

GAIA, tau2-bench, WebArena and BFCL V4 each crown a different winner in 2026 – here is why no single model tops the board, and what the matrix actually tells buyers.
Which model wins the agentic AI benchmarks in 2026?
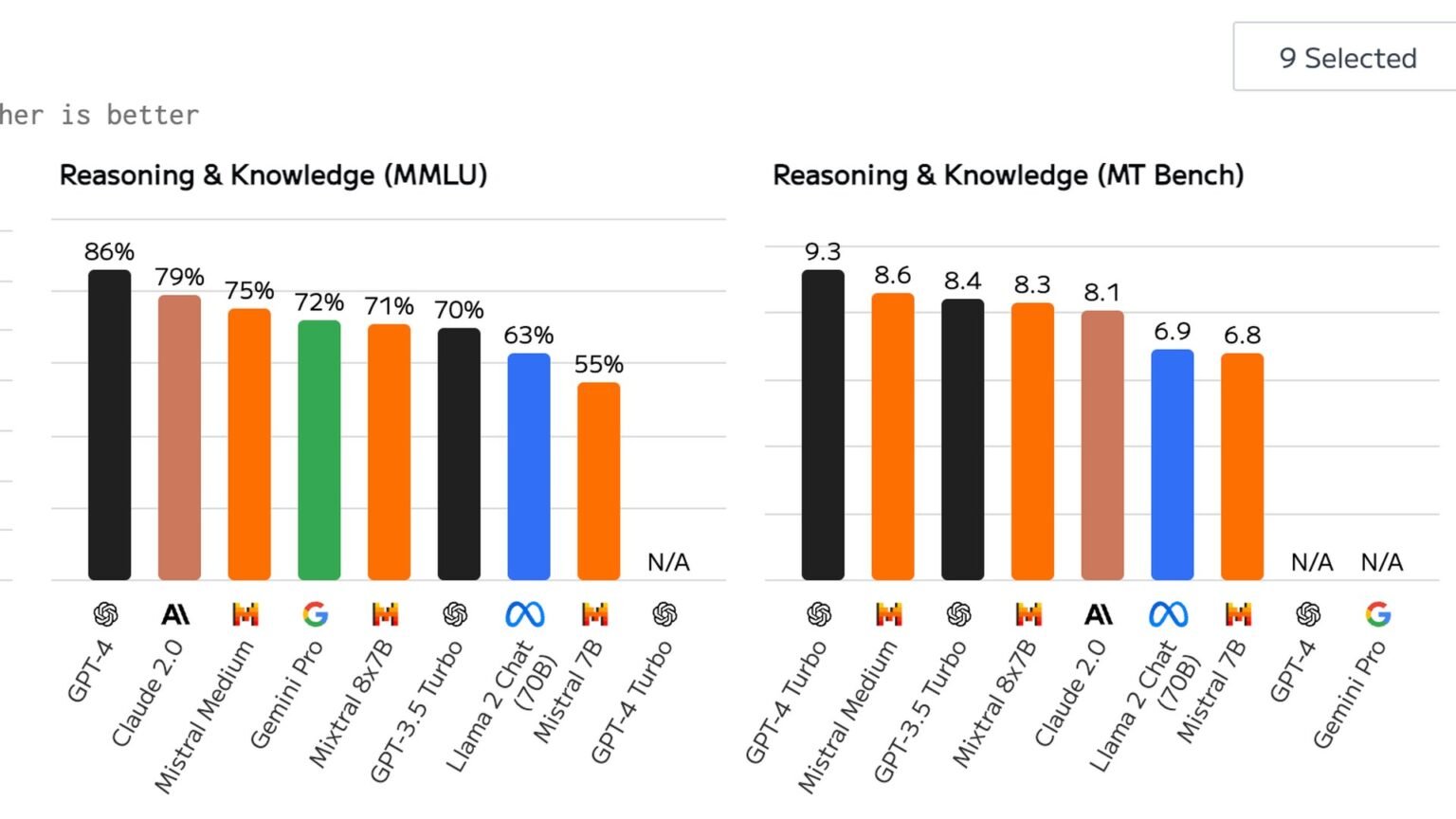
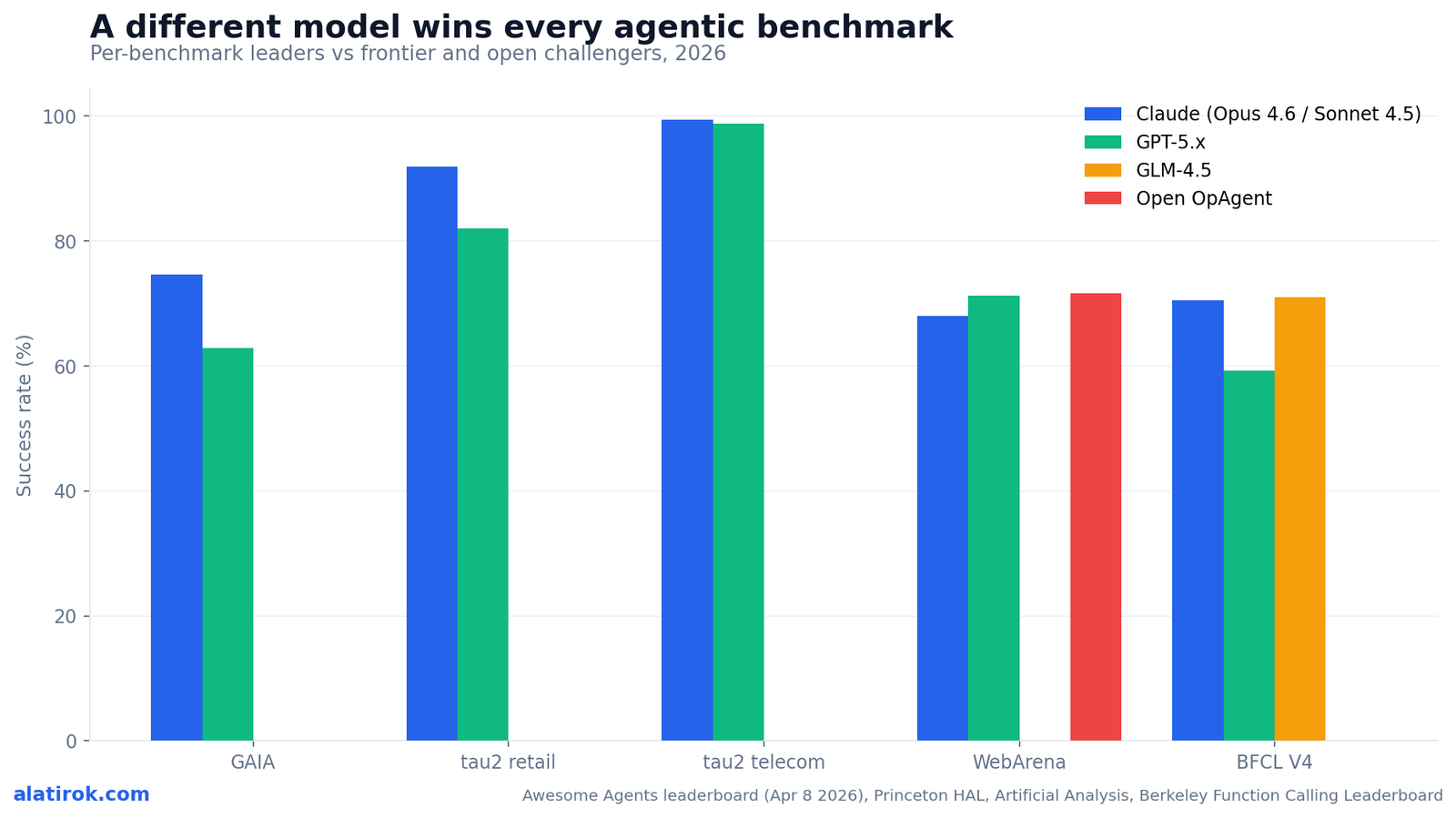
No single model wins the agentic AI benchmarks in 2026 – a different model tops nearly every board. Claude Opus 4.6 leads tau2-bench customer service, Claude Sonnet 4.5 leads GAIA, the open OpAgent leads WebArena, and Zhipu’s GLM-4.5 leads BFCL V4 function calling. Four headline benchmarks, four different winners, and not one of them is the obvious frontier flagship across the board.
This is the most important thing a buyer can internalize this year. The reflex to ask ‘what is the best agent model?’ assumes the leaderboards collapse into one ranking. They do not. Each benchmark stresses a genuinely different capability – long-horizon web-and-file reasoning, multi-turn dual-control dialogue, live website navigation, and structured tool-call accuracy – and the model that is strongest at one is frequently middling at another.
