

We fused measured tokens per SWE-bench task, each model’s 2026 price, and pass rate to rank coding agents by the only number that matters: dollars per successful fix.
What is coding agent cost per task in 2026?
1-3.5M
Tokens per agentic SWE-bench task
Including retries; ~1000x a code-chat turn (Stanford)
~153:1
Input-to-output token ratio
Input tokens, not output, drive agentic cost
30x
Run-to-run token variance
Same task, same agent, wildly different spend
5.5x
Claude Code vs Cursor token use
33K vs 188K tokens on an identical task
Coding agent cost per task is the dollar amount you spend to get one completed software fix, calculated as (tokens consumed per task x the model’s price) divided by the task’s pass rate — not the model’s sticker price or its raw benchmark score. A model that costs $1 per million tokens but fails half its work is more expensive per shipped fix than a model at $5 per million that lands the task on the first try. The coding agent cost per task that actually hits your invoice is dollars per successful fix.
This is the number every existing resource refuses to compute. Leaderboards like Artificial Analysis publish a cost-per-task column, but it is pure pay-per-token API spend on a composite benchmark — it ignores subscription agents like Devin entirely and never divides by the pass rate. Pricing roundups list subscription tiers ($20/mo here, $200/mo there) but never normalize them to a per-completed-task figure. Neither side fuses the three variables that determine your real unit economics.
Those three variables are: (1) how many tokens an agentic SWE-bench-style task actually burns, including retries; (2) what those tokens cost at each model’s 2026 price; and (3) the pass-rate-per-dollar that exposes when a cheaper model quietly beats a flagship. Fuse them and the ranking inverts what the marketing pages imply. That fusion is the entire point of this article.
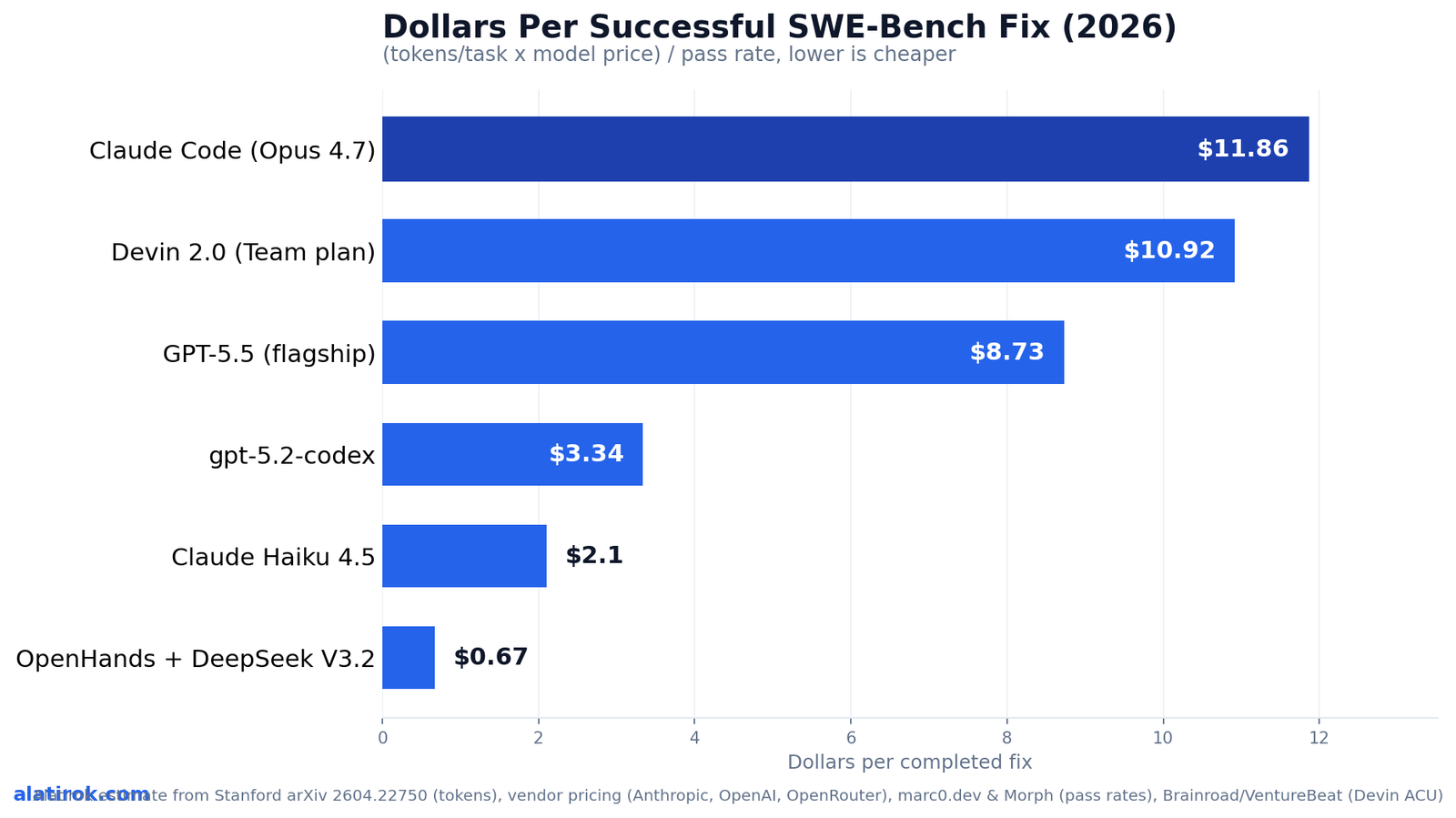
How much does each coding agent cost per task? The ranking
