

Mem0 is one of the clearest attempts to turn “agent memory” into a reusable infrastructure layer rather than an ad hoc prompt hack. This review examines what the company and project publicly document: installation paths, API ergonomics, supported vector databases, integration patterns, and the kinds of workloads Mem0 appears to handle well. For readers comparing memory systems more broadly, see our guide to top AI agent memory layers and our breakdown of RAG vs agent memory.
Mem0 at a glance
Verdict: strong specialist, not a magic layer
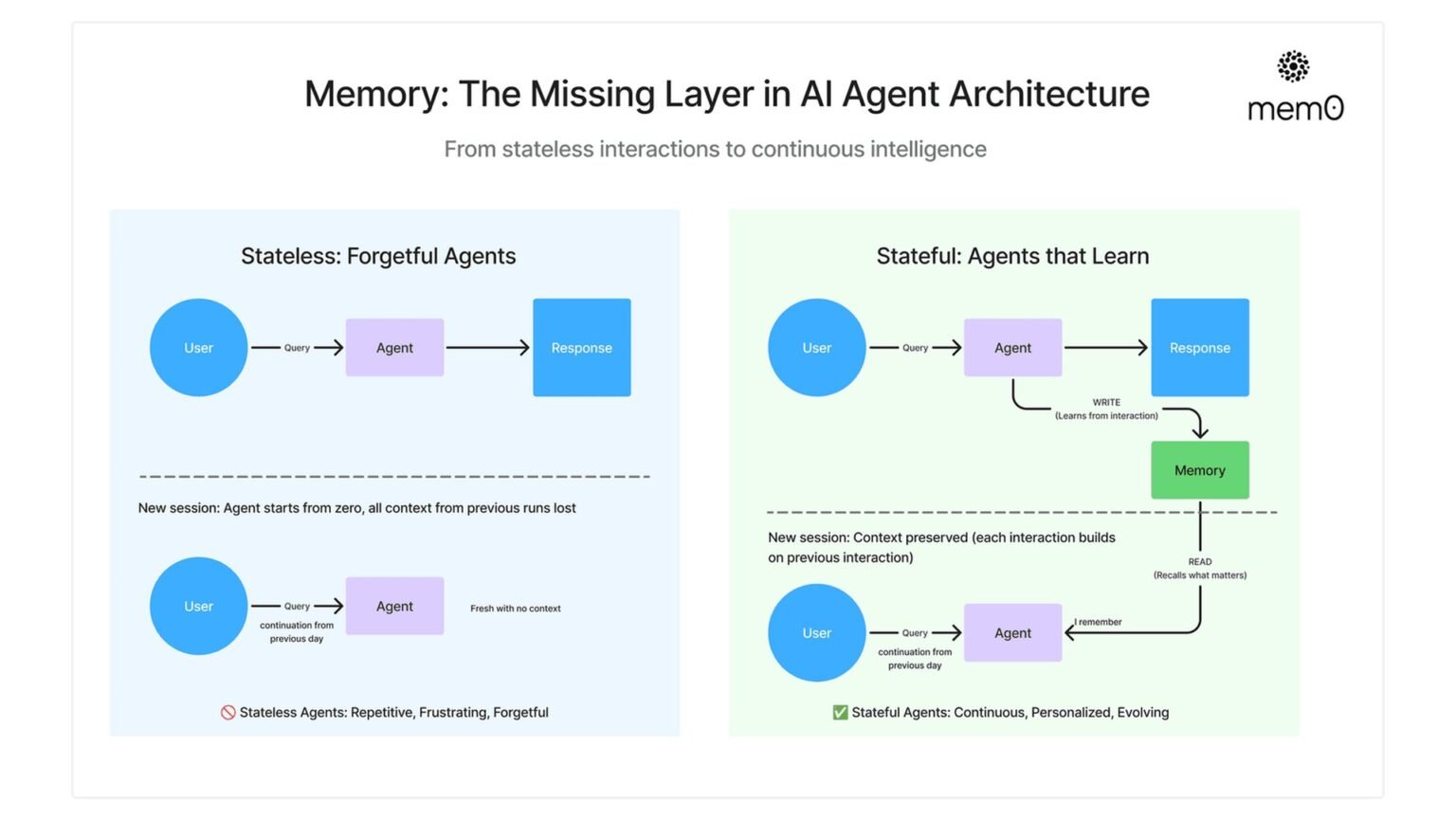
Mem0 is an open-source and commercial memory layer for AI applications and agents. The public positioning is consistent across the company site, docs, and GitHub repository: Mem0 extracts salient facts from interactions, stores them, and retrieves relevant memories later so assistants can behave more consistently over time. That places it in a useful middle layer between a model API and a full application stack.
