

NeMo Guardrails, Guardrails AI, Llama Guard 4, and LLM Guard solve different parts of the safety problem. Here is how the four open-source LLM guardrails stack up in 2026 and how to combine them.
What are LLM guardrails and why one tool is never enough
LLM guardrails are the programmable safety, security, and quality checks that sit between a user and a language model, inspecting inputs and outputs before they cause harm. They are the seatbelts of production AI: prompt-injection filters, PII redactors, toxicity classifiers, topic boundaries, and schema validators that run on the request path rather than inside the model weights. In 2026 they are no longer optional plumbing — they are the layer auditors, security teams, and the EU AI Act all ask about first.
The four tools in this comparison — NeMo Guardrails, Guardrails AI, Llama Guard 4, and LLM Guard — are the open-source defaults most teams evaluate, and they are routinely confused for one another. They are not interchangeable. NeMo is a programmable dialogue-control runtime. Guardrails AI is a structured-output and validation framework. Llama Guard 4 is a single safety-classifier model. LLM Guard is a broad input/output scanner library. They occupy different rows of the stack, which is exactly why the strongest production deployments run two or three of them together.
The mistake I see most often is treating LLM guardrails as a checkbox satisfied by one dependency. A schema validator will happily pass a perfectly-formed JSON object that contains an injected instruction. A safety classifier will flag the toxic completion but cannot enforce that your agent never calls the refund tool twice. Coverage comes from layering tools whose blind spots do not overlap.
This guide grounds every claim in current 2026 documentation and benchmarks, and flags where the numbers are shaky. A caveat up front: guardrail benchmark scores move with every release and degrade sharply under adversarial pressure, so treat the figures below as directional, not gospel.
NeMo Guardrails: programmable dialogue rails with Colang
NeMo Guardrails is NVIDIA‘s open-source toolkit for adding programmable, policy-as-code rails to conversational LLM systems, controlled through a dialogue DSL called Colang. Its defining feature is breadth of control: it defines five rail types — input, dialog, retrieval, execution, and output — that gate every stage of an interaction, from the raw user message to RAG chunks to tool calls to the final response. No other tool in this comparison touches dialogue flow and tool execution the way NeMo does.
Colang is an event-driven interaction-modeling language interpreted by a Python runtime. Colang 1.0 remains the default; Colang 2.0 exists but the project explicitly treated its public runtime state as unstable in recent releases, so most production users stay on 1.0. The trade-off is real: Colang gives you fine-grained, deterministic control over conversation flows, but it carries a steep learning curve and a small community relative to plain Python frameworks.
On performance, NeMo has invested heavily in hiding latency. Recent releases added parallel rails execution (rails run concurrently instead of sequentially) and speculative generation, which runs input rails in parallel with the main LLM’s response generation so the safety check overlaps with token generation rather than blocking it. NemoGuard models gained in-memory LFU caches to cut repeat-check latency, and an opt-in IORails engine (NEMO_GUARDRAILS_IORAILS_ENGINE=1) runs content-safety, topic-control, and jailbreak rails together. The server now exposes an OpenAI-compatible /v1/chat/completions endpoint and emits OpenTelemetry, so it slots into existing observability stacks.
Caveat on accuracy: the bundled NemoGuard 8B classifier is a reasonable open-source option but not the leader — independent testing put it around 0.793 F1 on OpenAI Moderation and 0.875 on HarmBench, behind purpose-built guards. NeMo’s strength is the orchestration layer, not the classifier weights. Note that the latest tagged release as of this writing was v0.22.0 (May 2025); confirm the current version against the GitHub releases page before you pin a dependency.
Guardrails AI and Llama Guard 4: validators versus a safety classifier
Guardrails AI is an open-source Python framework whose superpower is structured-output enforcement: it wraps an LLM call in composable input/output Guards and a hub of reusable validators. The Guardrails Hub ships well over 60 community validators — ToxicLanguage, CompetitorCheck, DetectPII, regex and SQL-injection checks, and schema validators that coerce model output into a Pydantic model or re-ask the LLM on failure. If your problem is ‘the model must always return valid, typed, on-policy structured data,’ this is the cleanest fit. As of the v0.10.0 release (April 2026) the project sits around 6.9k GitHub stars and offers a server mode for REST deployment.