On dollars per successful fix, an open-weight OpenHands stack on DeepSeek V3.2 lands near $0.67, Claude Haiku 4.5 around $2.10, gpt-5.2-codex near $3.34, GPT-5.5 about $8.73, Devin 2.0 roughly $10.92, and Claude Code (Opus 4.7) about $11.86 — so the cheapest agents per shipped fix are the small and open-weight ones, not the flagships. That is the headline the leaderboards bury: pass-rate-per-dollar, not raw accuracy, decides who is cheap.
These figures are illustrative unit-economics estimates, built transparently from cited inputs: a representative 1.5M-token agentic task at the Stanford-measured ~153:1 input:output split, each model’s published 2026 API price, and each agent’s reported pass rate, with a documented token-efficiency adjustment for Claude Code‘s leaner trajectories and Devin’s flat-subscription normalization. They are not vendor-blessed numbers — they are the math the vendors decline to show you. Plug your own measured token counts in and the relative ordering holds.
The chart below is the one no incumbent publishes: agents ranked purely by what it costs to get one task done. Read it as a budgeting tool, not a quality verdict — flagships still win the hardest, most ambiguous tickets, which is exactly why their higher per-fix cost can still be worth it.
Why tokens per task make coding agent cost per task so hard to predict
An agentic coding task consumes 1-3.5 million tokens including retries — roughly 1000x a single code-chat turn — and the same task run twice can differ by up to 30x in total tokens, which is why coding agent cost per task is genuinely hard to budget. Stanford’s Digital Economy Lab and Microsoft Research documented this in ‘How Do AI Agents Spend Your Money?’, analyzing trajectories from eight frontier models on SWE-bench Verified.
Two findings reshape how you should think about spend. First, input tokens — not output — drive cost, at roughly a 153:1 ratio. Every tool call re-feeds the file context, the diff, the test output, and the running plan back into the model, so the bill is dominated by re-reading state, not by writing code. That is why prompt caching and lean context management move the needle far more than asking for shorter answers.