The data below is drawn from the Awesome Agents agentic benchmarks board (updated April 8, 2026), Princeton’s HAL GAIA leaderboard, Artificial Analysis, and the Berkeley Function Calling Leaderboard. Every number in this article is sourced; the chart in the next section is the single visual that makes the split obvious at a glance.
The 2026 agentic AI benchmarks scoreboard, one matrix
Read the matrix row by row and the highlighted winner jumps to a different column on almost every line. That visual shift is the entire thesis of this article: the agentic AI benchmarks do not rank models, they rank models-on-a-task. Claude dominates the two customer-service rows and GAIA, but loses live web navigation to an open Qwen3-VL agent and loses raw function calling to GLM-4.5.
tau2-bench, built by Sierra Research, runs multi-turn customer-service episodes in a dual-control environment where both the agent and a simulated user hold tools. Claude Opus 4.6 posts 99.3% on the telecom domain and 91.9% on retail. GPT-5.2 Thinking is right behind on telecom at 98.7% but falls to 82.0% on retail – a nearly 10-point retail gap that no telecom score would have warned you about. The open-source LongCat-Flash-Thinking-2601 ties the telecom leader at 0.993.
GAIA – Princeton’s 466 web-and-file reasoning tasks – is led by Claude Sonnet 4.5 at 74.6% on the HAL scaffold, against a GPT-5 Medium configuration at 62.8%. WebArena’s live-website tasks are won by OpAgent (Qwen3-VL-32B plus reinforcement learning) at 71.6%, edging a GPT-5 agent at 71.2% and a Claude-Code-based agent at 68.0%. BFCL V4 puts GLM-4.5 first at 70.9%, Claude Opus 4.1 at 70.4%, and a GPT-5 entry well back at 59.2%.
Notice that GPT-5 variants are competitive everywhere and first nowhere on this particular board. That is not a knock on the model – it is a demonstration that ‘competitive everywhere’ and ‘benchmark winner’ are different properties, and that picking a model off a single bolded cell is how teams end up surprised in production.
Each benchmark uses its own evaluation harness and scaffold. A score is only comparable within its own column – never read across rows to declare an overall winner.
tau2-bench: why retail and telecom must be split
99.3%
tau2-bench telecom leader
Claude Opus 4.6; LongCat-Flash ties at 0.993
91.9%
tau2-bench retail leader
Claude Opus 4.6, the most discriminating split
9.9 pts
GPT-5.2 telecom-to-retail drop
98.7% telecom vs 82.0% retail
Treat tau2-bench retail and telecom as two separate benchmarks, because the same model can be near-perfect on one and mediocre on the other. Sierra Research’s tau2-bench models customer service as a decentralized partially-observable process where the agent and a simulated user each operate tools, so an agent has to both reason and coordinate a human counterpart through a fix.
The telecom domain is close to saturated at the top: Claude Opus 4.6 at 99.3%, Claude Opus 4.5 at 98.2%, GPT-5.2 Thinking at 98.7%, and LongCat-Flash-Thinking-2601 tying the leader at 0.993. When four models cluster inside a single point, telecom has stopped discriminating between them and you should weight other evidence.
Retail tells a different story and is where the real separation lives. Claude Opus 4.6 leads at 91.9%, Claude Opus 4.5 follows at 88.9%, and GPT-5.2 Thinking drops to 82.0%. The retail tasks involve more branching policy logic and order-state manipulation, and that is exactly where a model that aced telecom can stumble. If your deployment is a retail or e-commerce support agent, the telecom leaderboard is actively misleading – benchmark the retail split.
“When four models cluster inside a single point on telecom, the benchmark has stopped telling you which one to ship.”
