

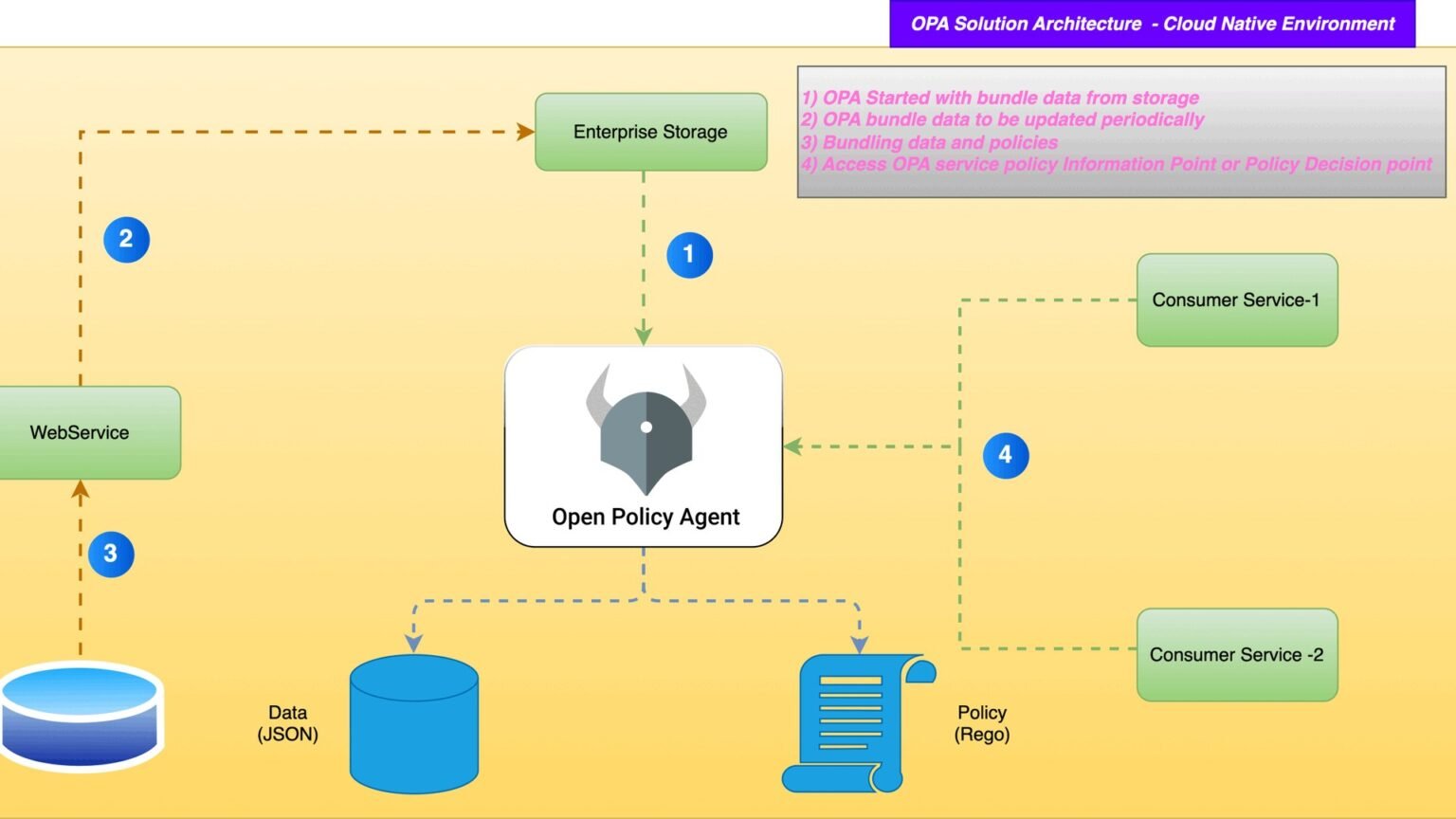
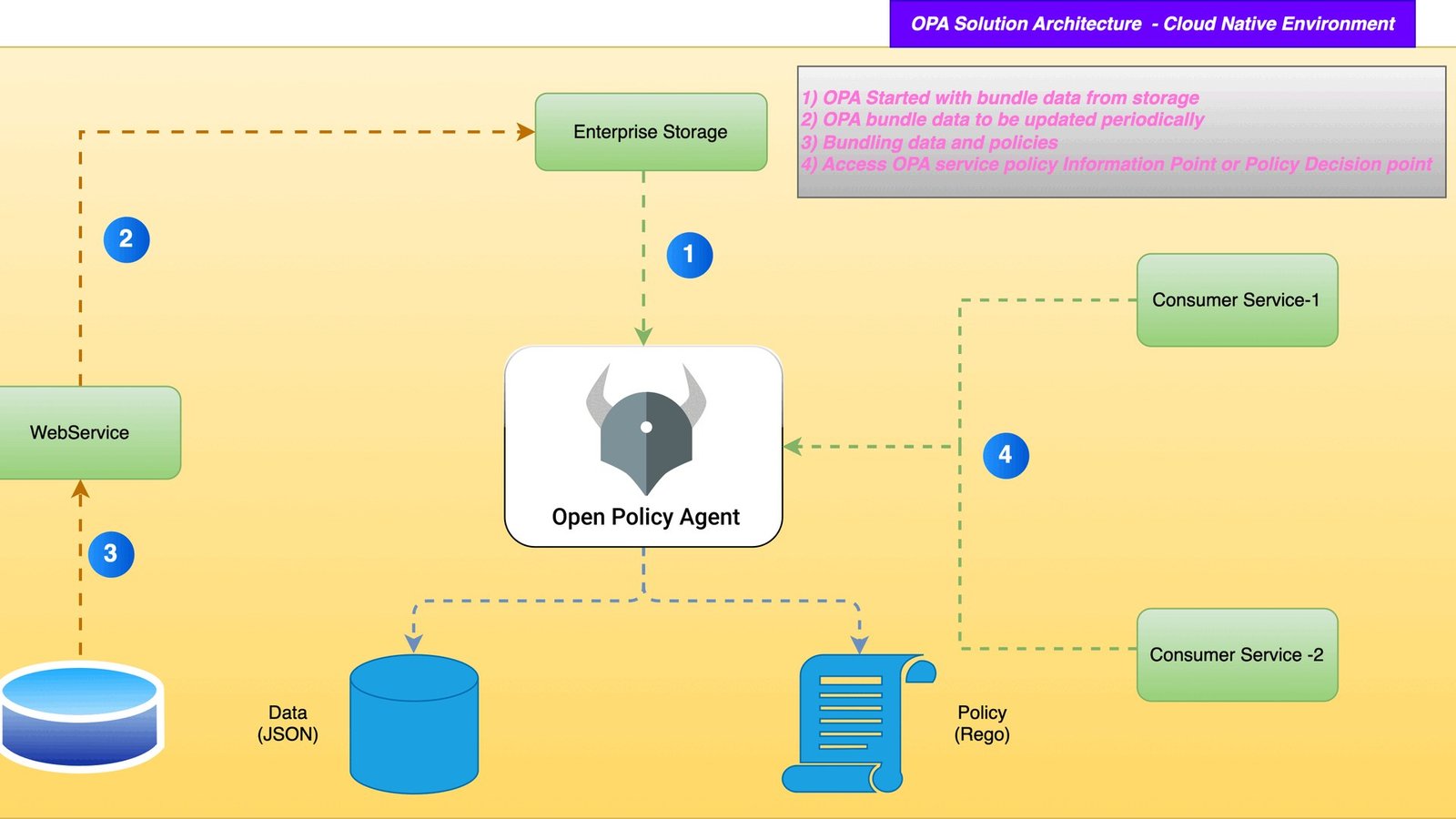
A framework-agnostic, copy-paste tutorial: intercept every tool call before side effects, POST the tool name, arguments, and agent identity to Open Policy Agent, and let real Rego decide allow, deny-with-reason, or escalate.
How do you authorize AI agent tool calls with OPA Rego?
To authorize AI agent tool calls with OPA Rego, you intercept the call in a pre-execution hook the moment the model has chosen a tool but before any side effect runs, POST the tool name, its arguments, and the agent’s identity to Open Policy Agent, and let a Rego policy return allow, deny-with-reason, or escalate. The model can reason and pick a tool, but whether that tool actually executes is decided by policy that lives outside the agent, versioned in source control, and testable like any other code.