Guardrails AI’s honest limitation is that it is a quality-and-format tool, not an adversarial-security tool. Stacking many validators gets hard to reason about, and it is better at catching a malformed schema or a competitor mention than a determined prompt injection. The team also publishes the open-source AI Guardrails Index, a benchmark comparing 24 guardrails across six risk categories — useful, but read it knowing the publisher built it.
Llama Guard 4 is Meta’s natively multimodal safety classifier — a single 12B model that scores both text and image inputs and outputs against the 14-category MLCommons hazard taxonomy (violent crimes, privacy, self-harm, elections, and so on), plus an S14 code-interpreter-abuse category for text. It returns a dead-simple verdict: safe, or unsafe followed by the violated category codes. Released in April 2025, it pruned Llama 4 Scout down to a 12B dense model that runs in roughly 24GB of VRAM, and it pairs naturally with Prompt Guard 2 (86M and 22M variants) for dedicated injection/jailbreak detection.
The catch with Llama Guard 4 is the gap between clean and adversarial performance. It posts strong clean-data numbers (around 0.961 F1 on HarmBench) but independent testing showed accuracy falling under jailbreak pressure (roughly 0.80 F1 on a jailbreak bench) and struggling badly on long context (about 0.602 F1 with a high false-positive rate). At roughly 0.459s latency it is also meaningfully slower than smaller purpose-built guards — a real cost on the input path of a high-QPS service.
LLM Guard: the broad input and output scanner
LLM Guard, from Protect AI, is a broad open-source scanning library that wraps an LLM with a battery of input and output scanners for security and compliance risks. It ships roughly 15 input scanners and 20 output scanners — PII anonymization, secrets redaction, prompt-injection and jailbreak detection, toxicity, ban-topic and ban-substring filters, plus output-side checks for JSON validity, relevance, and competitor leakage. It is model-agnostic (GPT, Llama, Mistral, Falcon, anything) and reports more than 2.5 million downloads, which makes it the de facto open-source first line of defense.