On benchmark saturation
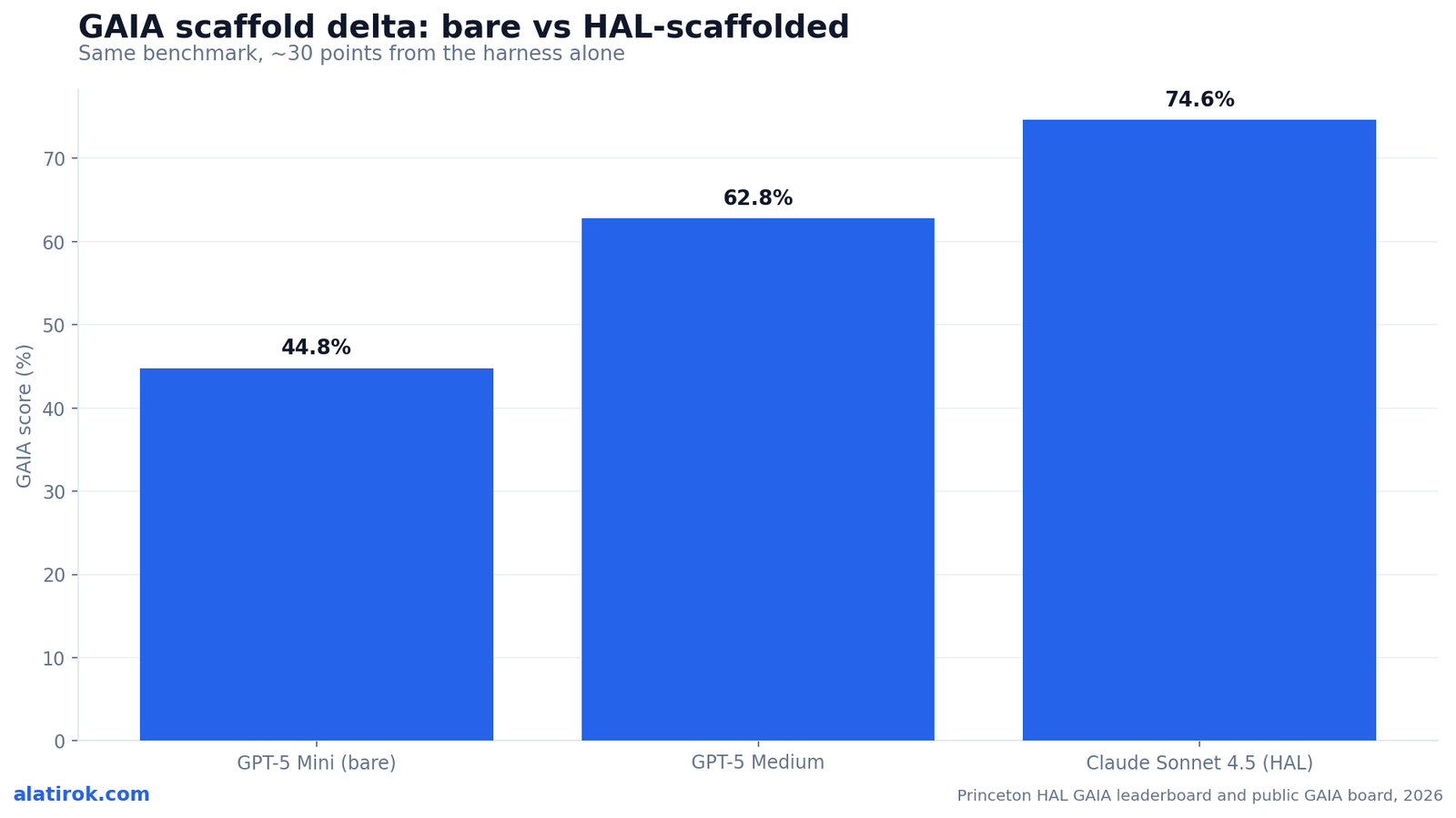
GAIA and the scaffold delta: the harness is half the score
On GAIA, the agent scaffold adds roughly 30 absolute points – meaning your orchestration layer can matter as much as your model choice. The same underlying GPT-5 family scores 44.8% bare as GPT-5 Mini on the public GAIA board, while a HAL-scaffolded run reaches 74.6% with Claude Sonnet 4.5. That is a +29.8-point swing attributable to the harness around the model, not the model alone.
Princeton’s HAL is a generalist agent scaffold built specifically to push GAIA’s 466 web-and-file reasoning tasks. It supplies planning, tool routing, retries, and reflection on top of the base model. The lesson for builders is uncomfortable but liberating: a worse model inside a better scaffold can beat a better model running bare. Kili Technology’s 2026 benchmark review found the same effect elsewhere, noting one Claude Opus configuration scoring 64.9% in one framework and 57.6% in another – a 7-point gap from the orchestration layer alone.
This is why GAIA scores carry a methodology asterisk that buyers ignore at their peril. A vendor citing ‘74.6% on GAIA’ is citing a model-plus-scaffold result. If you drop their model into your own thinner harness, you should expect to land far closer to the bare number. Always ask what scaffold produced a quoted agent score.