This is the loop almost every tutorial skips. The generic OPA docs teach you Rego in the abstract. Framework-locked guardrails such as the OpenAI Agents SDK bolt a decision onto one runtime. Hosted authorization vendors sell you a black box. None of them ship the full vendor-neutral path: model picks a tool, you intercept before side effects, you send identity plus arguments to a policy engine, and you get back a structured decision wired to audit logging and a control plane.
This tutorial ships that path end to end. You get a framework-agnostic Python interceptor that works whether you use LangChain, the OpenAI Agents SDK, a raw tool-calling loop, or an MCP client; a complete copy-paste Rego bundle with per-tool allow/deny, argument constraints, identity-scoped rules, and deny reasons; and the exact placement of the enforcement point. Everything here runs against a stock open-source OPA binary — no SaaS account required.
A reusable authorize() function that any agent framework calls before executing a tool, backed by a Rego bundle that enforces per-tool rules, argument limits, and identity scopes — returning allow, deny-with-reason, or escalate-to-human.
Why use a policy engine for AI agent tool calling instead of prompt rules?
You use a policy engine for AI agent tool calling because authorization belongs at the tool-calling layer, not the agent layer — even if the agent is tricked into attempting a prohibited action, OPA blocks it before it reaches the target system. Rules written into a system prompt are advisory; a prompt-injected or hallucinating model can ignore them. A policy engine queried before every action is deterministic, runs in milliseconds, and produces a record you can show an auditor.
CodiLime frames OPA as the missing guardrail precisely because the policy engine does the authorization work, not the agent. That separation is the whole point. The large language model has no say in the decision. It picks a tool; an external, declarative policy decides whether the tool runs.
Rego is OPA’s declarative policy language: instead of writing step-by-step logic, you describe what is allowed and OPA evaluates it against an input document you send. Because policies are data, you can test them in the Rego Playground, diff them in pull requests, and roll them back like any other code. OPA can also evaluate multiple authorization layers — tool access, resource access, and command-level checks — in a single query and return per-resource denial reasons in batch, which matters when one agent action touches several resources at once.
The model can reason and it can pick a tool, but whether that tool actually runs is determined by a policy that lives outside the agent — written in Rego, versioned in source control, and testable likWhere is the correct pre-execution authorization point for an AI agent?
The correct enforcement point is a pre-execution hook that fires after the model has chosen a tool but before any side effect runs — it is the only point that has the tool name, the full arguments, the agent identity, and the delegation chain all at once. Aport’s guide calls this the one place with everything it needs to make a sound decision while staying external to model influence. Authorize too early and you do not yet know the arguments; authorize inside the tool and the side effect has already started.
Concretely, a normal tool-calling loop looks like: send messages to the model, receive a tool call, run the tool, append the result, repeat. The authorization hook slots in between ‘receive a tool call’ and ‘run the tool.’ If the policy denies, you short-circuit and feed the denial reason back to the model as the tool result so it can replan. If the policy allows, execution continues unchanged.
The data you send to OPA is the heart of the design. Aport’s authorizer receives four inputs: the tool name and complete arguments, the agent identity (a stable identifier or DID), the delegation chain context, and the current request context. Send all four. The richer the input document, the more expressive your Rego can be — identity-scoped rules are impossible if the engine never sees who the agent is acting as.
Standard tool-calling loop with the enforcement point inserted:
1. messages -> model
2. model returns a tool call: { name, arguments }
3. *** authorize(tool, args, identity) -> OPA *** <- PRE-EXECUTION HOOK
allow -> run the tool
deny -> skip the tool, return reason to the model, let it replan
escalate -> pause, request human approval, then run or abort
4. append tool result (or denial reason) to messages
5. loop until the model produces a final answer
The hook sits AFTER the model chooses (step 2) and BEFORE any side
effect (step 3). That is the only point with name + args + identity
together and nothing executed yet.How do you call the OPA REST API to authorize a tool call?