Where LLM Guard wins is as the cheap, broad, self-hosted top-of-funnel: catch the obvious PII, the obvious injection, the obvious toxic content on every request without a vendor dependency or per-call pricing. Its anonymize scanner can vault and later restore PII so downstream tools never see raw sensitive data. The honest trade-off is that individual scanners are less sophisticated than dedicated commercial detectors, there is no managed pattern-update feed, and you get no dashboard or vendor support — you own the maintenance.
This is the tool that does the unglamorous 80% so your expensive classifier only has to handle the 20%. In my own pipelines, the broad scanner runs first and rejects or sanitizes the bulk of garbage cheaply, which keeps the heavier model off the hot path.
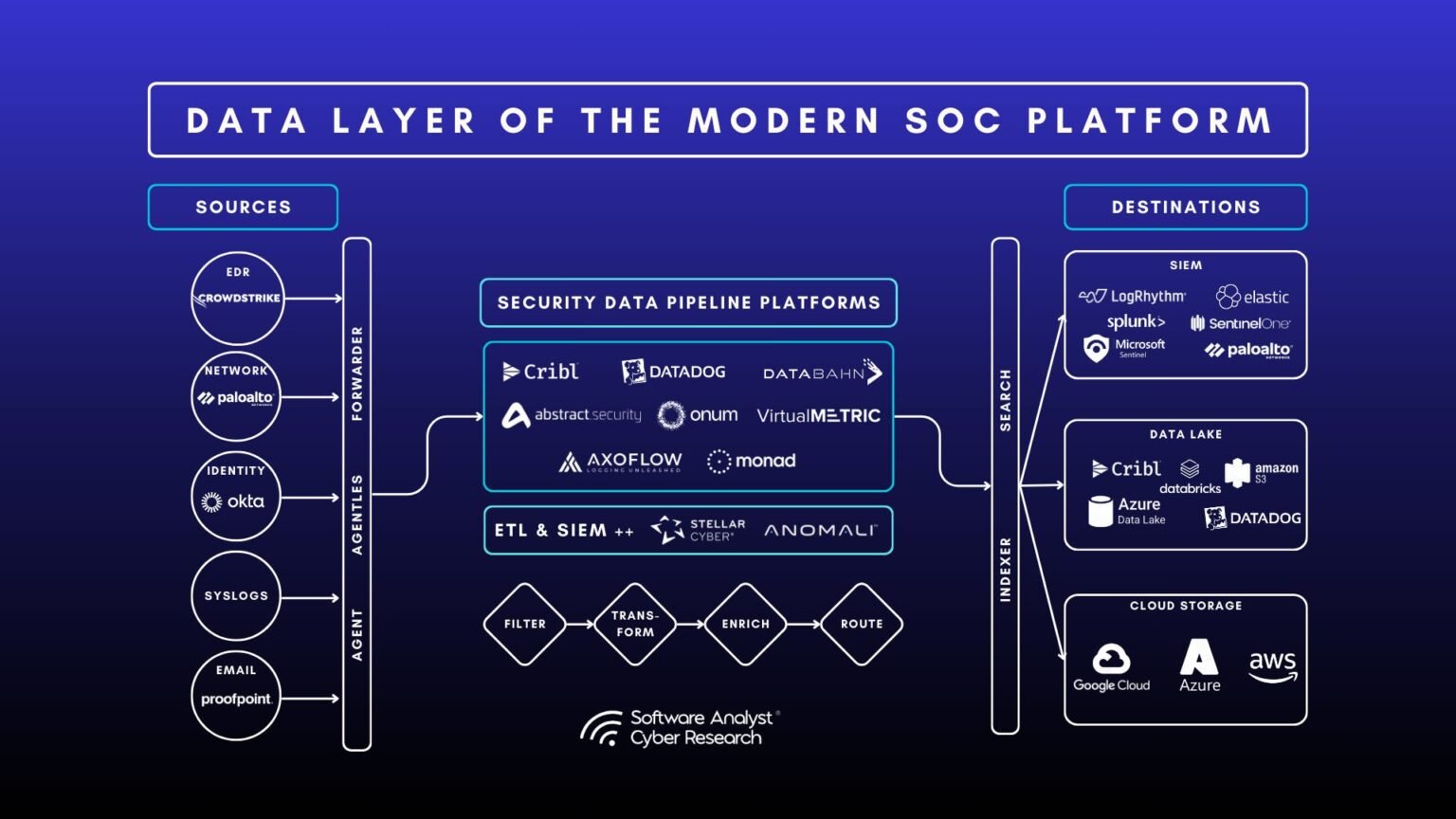
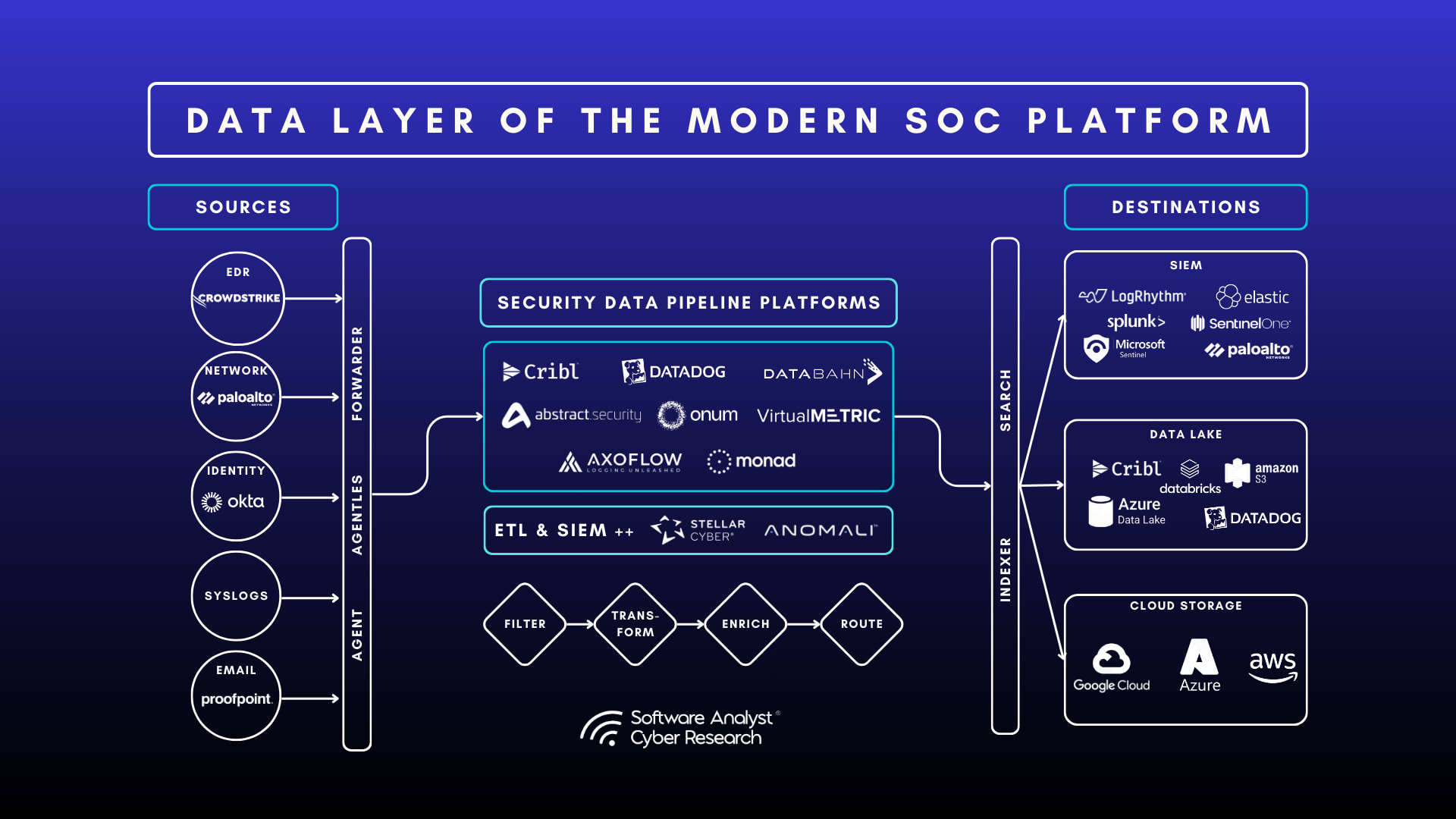
Most mature 2026 stacks do not pick one tool — they layer three. LLM Guard runs first as the cheap broad scanner (PII, injection, toxicity) on every request. NeMo Guardrails enforces dialogue and tool-execution policy and routes a subset to a content-safety model. Guardrails AI validates the final structured output against your schema. Llama Guard 4 (or NemoGuard) is the classifier you plug into the NeMo content-safety rail. Each layer covers another’s blind spot.
LLM guardrails compared: features, latency, and best fit
The four tools sort cleanly by job: LLM Guard for broad scanning, NeMo for dialogue and tool policy, Guardrails AI for structured-output validation, and Llama Guard 4 for multimodal content classification. The table and scorecards below summarize how they line up across the dimensions that actually decide a deployment. Read latency and accuracy figures as directional 2026 snapshots — they shift with releases and collapse under adversarial load.
