalent CrewAI build — directionally plausible given the type-safety story, but these are anecdotal single-project figures, not controlled benchmarks, and your mileage will vary by workload. Popularity is also not the metric: as of early 2026 CrewAI led on raw GitHub stars (around 44k) and LangGraph sat near 25k, while Pydantic AI was the youngest of the three. Star counts measure mindshare, not production fit.
| Dimension | Pydantic AI | LangGraph | CrewAI |
|---|---|---|---|
| Best for | Type-safe production agents, multi-provider | Complex stateful orchestration, cycles, checkpoints | Fast multi-agent prototyping |
| Typical LOC (chat agent) | ~160 | ~280 | ~420 |
| Type safety | First-class (Pydantic v2 end to end) | Partial | Weaker |
| Statefulness | Shallow loops + durable execution (Temporal) | Full graph state machines | Role/goal crew abstraction |
| Observability | Logfire (OpenTelemetry) | LangSmith | Limited / platform-tilted |
| Maturity signal | v1 with stability policy (Sept 2025) | Mature, widely deployed | Large ecosystem, vendor-lock-in risk |
Scorecard, pros and cons
Pydantic AI earns a strong production-ready score for the right workload: stateless-to-shallow agent loops where typed inputs, validated outputs, and clean observability matter more than arbitrary graph topology. The scorecard below reflects a framework that is excellent at its chosen scope and honest about handing off when you exceed it. The single biggest reason to hesitate is not a weakness in the code — it is the release velocity, which demands disciplined version pinning.
Where it shines: developer experience, testability through dependency injection, model-agnostic provider support (OpenAI, Anthropic, Gemini, DeepSeek, Grok, Mistral, Bedrock, Vertex, and more), and observability that costs one line. Where it asks more of you: deep multi-agent state machines, and the discipline to track a fast-moving changelog.
Pydantic AI v1 (as of May 2026)
Best for: Type-safe production agents, structured outputs, multi-provider Python services
What works
Watch out for
Verdict: should you adopt Pydantic AI?
Production-ready for its scope, with version discipline
Adopt Pydantic AI as your default for new production Python agents in 2026, and keep LangGraph in your toolbox for genuinely stateful, branchy orchestration. The type-safety thesis is not marketing — moving output-shape and tool-contract bugs to write-time is a real reduction in production risk, and the Logfire integration closes the observability gap that usually gets bolted on too late. For the common case of “call a model, run some typed tools, return a validated object,” it is the cleanest framework available.
The honest limitation is scope, not quality. If your system needs explicit state machines with cycles, checkpoints, and complex human-in-the-loop branching across many agents, LangGraph’s verbosity buys you control that Pydantic AI deliberately does not expose. And because the framework iterates fast, the one piece of operational discipline you cannot skip is pinning your version and reading the changelog before every upgrade.
Builder’s take
I build Cyntr, an agent orchestration runtime, and I run Loomfeed on top of a lot of LLM glue code. The framework decision that has cost me the most over two years was not which model to call, it was how much untyped string-shuffling lived between my code and the model. Pydantic AI is the first framework that treated that gap as the actual product.
- Type-safety is not a vanity feature. The bugs Pydantic AI moves from runtime to write-time are exactly the ones that page you at 2am: a tool returning the wrong shape, an output field the downstream code assumed existed. I would rather lose those at the type checker.
- Default to it for stateless or shallow agent loops, but do not fight it for deep stateful orchestration. When I needed cyclic multi-agent state with checkpoints, LangGraph was the right tool. Pydantic AI plus Temporal covers durability, not arbitrary graph topology.
- The Logfire integration is the real lock-in, in a good way. One line of instrumentation gave me token, latency, and validation traces I previously hand-rolled. Budget for the fact that observability you do not pay for in money you pay for in incident time.
- Pin your version and read the changelog. v1 promises API stability, but the release cadence is aggressive (over 100 point releases by mid-2026). Fast-moving is a feature until an upgrade surprises you in CI.
Frequently asked questions
Yes. Pydantic AI shipped v1 on September 4, 2025 with a written API-stability guarantee, 100% test coverage, human-in-the-loop tool approval, and durable execution via Temporal. By late May 2026 it had reached v1.104.0, so it is production-ready — just pin your version given the fast release cadence.
It models each agent as a typed object: typed dependencies via RunContext, typed tools, and a typed output schema defined as a Pydantic model. Your IDE and static type checker see the whole flow, so output-shape and tool-contract errors surface at write-time instead of runtime, and outputs are validated (and re-prompted) against your schema automatically.
Pydantic AI is more concise (roughly 160 lines versus about 280 for an equivalent LangGraph agent) and stronger on type safety, making it the better default for typed tool-calling loops. LangGraph is the better choice when you need explicit state machines with cycles, checkpoints, and complex multi-agent human-in-the-loop branching.
Yes, through Pydantic Logfire, a general-purpose OpenTelemetry platform from the same team. Adding logfire.configure() and logfire.instrument_pydantic_ai() gives you traces of the model used, tokens consumed, every tool call’s inputs and outputs, validation results, and latency. Because it is OpenTelemetry-compliant, you can route the spans to other OTel backends too.
It is model-agnostic and supports virtually every major provider, including OpenAI, Anthropic, Gemini, DeepSeek, Grok, Cohere, Mistral, Perplexity, Azure AI Foundry, Amazon Bedrock, Google Vertex AI, Ollama, LiteLLM, Groq, OpenRouter, Together AI, and Fireworks, with a path to implement custom models.
It is built by the Pydantic team, whose v2 validation library is a dependency inside the OpenAI SDK, the Anthropic SDK, Google ADK, LangChain, and LlamaIndex. That deep ecosystem presence, the 15 million-plus downloads before v1, and the explicit stability policy are reasonable trust signals — though as with any fast-moving framework you should still pin versions and test upgrades.
Primary sources
- Pydantic AI v1: A Predictable and Robust GenAI Framework — Pydantic
- pydantic/pydantic-ai (GitHub repository) — GitHub
- The 2026 AI Agent Framework Decision Guide: LangGraph vs CrewAI vs Pydantic AI — DEV Community
- Build durable AI agents with Pydantic AI and Temporal — Temporal
- Pydantic Logfire: AI Observability for LLMs, Apps and RAG — Pydantic
- Choosing an agent framework: LangChain vs LangGraph vs CrewAI vs PydanticAI — Speakeasy
Last updated: May 31, 2026. Related: Agent Infrastructure.