You POST a JSON input document to OPA’s Data API at POST /v1/data/; OPA binds your JSON to the global input variable, evaluates the Rego, and returns the decision under a result key. If the decision is undefined, OPA returns HTTP 200 with no result key, so your client must treat a missing result as deny-by-default. This is the contract every framework-agnostic integration relies on.
Run OPA locally as a sidecar — opa run --server --bundle ./bundle — and it listens on port 8181. Your agent process calls it over localhost, so there is no network round trip to a vendor and policy evaluation stays in single-digit milliseconds. Bundle persistence keeps the last-known-good policy loaded even if the control plane that ships bundles is briefly unreachable.
Below is the entire vendor-neutral interceptor. It is plain httpx and a dataclass — no framework imports — so you can drop it into any agent runtime. It returns a structured decision object with the three outcomes the brief calls for: allow, deny-with-reason, and escalate.
# authz.py — framework-agnostic OPA interceptor for AI agent tool calls
import hashlib
import json
from dataclasses import dataclass
from enum import Enum
import httpx
OPA_URL = "http://localhost:8181/v1/data/agent/tools/decision"
class Outcome(str, Enum):
ALLOW = "allow"
DENY = "deny"
ESCALATE = "escalate"
@dataclass
class Decision:
outcome: Outcome
reason: str # machine-readable code, e.g. "amount_over_limit"
policy: str | None # which policy pack decided, for audit
def authorize(tool: str, arguments: dict, identity: dict) -> Decision:
"""Call OPA BEFORE the tool runs. Deny-by-default on any ambiguity."""
payload = {
"input": {
"tool": tool,
"arguments": arguments,
"identity": identity, # {"sub": "agent:cyntr-ops",
# "scopes": [...], "delegated_by": "user:42"}
"arg_hash": hashlib.sha256(
json.dumps(arguments, sort_keys=True).encode()
).hexdigest(),
}
}
try:
resp = httpx.post(OPA_URL, json=payload, timeout=2.0)
resp.raise_for_status()
result = resp.json().get("result")
except Exception:
# Engine unreachable or error -> fail closed.
return Decision(Outcome.DENY, "policy_engine_unavailable", None)
# Undefined decision (no rule matched) -> OPA omits "result" -> deny.
if not result:
return Decision(Outcome.DENY, "no_matching_policy", None)
return Decision(
outcome=Outcome(result.get("outcome", "deny")),
reason=result.get("reason", "unspecified"),
policy=result.get("policy"),
)What does a complete Rego policy bundle for AI agent tools look like?
A complete Rego bundle for AI agent tools defines a single decision rule that combines per-tool allow/deny, argument constraints, and identity-scoped rules, and returns a structured object — outcome, reason, and policy — so the caller gets a machine-readable deny reason instead of a bare false. Because Rego is declarative, you describe each condition once and OPA composes them; an undefined decision means no rule matched, which your interceptor already treats as deny.
This bundle enforces four things the brief asks for. First, per-tool allow/deny: only tools in an allow-list are eligible, and a sensitive subset is denied outright. Second, argument constraints: the refund.issue tool is capped at an amount, demonstrating value-level checks on arguments, not just tool names. Third, identity scope: a tool only runs if the agent’s identity carries the matching scope, so a read-only agent cannot call a write tool. Fourth, escalation: high-impact tools return escalate rather than allow, routing the call to a human approver.
Save this as bundle/agent/tools/policy.rego and serve it with opa run --server --bundle ./bundle. You can paste the same policy into the Rego Playground to test inputs interactively before you ship it.
package agent.tools
# ---- Static policy data (could also be loaded from data.json) ----
allowed_tools := {"search.web", "db.read", "refund.issue", "db.delete"}
# Identity scope each tool requires.
tool_scope := {
"search.web": "read",
"db.read": "read",
"refund.issue": "write:refund",
"db.delete": "write:destructive",
}
# Tools that always require a human, regardless of scope.
escalate_tools := {"db.delete"}
max_refund_cents := 50000 # $500 hard ceiling on argument value
# ---- Helpers ----
has_scope(s) if s == tool_scope[input.tool]; s in input.identity.scopes
refund_within_limit if {
input.tool != "refund.issue"
}
refund_within_limit if {
input.tool == "refund.issue"