Second, accuracy does not climb monotonically with spend. The study found accuracy often peaks at intermediate cost and then saturates — throwing more tokens at a task past a point buys you nothing but a bigger invoice. A capped, disciplined agent frequently lands the same fix as an uncapped one for a fraction of the tokens, which is the entire economic argument for retry ceilings.
Because the same task can swing 30x in token spend run-to-run, a single ‘mean cost per task’ from any leaderboard is a fiction for budgeting. Plan against your p90, not your average, and set hard per-task token ceilings or one stuck agent will quietly burn a day of margin.
Codex vs Claude Code cost: which is cheaper per completed fix?
On raw token billing, gpt-5.2-codex is dramatically cheaper per completed fix than Claude Code (~$3.34 vs ~$11.86 in our model) because Codex is priced at $1.75/$14 per million tokens versus Opus 4.7’s $15/$75 — but Claude Code closes much of the gap through token efficiency, using as few as 33K tokens where rival agents burn 188K on the identical task. So ‘codex vs claude code cost’ has two honest answers depending on whether you weight price or trajectory discipline.
Codex wins the codex vs claude code cost question on pure per-fix dollars: cheaper per-token pricing and a respectable ~77-80% pass rate combine to a low cost per completed task. It is the value play for high-throughput, well-scoped work where you do not need the absolute top pass rate. The catch is that Codex’s lower pass rate means more tasks bounce back for a second attempt, and each retry re-incurs the full input-token cost.
Claude Code’s pitch is that its leaner trajectories and higher ~87.6% pass rate reduce rework, which on complex, multi-file changes can flip the economics. One benchmark clocked Claude Code at 33K tokens versus Cursor’s 188K on the same task — a 5.5x efficiency edge that no price page surfaces. If your work is gnarly enough that a failed task costs you an engineer’s afternoon, paying more per token for a higher first-pass success rate is often the cheaper path overall.
| Metric | gpt-5.2-codex | Claude Code (Opus 4.7) |
|---|---|---|
| API price (in / out per 1M) | $1.75 / $14 | $15 / $75 |
| Reported SWE-bench pass rate | ~77-80% | ~87.6% |
| Token efficiency on identical task | Baseline | ~33K vs 188K (5.5x leaner) |
| Est. $ per successful fix | ~$3.34 | ~$11.86 |
| Subscription entry point | $20/mo ChatGPT Plus | $20/mo Pro, $100-200/mo Max |
| Best for | High-volume, well-scoped tasks | Complex multi-file changes |
Devin cost per task: why a flat $500/mo can cost more per fix
Devin’s cost per task normalizes to roughly $4-6 for a well-scoped bug fix on the $500/mo Team plan (250 ACUs at ~$2 each, ~2.5 ACUs per fix), but because Devin’s unassisted SWE-bench pass rate sits near 45.8%, its dollars-per-successful-fix climbs to about $10.92 — on par with a flagship. The flat subscription hides this: you pay the same whether the task lands or not, so failed attempts silently inflate your real Devin cost per task.
Cognition restructured pricing with Devin 2.0, dropping the entry point from $500/mo to $20/mo and moving to Agent Compute Unit (ACU) billing, where one ACU is roughly 15 minutes of autonomous work. A clean bug fix runs 2-3 ACUs; a migration with back-and-forth clarifications can hit 30 ACUs, which at $2 each is $60+ for a single task. Devin also does not pre-quote the ACU cost — it runs, then it bills — so budgeting requires tracking actual consumption before you commit.
The structural lesson is that subscription agents are 5-10x more expensive per task than token-billed rivals once you normalize for pass rate, precisely because you cannot route a failed task to a cheaper retry — the meter is the plan. For teams that value the hands-off, end-to-end autonomy and Slack-native workflow, that premium can be worth it. For pure unit economics, it rarely is.
“A flat subscription doesn’t make failed tasks free — it makes them invisible. Devin’s real cost per fix only shows up once you divide by its pass rate.”