NeMo Guardrails
Best for: Agents and chatbots needing programmable, deterministic conversation and tool gating
What works
Watch out for
Guardrails AI
Best for: Apps that must return validated, typed structured data from an LLM
What works
Watch out for
Llama Guard 4
Best for: Multimodal content moderation against the MLCommons hazard taxonomy
What works
Watch out for
LLM Guard
Best for: A self-hosted, vendor-free first line of defense on inputs and outputs
What works
Watch out for
| Tool | Type | Core strength | Latency | Key limitation |
|---|---|---|---|---|
| NeMo Guardrails | Programmable runtime | 5 rail types, Colang dialogue and tool policy | Sub-50ms with parallel/speculative rails | Colang learning curve; bundled classifier mid-pack (~0.793 F1 OpenAI Mod) |
| Guardrails AI | Validation framework | 60+ validators, structured-output enforcement | Validator-dependent; competitor-check is fast | Quality tool, not adversarial security |
| Llama Guard 4 | Safety classifier model | Multimodal, 14 MLCommons hazard categories | ~0.459s per call (12B model) | Drops to ~0.80 F1 under jailbreak; weak long-context |
| LLM Guard | Scanner library | ~15 input + 20 output scanners, PII anonymize | Variable, self-hosted | Less sophisticated per-scanner; self-maintained |
How to choose and route LLM guardrails by use case
There is no single best LLM guardrail — there is a best layer for each job
Route by the job, not the brand: scan everything cheaply with LLM Guard, govern dialogue and tools with NeMo Guardrails, validate structured output with Guardrails AI, and classify multimodal content with Llama Guard 4 plugged in as a rail. Almost every serious 2026 deployment ends up combining at least two of these, because their failure modes are complementary rather than redundant.