Any quoted agent benchmark score is a model-plus-scaffold number. Drop the same model into a thinner harness and expect to regress toward the bare baseline.
WebArena and BFCL V4: where open weights take the crown
Two of the four headline agentic AI benchmarks are led by open-weight systems, not closed frontier flagships. On WebArena’s live-website navigation tasks, OpAgent – built on Qwen3-VL-32B with a reinforcement-learning phase on real sites – leads at 71.6%, edging a GPT-5 agent (ColorBrowserAgent) at 71.2% and a Claude-Code-based agent at 68.0%. OpAgent’s published pipeline uses a Planner-Grounder-Reflector-Summarizer loop, again underscoring that the agent architecture, not just the model, is doing the work.
On the Berkeley Function Calling Leaderboard V4 – the standard for structured tool-call accuracy – GLM-4.5 from Zhipu AI leads at 70.9%, with Claude Opus 4.1 at 70.4% and Claude Sonnet 4 at 70.3% close behind, and a GPT-5 entry back at 59.2%. (Note that BFCL has since logged newer entries like Claude Opus 4.5 and GLM-4.6 at higher overall marks; the 70.9% figure is the V4 snapshot from the Awesome Agents board.)
For anyone weighing build-versus-buy on a self-hosted stack, this is the headline. The two axes most central to production agents – reliably driving a browser and reliably emitting valid tool calls – are currently led by models you can run yourself under permissive licenses. That reframes the cost conversation entirely, because the per-token economics of an open model winning your specific benchmark can dwarf a one-point closed-model edge elsewhere.
| Benchmark | What it measures | Leader | Runner-up | Notable GPT-5 |
|---|---|---|---|---|
| GAIA | Web + file reasoning (466 tasks) | Claude Sonnet 4.5 – 74.6% | Claude Sonnet 4.5 High – 70.9% | GPT-5 Medium – 62.8% |
| tau2 retail | Multi-turn support, retail | Claude Opus 4.6 – 91.9% | Claude Opus 4.5 – 88.9% | GPT-5.2 Thinking – 82.0% |
| tau2 telecom | Multi-turn support, telecom | Claude Opus 4.6 – 99.3% | GPT-5.2 Thinking – 98.7% | GPT-5.2 Thinking – 98.7% |
| WebArena | Live website navigation | OpAgent (Qwen3-VL) – 71.6% | ColorBrowserAgent (GPT-5) – 71.2% | ColorBrowserAgent – 71.2% |
| BFCL V4 | Function / tool-call accuracy | GLM-4.5 – 70.9% | Claude Opus 4.1 – 70.4% | GPT-5 – 59.2% |
Why the agentic AI benchmarks should never be one ranking
The agentic AI benchmarks measure different capabilities and should never be collapsed into a single ranking, because doing so averages away the exact signal you need. GAIA tests long-horizon reasoning over documents and the web. tau2-bench tests multi-turn coordination with a tool-wielding human. WebArena tests live DOM navigation. BFCL V4 tests structured tool-call correctness. A weighted average of those four is a number with no operational meaning.
The benchmarks also disagree on the failure modes they expose. tau2-bench specifically shows that agent behavior degrades sharply moving from single-control to dual-control settings – social coordination is its own capability axis that GAIA and BFCL barely touch. And the scaffold dependence is everywhere: the same model swings 7 points across frameworks on one task and nearly 30 points bare-versus-scaffolded on GAIA.
Then there is the production gap. Kili Technology’s review cites a 37% gap between lab benchmark scores and real-world deployment, with one example of consistency dropping from 60% on a single run to 25% across eight consecutive runs. A headline 99.3% can coexist with a reliability problem you only see when you measure N-run consistency – which no public board currently reports as the primary metric. The right reading of this board is not ‘who won’ but ‘which benchmark matches my workload, and what did the bare-model baseline look like.’
Pros
Cons
Match the benchmark to your workload, read the bare-model baseline, then re-run your own eval. The leaderboard narrows the field; it does not make the decision.
How to actually choose a model from this board
Four benchmarks, four winners – the board is a map, not a ranking
Choose the benchmark that mirrors your workload first, then read that column – never the other way around. If you are building a retail support agent, tau2-bench retail is your row and Claude Opus 4.6 is your front-runner; the telecom score is noise for you. If you are building an autonomous web operator, WebArena is your row and an open Qwen3-VL agent deserves a serious look before you default to a closed API.