Alatirok unit-economics analysis, 2026
When does a cheaper model win on pass-rate per dollar?
A cheaper model wins on pass-rate per dollar whenever its pass rate stays close enough to a flagship’s that the price gap outruns the accuracy gap — and in 2026 that happens constantly, because Claude Haiku 4.5 hits 73.3% on SWE-bench Verified at $1/$5 per million tokens while flagships cost 5-15x more for a roughly 15-point accuracy bump. On dollars per successful fix, Haiku lands near $2.10 versus GPT-5.5’s ~$8.73. That is the cheap-model-wins effect, and it is the single most important fact in this whole comparison.
Anthropic’s framing for Haiku 4.5 is blunt: what was at the frontier five months ago is now one-third the cost and twice the speed. For the large majority of real tickets — dependency bumps, well-scoped bug fixes, test scaffolding, boilerplate — a 73% first-pass model with a cheap retry is dramatically better economics than a flagship. You only reach for the flagship on the long tail of genuinely hard, ambiguous tasks where the pass-rate gap finally justifies the spend.
Open-weight stacks push this further. An OpenHands or Aider agent on DeepSeek V3.2 ($0.28/$0.42 per million tokens) lands comparable tasks at roughly 5% of Devin’s per-task cost, putting cost per successful fix under a dollar in our model. The trade-off is operational overhead — you self-host, you manage retries, you babysit the harness — but for high-volume, low-stakes work the per-fix economics are unbeatable.
Pros
Cons
How to calculate your own coding agent cost per task
Stop buying benchmark scores. Buy dollars per shipped fix.
To calculate your real coding agent cost per task, measure actual tokens per task from your own runs (not a leaderboard average), multiply by your model’s input and output prices at the ~153:1 split, then divide by your observed pass rate to get dollars per successful fix. The formula is simple; the discipline is in using your measured numbers, because the 30x variance means a borrowed average will mislead you.
Concretely: instrument your agent to log input and output tokens per task, run a representative sample of 30-50 real tickets, and record how many landed without human rework. Cost per successful fix = (mean input tokens x input price + mean output tokens x output price) / pass rate. Do this per task type — easy bug fixes and hard migrations have completely different profiles, and a single blended number will hide the routing opportunity.
Then act on it. Route task types to the cheapest agent that clears your quality bar, cap retries so a stuck task cannot run away, and lean hard on prompt caching, since input tokens dominate the bill. The teams winning on agent economics in 2026 are not the ones buying the highest benchmark score — they are the ones who measured their own dollars-per-fix and tiered their fleet accordingly.
Worked example: Haiku 4.5 vs GPT-5.5 on an easy ticket
Say your easy tickets average 800K tokens at 153:1 (~795K in / 5K out). Haiku 4.5 ($1/$5): 0.795M x $1 + 0.005M x $5 = ~$0.82 raw; at a 73% pass rate that is ~$1.12 per fix. GPT-5.5 ($5/$30): 0.795M x $5 + 0.005M x $30 = ~$4.13 raw; at 88% that is ~$4.69 per fix. The flagship costs 4x more per shipped easy fix for an accuracy edge you do not need on easy work.Why you must compute this per task type, not once
Easy tickets might run 800K tokens; a hard multi-file migration with retries can hit 3.5M. A single blended cost-per-task figure averages these into a number that is wrong for both. Bucket your tasks, compute cost-per-fix per bucket, and route each bucket to its cheapest qualifying agent. That tiering is where the real savings live.Where prompt caching changes the math
Because input tokens drive ~99% of the bill at a 153:1 ratio, caching the stable parts of your context (system prompt, repo map, unchanged files) can cut input cost by up to 90% on cache hits. On a token-dominated agentic task, that is a far larger lever than switching to a cheaper output price — it attacks the part of the bill that actually matters.Builder’s take
I run agent pipelines for a living at Cyntr and Loomfeed, so I pay these token bills personally. The leaderboards and pricing roundups both lie by omission. Here is how I actually budget coding agents:
- Never compare sticker prices. A $1/M model that fails half its tasks is more expensive per shipped fix than a $5/M model that lands them. Always divide cost by pass rate before you decide.