input.arguments.amount_cents <= max_refund_cents
}
# ---- Decision: returns a structured object, never a bare boolean ----
# 1. Unknown tool -> explicit deny with reason.
decision := {"outcome": "deny", "reason": "tool_not_allowlisted",
"policy": "agent.tools"} if {
not input.tool in allowed_tools
}
# 2. Missing identity scope -> deny.
decision := {"outcome": "deny", "reason": "insufficient_scope",
"policy": "agent.tools"} if {
input.tool in allowed_tools
not has_scope(tool_scope[input.tool])
}
# 3. Argument constraint violated -> deny with the specific reason.
decision := {"outcome": "deny", "reason": "amount_over_limit",
"policy": "agent.tools"} if {
input.tool == "refund.issue"
has_scope(tool_scope[input.tool])
not refund_within_limit
}
# 4. Scoped, constrained, but high-impact -> escalate to a human.
decision := {"outcome": "escalate", "reason": "human_approval_required",
"policy": "agent.tools"} if {
input.tool in escalate_tools
has_scope(tool_scope[input.tool])
}
# 5. Everything checks out -> allow.
decision := {"outcome": "allow", "reason": "ok",
"policy": "agent.tools"} if {
input.tool in allowed_tools
not input.tool in escalate_tools
has_scope(tool_scope[input.tool])
refund_within_limit
}How do you wire the OPA decision into the agent loop and audit log?
You wire the decision in by calling authorize() at the pre-execution hook, then branching: on allow you run the tool, on deny you return the reason to the model so it can replan, and on escalate you pause for human approval — and you log every outcome, allow and deny alike. This is the framework-agnostic glue that the OpenAI Agents SDK hides inside its own guardrail API; here it is explicit and portable.
The deny path is the one teams get wrong. Do not raise an opaque exception that kills the run. Feed the machine-readable reason back as the tool’s result. The model reads amount_over_limit and tries a smaller refund or hands off; it reads insufficient_scope and stops asking. Returning the reason is what turns a hard block into productive replanning instead of an infinite loop.
Every call to authorize() should emit one audit event — timestamp, agent identity, tool name, the argument hash (so you log the decision without leaking raw arguments), outcome, and the policy pack that decided. Allow events are the boring majority that prove the control was live; deny and escalate events are the ones an incident review reads first. Pair this with a signed, hash-chained log and the record becomes tamper-evident.
# loop.py — drop-in tool dispatch that any framework can call
import logging
from authz import authorize, Outcome
log = logging.getLogger("agent.audit")
def run_tool_with_authz(tool, arguments, identity, tools, request_human):
"""Call this in place of directly invoking a tool.
`tools` maps name -> callable. `request_human` blocks for approval.
Returns the string the agent loop appends as the tool result.
"""
decision = authorize(tool, arguments, identity)
# One audit line per decision — allow, deny, AND escalate.
log.info("authz outcome=%s tool=%s sub=%s reason=%s policy=%s",
decision.outcome, tool, identity["sub"],
decision.reason, decision.policy)
if decision.outcome == Outcome.DENY:
# Feed the reason back so the model can replan, not crash.
return f"TOOL_DENIED: {decision.reason}. Choose a different action."
if decision.outcome == Outcome.ESCALATE:
approved = request_human(tool, arguments, identity, decision.reason)
log.info("human_review tool=%s approved=%s", tool, approved)
if not approved:
return f"TOOL_DENIED: human_rejected ({decision.reason})."
# ALLOW (or human-approved escalation) -> the side effect runs here.
result = tools[tool](**arguments)
return str(result)How is external OPA different from the OpenAI Agents SDK tool guardrails?
The OpenAI Agents SDK runs tool guardrails inside the framework — its @tool_input_guardrail and @tool_output_guardrail functions return a ToolGuardrailFunctionOutput that can allow, reject the content with a message, or raise a tripwire exception — whereas external OPA decouples the policy from your application code entirely. Both stop a bad call before its side effect, but they answer different questions: the SDK asks ‘does this framework permit the call,’ OPA asks ‘does my organization’s policy permit it, no matter which framework made the call.’