The project matters because many teams discover the same limitation at roughly the same point in development. A chatbot can answer questions statelessly, but once product requirements shift toward personalization, continuity, or user preference tracking, prompt history alone becomes brittle and expensive. Mem0’s pitch is that memory should be explicit infrastructure, not a side effect of ever-longer context windows.
Publicly documented integrations also make the product easier to evaluate than many “agent platform” claims. Mem0 provides docs for direct API usage and framework integrations, including LangChain and LlamaIndex, while its open-source repository gives developers a visible implementation surface instead of a black box.
Mem0 ⭐ Editor’s Pick
Best for: Teams building AI assistants that need durable user preferences, conversation continuity, and framework-friendly memory retrieval
What works
Watch out for

📌 What this review is based on. This review is grounded in Mem0’s official site, documentation, GitHub repository, and published case studies—not private testing claims.
What Mem0 is actually trying to solve
The easiest way to understand Mem0 is to separate it from adjacent categories. It is not just a vector database, and it is not a full orchestration framework. A vector store can persist embeddings, but it does not decide what from a conversation deserves to become memory. An orchestration framework can manage chains or agents, but it does not automatically provide durable, selective memory semantics. Mem0 sits in that gap.
That positioning is visible in the project’s language around memory extraction and retrieval. Rather than dumping every message into storage, Mem0 emphasizes identifying useful facts—preferences, recurring constraints, profile details, and other durable signals—and making them available later. For product teams, that is the difference between “search the transcript” and “remember that this user prefers weekly summaries in bullet points.”
This is also why Mem0 belongs in the same conversation as agent memory systems rather than classic RAG. Retrieval-augmented generation usually starts from external knowledge sources such as documents, tickets, or manuals. Agent memory starts from interaction history and user-specific context. The two can complement each other, but they solve different problems. Readers deciding between them should also see our RAG vs agent memory guide.
“The real value proposition is not storage. It is deciding what deserves to be remembered.”
Editorial assessment based on Mem0 docs and repository
| Layer | Primary job | Where Mem0 fits |
|---|---|---|
| Vector DB | Store and retrieve embeddings | Mem0 can use one underneath but adds memory extraction and retrieval logic |
| RAG stack | Ground answers in external documents | Adjacent, not identical; Mem0 is more user- and interaction-centric |
| Agent framework | Coordinate tools, prompts, and workflows | Mem0 plugs into these systems as a memory component |
Setup and API: approachable if the surrounding stack is already modern
On setup, Mem0 benefits from doing the obvious things well. The official docs and GitHub repository provide installation guidance for the Python package and examples for creating and searching memories. For developers already comfortable with Python-based LLM tooling, the barrier to entry appears low. The project does not require adopting an entirely new application model just to test whether memory helps.
The API story is one of Mem0’s better traits. Public examples show a direct usage pattern where an application can add memories and search them later, which is the right abstraction for teams that want to control orchestration themselves. That matters because many production teams do not want a memory vendor dictating their entire runtime architecture.
Framework support broadens the appeal. Mem0 documents integrations with LangChain and LlamaIndex, which means teams already invested in those ecosystems can experiment without rewriting everything around a proprietary interface. That is a practical advantage over products that only work cleanly inside their own opinionated stack.
📌 Why the API matters. A memory layer is easier to adopt when it can be used as a narrow service instead of a full platform migration.
from mem0 import Memory
memory = Memory()
memory.add("The user prefers concise release notes and weekly digests.", user_id="user-123")
results = memory.search("How should I format updates for this user?", user_id="user-123")
print(results)Supported vector databases and deployment flexibility
Mem0’s documentation publicly references support for multiple vector backends, including Qdrant, Chroma, and Pinecone. That is an important practical signal. Memory infrastructure becomes much easier to justify when it can fit into an existing storage strategy rather than forcing a new one.
Qdrant appears prominently in Mem0 material and is often treated as the default path in examples and setup guidance. That makes sense. Qdrant has become a common choice for teams that want an open-source vector database with production-oriented features. Chroma lowers the barrier for local development and prototyping. Pinecone gives teams a managed option if they prefer not to operate vector infrastructure themselves.