- Token efficiency is an underpriced moat. Claude Code burning 33K tokens where Cursor burns 188K on the identical task is a 5.5x discount that no price page shows you.
- Tier your fleet. I route easy, high-volume tasks to Haiku 4.5 or an open-weight stack, and reserve flagship spend for the gnarly multi-file changes where a higher pass rate actually pays for itself.
- Treat the 30x run-to-run token variance as a budgeting reality, not an edge case. Cap retries and set per-task token ceilings or one stuck task will eat a day of margin.
- Devin’s flat subscription is not free money. Normalize the $500/mo to per-completed-task before you assume it beats token billing; on unassisted hard tasks it often does not.
Frequently asked questions
On dollars per successful SWE-bench fix, open-weight stacks like OpenHands or Aider on DeepSeek V3.2 are cheapest (under ~$1 per fix in our model), followed by Claude Haiku 4.5 at roughly $2.10. Flagships like GPT-5.5 and Claude Code cost 4-6x more per completed fix because the price gap outruns their accuracy edge on most tasks.
Claude Code on Opus 4.7 costs roughly $10-12 per successful fix in our 2026 model, driven by Opus pricing of $15/$75 per million tokens. It partly offsets this with strong token efficiency — as few as 33K tokens where Cursor used 188K on the same task — and a high ~87.6% pass rate, which reduces costly rework on complex multi-file changes.
A well-scoped Devin bug fix runs about 2-3 ACUs (~$4-6) on the $500/mo Team plan, but because Devin’s unassisted SWE-bench pass rate is near 45.8%, its dollars-per-successful-fix climbs to roughly $10.92. The flat subscription hides failed attempts, making Devin 5-10x more expensive per completed task than token-billed rivals on pure unit economics.
On raw cost per completed fix, gpt-5.2-codex is cheaper (~$3.34 vs ~$11.86) because it is priced at $1.75/$14 per million tokens versus Opus 4.7’s $15/$75. Claude Code closes the gap through superior token efficiency and a higher pass rate, which can flip the economics on complex tasks where failed attempts are expensive to redo.
An agentic SWE-bench-style task consumes about 1 to 3.5 million tokens including retries — roughly 1000x a single code-chat turn — according to Stanford’s Digital Economy Lab and Microsoft Research. Input tokens dominate at a ~153:1 ratio because every tool call re-feeds the context, and the same task can vary up to 30x in tokens run-to-run.
Because cost per successful fix divides price by pass rate. When a cheap model like Haiku 4.5 (73.3% on SWE-bench Verified at $1/$5) stays close to a flagship’s accuracy but costs 5-15x less, the price gap outruns the accuracy gap. The flagship only wins on the hardest tasks where its higher pass rate finally justifies the spend.
Primary sources
- How Do AI Agents Spend Your Money? (token consumption study) — arXiv / Stanford Digital Economy Lab
- How are AI agents spending your tokens? — Stanford Digital Economy Lab
- SWE-Bench Leaderboard May 2026: GPT-5.5 Leads at 88.7% — marc0.dev
- Introducing Claude Haiku 4.5 — Anthropic
- 14 Best AI Coding Agents (2026) — Morph
- Devin Pricing in 2026: Real Cost, Hidden Spend and Alternatives — Brainroad
- Devin 2.0 is here: price slashed to $20/mo from $500 — VentureBeat
- GPT-5.5 API Pricing Guide 2026 — Evolink
- Claude Code vs Cursor Developer Benchmark 2026 — SitePoint
- DeepSeek V3.2 API Pricing & Benchmarks — OpenRouter
Last updated: June 3, 2026. Related: Products.