If you are building a customer-facing agent that calls tools and must stay on-topic, NeMo is your backbone — its execution and dialog rails are the only ones here that gate tool calls. If you are building a data-extraction or function-calling service where the output must always be valid typed JSON, lead with Guardrails AI. If you moderate user-generated or model-generated content, especially images, Llama Guard 4 is the classifier — but run it on a sampled or risk-routed subset, not every request, given its latency. And on every path, regardless of stack, put LLM Guard at the front for the cheap broad sweep.
Two decisions matter more than tool choice. First, latency budget: a 459ms classifier on every input is a tax you pay forever, so measure the guardrail layer against your token-generation latency, not the leaderboard. Second, adversarial testing: every tool here posts good clean-data numbers and worse jailbreak numbers, so the value of your LLM guardrails is set by how often you red-team them, not by which logo you chose. Static defenses rot; the threat landscape does not wait.
“The value of your LLM guardrails is set by how often you red-team them, not by which logo you chose.”
Surya Koritala, founder of Cyntr
Builder’s take
I run Cyntr, an agent-orchestration runtime, and at Loomfeed we moderate a firehose of model-generated discussion content. I have learned the expensive way that there is no single guardrail that does everything, and the teams that pick one tool and call it ‘safety’ are the ones who get burned first.
- Treat guardrails as a pipeline, not a product. In Cyntr I run a cheap broad scanner on every input first, then route a smaller slice to a heavier classifier. Putting Llama Guard 4 in front of every request would have doubled my p95 latency for almost no marginal catch rate.
- Budget for latency before accuracy. A 459ms classifier on the input path is a tax you pay on every single call. I size the guardrail layer against my token-generation latency, not against the benchmark leaderboard.
- Distrust clean-data benchmarks. The numbers that matter are jailbreak-bench and long-context F1, where every tool here degrades. I red-team my own rails on a schedule because a static rail rots.
- Keep structured-output enforcement separate from safety. Guardrails AI catches a malformed JSON schema; it will not catch a prompt injection. Conflating the two is how teams ship a ‘validated’ response that is also a data-exfil vector.
Frequently asked questions
NeMo Guardrails is a programmable runtime that orchestrates five rail types (input, dialog, retrieval, execution, output) using the Colang DSL to control conversation flow and tool calls. Llama Guard 4 is a single 12B classifier model that scores text and images as safe or unsafe against 14 hazard categories. They are complementary: Llama Guard is the kind of model you plug into NeMo’s content-safety rail.
Yes, all four are open-source. NeMo Guardrails (NVIDIA), Guardrails AI, Llama Guard 4 (Meta), and LLM Guard (Protect AI) can be self-hosted at no license cost. You still pay for compute — Llama Guard 4 needs roughly 24GB of VRAM, and any classifier on the request path adds latency you should budget for.
No single tool fully solves prompt injection in 2026. LLM Guard has dedicated injection and jailbreak scanners for a broad first pass, and Meta’s Prompt Guard 2 (86M/22M) pairs with Llama Guard for focused detection. Even the strongest classifiers degrade under adversarial pressure, so combine a scanner with regular red-teaming rather than trusting one detector.
Colang is the event-driven, domain-specific language NeMo Guardrails uses to define dialogue rails as code, interpreted by a Python runtime. Colang 1.0 is the production default; Colang 2.0 exists but its public runtime has been treated as unstable, so most teams stay on 1.0. It offers fine-grained flow control at the cost of a steep learning curve.
The Guardrails Hub offers well over 60 reusable validators as of 2026, with counts cited between roughly 60 and 70+ because the hub grows continuously. They cover PII detection, toxicity, competitor mentions, SQL injection, schema/format enforcement, and more, and you compose them into input and output Guards around an LLM call.
Yes, and most mature deployments do. A common 2026 pattern runs LLM Guard as a cheap broad scanner on every request, NeMo Guardrails for dialogue and tool-execution policy, and Guardrails AI to validate structured output, with Llama Guard 4 or NemoGuard as the content classifier inside a NeMo rail. Layering tools whose blind spots differ gives far better coverage than any single guardrail.
Primary sources
- NeMo Guardrails GitHub releases — NVIDIA
- Guardrails Process — five rail types — NVIDIA
- Welcoming Llama Guard 4 on Hugging Face Hub — Hugging Face
- Guardrails AI on GitHub — Guardrails AI
- LLM Guard — Protect AI
- Best AI Guardrails in 2026 — General Analysis
- Introducing the AI Guardrails Index — Guardrails AI
Last updated: May 31, 2026. Related: Observability.