This backend flexibility is one of Mem0’s strongest production arguments. It lets teams separate the question “Do we want a memory layer?” from the question “Do we want to change our vector database strategy?” Those are often bundled together in early-stage tooling, and Mem0 does a better job than most at keeping them distinct.
Pros
Cons
| Backend | Why teams choose it | Mem0 relevance |
|---|---|---|
| Qdrant | Open-source, production-oriented vector search | Well aligned with teams wanting self-hosted or controllable infrastructure |
| Chroma | Simple local development and prototyping | Useful for early evaluation and lightweight deployments |
| Pinecone | Managed vector database service | Appealing for teams that want less operational overhead |
Memory extraction quality: promising for preferences, less so for chronology
The central question for any memory layer is not whether it can store data. It is whether it can store the right data. Mem0’s public examples and case-study framing suggest the system is strongest at extracting durable user facts: preferences, profile details, recurring instructions, and contextual habits that should influence future responses.
That is the sweet spot for many assistant products. A support copilot might need to remember a customer’s preferred communication style. A personal assistant may need to retain travel preferences or formatting habits. A sales assistant may benefit from remembering role, company context, and prior objections. These are all patterns where selective memory beats replaying a full transcript.
The harder edge cases are the ones Mem0 does not appear to fully solve on its own. Complex temporal reasoning—understanding not just that a fact exists, but when it changed, whether it expired, and how conflicting memories should be reconciled—still looks like an application responsibility. The same goes for nuanced policy logic such as “remember this for one week unless the user revokes consent” or “treat this memory as workspace-scoped, not identity-scoped.”
That limitation is not unique to Mem0. It is common across the category. Still, it matters in production reviews because memory systems are often oversold as if retrieval alone creates continuity. In reality, continuity depends on extraction quality, retrieval ranking, scope controls, and lifecycle rules working together.
⚠️ Where expectations should stay realistic. Mem0 can help agents remember durable facts. It does not automatically solve time-aware reasoning, conflict resolution, or memory expiration policy.
“The strongest use case is durable preference memory, not full autobiographical intelligence.”
Editorial assessment based on Mem0 documentation and examples
Integration patterns: raw API, LangChain, and LlamaIndex all make sense
Mem0’s integration story is one reason it stands out in the agent memory category. The project supports direct usage for teams that want to wire memory into custom services, and it also documents framework integrations for LangChain and LlamaIndex. That combination is exactly what production buyers usually want: low-level access for control, plus enough ecosystem support to move quickly.
The raw API path is the cleanest fit for teams with established orchestration layers. In that setup, Mem0 acts like a memory microservice. The application decides when to write memory, what user or session scope to apply, and when to retrieve relevant facts before generation. This is often the most robust production pattern because it keeps memory decisions explicit.
LangChain and LlamaIndex integrations are useful for teams still iterating on architecture. They shorten time to prototype and make it easier to compare memory behavior inside familiar abstractions. The risk, as always with framework-heavy builds, is that important memory semantics can become hidden inside convenience layers. Teams with strict compliance or multi-tenant requirements will usually want to inspect those boundaries carefully.
pip install mem0ai| Pattern | Best for | Tradeoff |
|---|---|---|
| Raw API | Teams with custom orchestration and explicit control | More implementation work, but clearer production boundaries |
| LangChain integration | Fast prototyping in an established agent framework | Can obscure memory semantics if over-abstracted |
| LlamaIndex integration | Apps already built around LlamaIndex retrieval patterns | Still requires careful scoping and lifecycle design |
Where Mem0 works well in production-style use cases
The public evidence points to a fairly clear set of good fits. Mem0 is well matched to conversational products that need to remember user preferences across sessions. That includes formatting preferences, recurring goals, stable profile details, and other facts that improve the next interaction without requiring a full replay of prior context.
It also appears useful for lightweight personalization in assistants that need to feel consistent over time. This is the category where memory has immediate product value: fewer repeated questions, more tailored outputs, and a stronger sense that the system understands the user. Mem0’s extraction-and-retrieval framing is aligned with that outcome.
Another strong fit is teams that want memory without committing to a monolithic agent platform. Because Mem0 can sit alongside existing orchestration and storage choices, it is easier to evaluate incrementally. That lowers organizational risk. A team can test whether memory improves retention, task completion, or user satisfaction before redesigning the rest of the stack.