The SDK’s model is real and useful: input guardrails run before the tool and can skip the call or replace its output, output guardrails run after and can rewrite or block it, and a triggered tripwire raises ToolGuardrailTripwireTriggered to halt the run. But those guardrails apply only to function tools created with the SDK, the policy lives in Python next to the agent, and you are coupled to that one runtime’s release cycle. Move to a different framework and the rules do not come with you.
External OPA inverts that. The same Rego bundle authorizes calls from a LangChain agent, an OpenAI Agents SDK run, an MCP client, and a raw tool-calling loop — because the policy is queried over HTTP and never imports the framework. You get one place to write rules, one place to test them, and one audit stream across every agent you operate. For a single app the built-in guardrail is fine; for a fleet under one governance model, you want the engine outside the code.
Pros
Cons
“For a single app the built-in guardrail is fine. For a fleet under one governance model, you want the engine outside the code.”
Surya Koritala, founder of Cyntr and Loomfeed
| Capability | External OPA + Rego | OpenAI Agents SDK tool guardrails |
|---|---|---|
| Where the policy lives | Outside the app, queried over HTTP | Inside the framework, in Python |
| Works across frameworks | Yes — any runtime POSTs the same input | No — function tools in this SDK only |
| Pre-execution interception | Yes, in your hook before any side effect | Yes, input guardrail before the tool |
| Allow / deny / escalate | All three, structured object | allow, reject_content, raise_exception (tripwire) |
| Machine-readable deny reason | Yes — reason code drives replanning | reject_content message to the model |
| Argument-value constraints | Yes — Rego inspects argument values | Custom code in the guardrail function |
| Identity-scoped rules | Yes — identity in the input document | Manual, app-managed |
| Central audit + control plane | Yes — one stream across the fleet | Per-app, per-framework |
How do you test and roll out OPA authorization for AI agents safely?
Put the deny outside the model
You roll out OPA authorization safely by writing Rego unit tests, running the engine in shadow (log-only) mode first, then flipping to enforce once the deny rate looks right. Rego is testable like any other code: opa test ./bundle runs assertions against your decision rule, so you ship policy with the same confidence you ship a function. Test the deny paths, not just the happy path — an authorization layer that only proves allows is untested where it matters.
Shadow mode is the difference between a safe rollout and an outage. Run authorize() and log the outcome, but do not yet block — execute the tool regardless and compare what the policy would have done against what actually happened. When the would-have-denied set contains only the calls you genuinely want stopped, flip the dispatch to honor the decision. I run every Cyntr policy change in shadow before it enforces.
Keep deny-by-default as your backstop everywhere. The interceptor fails closed on an unreachable engine, OPA omits result for an undefined decision, and the Rego falls through to no match — three independent layers that all resolve to deny. That is the posture you want: the only way a tool runs is an explicit, logged, policy-backed allow.
# policy_test.rego — run with: opa test ./bundle
package agent.tools
test_unknown_tool_denied if {
decision.outcome == "deny"
decision.reason == "tool_not_allowlisted"
} with input as {"tool": "shell.exec", "arguments": {},
"identity": {"sub": "a", "scopes": ["read"]}}
test_read_allowed_with_scope if {
decision.outcome == "allow"
} with input as {"tool": "db.read", "arguments": {},
"identity": {"sub": "a", "scopes": ["read"]}}
test_refund_over_limit_denied if {
decision.outcome == "deny"
decision.reason == "amount_over_limit"
} with input as {"tool": "refund.issue",
"arguments": {"amount_cents": 90000},
"identity": {"sub": "a", "scopes": ["write:refund"]}}
test_delete_escalates if {
decision.outcome == "escalate"
} with input as {"tool": "db.delete", "arguments": {"id": 7},
"identity": {"sub": "a", "scopes": ["write:destructive"]}}
test_write_without_scope_denied if {
decision.outcome == "deny"
decision.reason == "insufficient_scope"
} with input as {"tool": "refund.issue",
"arguments": {"amount_cents": 100},
"identity": {"sub": "a", "scopes": ["read"]}}OPA returns HTTP 200 but my interceptor always denies
OPA omits the result key when a decision is undefined. If no decision rule matches your input, you get 200 with no result, which the interceptor correctly treats as deny. Paste your exact input into the Rego Playground and confirm decision is defined; a typo in input.tool or a missing scope is the usual cause.The agent loops forever after a deny
You are likely raising an exception or returning an empty result instead of the reason. Return a string like TOOL_DENIED: insufficient_scope as the tool result so the model reads the reason and replans. A bare failure with no signal makes the model retry the same call.Escalation blocks the whole process
request_human() in the example is synchronous for clarity. In production, persist the pending call, return control to the user or a queue, and resume when approval arrives — wire this to your human-in-the-loop review surface rather than blocking the worker thread.Policy changes do not take effect
If you started OPA with –bundle, edits to files are not hot-reloaded unless you point at a bundle server or restart. For local iteration, restart opa run, or serve bundles from your control plane with a polling interval so new policy ships without a redeploy.Latency spikes on every tool call
Run OPA as a localhost sidecar, not a remote service, so evaluation stays in single-digit milliseconds. Keep the input document small — send an argument hash for audit rather than echoing large payloads, and avoid pulling huge external data into the policy at query time.Builder’s take
I have shipped policy-gated tool calling in Cyntr, and the lesson is that the model is the wrong place to keep your authorization rules. Here is what I would tell any team starting today.