Second, find the bare-model baseline before you believe any quoted agent score. The GAIA gap between 44.8% bare and 74.6% scaffolded is the clearest warning on this entire board: the number a vendor shows you includes their harness. Estimate what you will actually get inside your own orchestration layer, which is usually thinner than a research scaffold like HAL.
Third, budget for your own evaluation harness as a product line item, not an afterthought. Across Cyntr and Loomfeed the harness has bought more reliable agent behavior than any single model swap this year, which is exactly what the GAIA scaffold delta predicts. Public benchmarks tell you who is in contention. Your own N-run eval on your own data tells you who to ship – and on this board, that will be a different model for a different job.
Builder’s take
I run evaluation harnesses for Cyntr’s orchestration engine and Loomfeed’s AI layer every week, and the single most expensive mistake I see teams make is shopping for ‘the best agent model’ off one number. There is no such number in 2026.
- Pick the benchmark that matches your workload before you pick the model. A retail-support agent should be tuned against tau2-bench retail, not a coding leaderboard – the leaders are different models.
- The scaffold is a first-class product decision. GAIA’s +29.8-point jump from bare GPT-5 Mini to a HAL-scaffolded run means your orchestration layer can out-weigh your model choice. Cyntr’s gains this year came mostly from the harness, not from swapping models.
- Open weights are now genuinely competitive on the agentic axes that matter to me. OpAgent leads WebArena and GLM-4.5 leads BFCL V4, which changes the build-vs-buy math for any self-hosted deployment.
- Re-run your own evals on every model release. These boards saturate in months and a 99.3% telecom score can hide a sub-N-run reliability problem you only catch in production.
Frequently asked questions
There is no single best model. As of the April 2026 boards, Claude Opus 4.6 leads tau2-bench customer service (99.3% telecom, 91.9% retail), Claude Sonnet 4.5 leads GAIA at 74.6%, the open OpAgent leads WebArena at 71.6%, and GLM-4.5 leads BFCL V4 function calling at 70.9%. Each benchmark crowns a different winner because each measures a different capability.
Because they measure fundamentally different things – GAIA tests web-and-file reasoning, tau2-bench tests multi-turn coordination with a tool-wielding user, WebArena tests live website navigation, and BFCL V4 tests structured tool-call accuracy. Averaging them produces a number with no operational meaning, and it hides the workload-specific strengths you actually need to see when choosing a model.
The scaffold delta is the score difference between a bare model and the same model inside an agent scaffold. On GAIA, a bare GPT-5 Mini scores 44.8% while a HAL-scaffolded Claude Sonnet 4.5 run reaches 74.6% – a +29.8-point swing from the harness alone. It matters because any quoted agent benchmark is a model-plus-scaffold result that rarely transfers to a thinner in-house harness.
Both are Sierra Research customer-service domains, but telecom is near-saturated at the top (four models within one point of 99.3%) while retail is far more discriminating. Claude Opus 4.6 leads retail at 91.9%, but GPT-5.2 Thinking drops from 98.7% on telecom to 82.0% on retail. If you build a retail support agent, the telecom score will mislead you – benchmark the retail split.
Yes, two of the four headline boards are led by open systems. OpAgent, built on Qwen3-VL-32B with reinforcement learning, leads WebArena at 71.6%, and GLM-4.5 from Zhipu AI leads BFCL V4 at 70.9%. Because those two axes – browser navigation and tool-call accuracy – are central to production agents, open weights meaningfully change self-hosted build-versus-buy economics.
Not on its own. Public boards report single-run success rates, but Kili Technology documents a 37% gap between lab scores and real-world deployment, with one case where consistency fell from 60% on a single run to 25% across eight runs. A high headline number can coexist with an N-run reliability problem you only catch by re-running your own evaluation on your own data.
Primary sources
- Agentic AI Benchmarks Leaderboard – GAIA, WebArena, BFCL, tau2-bench — Awesome Agents
- HAL: GAIA Leaderboard — Princeton HAL
- Berkeley Function Calling Leaderboard (BFCL) V4 — UC Berkeley
- tau2-bench Telecom Benchmark Leaderboard — Artificial Analysis
- OpAgent: Operator Agent for Web Navigation — arXiv
- AI Benchmarks 2026: Top Evaluations and Their Limits — Kili Technology
Last updated: June 1, 2026. Related: Observability.