For readers mapping the broader landscape, this is also why Mem0 belongs in any serious comparison of memory infrastructure rather than general-purpose agent frameworks. We covered that broader market in our top AI agent memory layers roundup.
Where Mem0 is less convincing
Runner-up verdict: best when scoped narrowly
The first weak spot is complex temporal reasoning. If a user changes a preference, if a fact expires, or if multiple memories conflict, the application still needs rules for reconciliation. Mem0 can store and retrieve memories, but production-grade chronology is more than retrieval. It requires policy, timestamps, precedence, and often explicit invalidation logic.
The second concern is strict multi-tenant isolation. Mem0’s docs and architecture can support scoped memory patterns, but “supports scoping” is not the same thing as proving airtight enterprise isolation. In regulated or high-sensitivity environments, teams will need to design tenant boundaries, access controls, and deletion workflows carefully rather than assuming the memory layer alone guarantees them.
The third issue is governance. Memory is inherently more sensitive than generic retrieval because it often contains user-specific facts. That raises questions about consent, retention, deletion, and explainability. Mem0 is useful infrastructure, but it does not remove the need for product and legal decisions around what should be remembered in the first place.
None of these caveats disqualify the product. They simply place it in the right category: Mem0 is a practical memory component, not an autonomous memory policy system.
⚠️ Production caution. If the application handles sensitive user data, memory retention and deletion policies should be designed at the product and infrastructure layers, not delegated implicitly to retrieval behavior.
Pricing, open source posture, and the keep-paying question
Would I keep paying for this? Yes, with scope discipline
Mem0’s open-source repository is one of its biggest strategic advantages because it reduces adoption risk. Teams can inspect the project, evaluate the API shape, and test the memory model without starting from a closed commercial dependency. That alone makes the product easier to take seriously than vendors whose “memory” claims are visible only through marketing copy.
On commercial pricing, readers should verify current plans directly on Mem0’s official site because software packaging changes frequently. What matters more in this review is the buying logic. Mem0 is the kind of product worth paying for when a team has already validated that memory improves user outcomes and wants a cleaner abstraction than homegrown heuristics.
Would this publication’s verdict be to keep paying for it? In a narrow but important set of use cases, yes. If the product need is durable conversation memory, user preference recall, and framework-friendly integration, Mem0 looks like a sensible layer to keep in the stack. If the requirement is full memory governance, strict enterprise isolation guarantees, or sophisticated temporal reasoning, the answer is more cautious because those capabilities still depend heavily on surrounding architecture.
The cleanest final assessment is this: Mem0 is not the whole memory stack, but it looks like a strong core component of one.
📌 Would I keep paying for this?. Yes—if the goal is practical agent memory for preferences and conversational continuity. No—if the buyer expects a memory layer to replace governance, chronology, and tenant-boundary engineering.
“Mem0 earns its place when memory is a product feature, not just an architectural experiment.”
Final editorial verdict
Frequently asked questions
Mem0 is used to give AI applications and agents a persistent memory layer so they can remember user preferences, profile details, and prior conversational context across sessions. The company describes it as a memory layer for AI apps, and the open-source project shows patterns for adding and searching memories in application workflows. See Mem0’s official site and the GitHub repository.
Yes. Mem0’s documentation publicly references support for multiple vector database backends, including Qdrant, Chroma, and Pinecone. Readers should check the latest backend configuration details in the official docs because implementation options can evolve over time. Start with the Mem0 docs.
Yes. Mem0 documents integration patterns for both LangChain and LlamaIndex, alongside direct API usage. That makes it easier to adopt whether a team is building on a framework or wiring memory into a custom stack. The best place to verify current integration guidance is the official documentation.
No. RAG usually retrieves from external knowledge sources such as documents or databases, while Mem0 is focused on storing and retrieving user- or interaction-specific memories. The two can work together, but they solve different problems. Readers can compare the concepts in our RAG vs agent memory explainer and review Mem0’s positioning at mem0.ai.
Primary sources
- Mem0 official website — Mem0
- Mem0 GitHub repository — GitHub
- Mem0 documentation — Mem0
- Qdrant official website — Qdrant
- Chroma documentation — Chroma
- Pinecone official website — Pinecone
- LangChain documentation — LangChain
- LlamaIndex documentation — LlamaIndex
Last updated: May 20, 2026. Related: Agent Infrastructure.