- Put the decision in Rego, not in the prompt. A jailbroken model can talk its way past an instruction; it cannot talk its way past a deny that fires in your interceptor before the side effect runs.
- Make deny return a reason code, not a generic refusal. The reason is what lets the agent replan instead of looping, and it is what an auditor reads six months later.
- Treat ‘escalate to human’ as a first-class outcome, not an error. The most useful policies I run are the ones that pause a payment or a delete and hand it to a person.
- Log allow AND deny. The allows are the boring 99% that prove the system was working the day something went wrong.
- Keep the engine external. The second your authorization lives inside one framework’s guardrail API, you have coupled your security posture to that framework’s release cycle. Cyntr stays framework-agnostic for exactly this reason.
Frequently asked questions
Intercept the call in a pre-execution hook after the model chooses a tool but before any side effect runs, POST the tool name, arguments, and agent identity to OPA’s Data API at /v1/data/
At the pre-execution hook — the point after the model has selected a tool and produced its arguments but before the tool executes. Aport identifies this as the only enforcement point with the tool name, full arguments, agent identity, and delegation chain available at once, and where nothing has happened yet, so a deny truly prevents the side effect.
They solve different scopes. The OpenAI Agents SDK’s tool guardrails (@tool_input_guardrail / @tool_output_guardrail returning ToolGuardrailFunctionOutput) are excellent for a single app on that framework and can allow, reject content, or raise a tripwire. External OPA is better when you operate multiple frameworks or agents under one governance model, because the same Rego bundle authorizes any runtime and gives you one audit stream and control plane.
Have your decision rule return a structured object — for example {“outcome”: “deny”, “reason”: “amount_over_limit”, “policy”: “agent.tools”} — instead of a bare boolean. The interceptor surfaces the machine-readable reason code back to the model as the tool result, which lets the agent replan rather than retry blindly, and writes the reason to the audit log for compliance review.
Yes. Because OPA binds your full input document — including arguments — to the global input variable, Rego can inspect argument values directly. The bundle in this tutorial caps refund.issue at a maximum amount_cents and denies anything over the ceiling with reason amount_over_limit, demonstrating value-level argument constraints alongside per-tool allow/deny and identity scopes.
Fail closed. The interceptor returns a deny with reason policy_engine_unavailable on any connection error or timeout, and OPA omits the result key for undefined decisions, which the client also treats as deny. Combined with deny-by-default in the Rego itself, three independent layers ensure a tool only runs on an explicit, logged allow — never on the absence of a decision.
Primary sources
- Why Open Policy Agent is the Missing Guardrail for Your AI Agents — CodiLime
- AI Agent Authorization: The Complete Guide to Pre-Execution Guardrails — Aport
- OPA REST API Reference — Open Policy Agent
- Open Policy Agent — Documentation — Open Policy Agent
- Tool guardrails — OpenAI Agents SDK reference — OpenAI
- Guardrails — OpenAI Agents SDK — OpenAI
Last updated: June 2, 2026. Related: Identity Provenance.




