


A vendor-neutral ranking of the five frameworks that matter in 2026, with the one number nobody publishes: real all-in cost per minute and the volume tier where self-hosting beats buying.
What is the best voice AI agent framework in 2026?
There is no single best voice AI agent framework in 2026 — there is a best framework for your call volume. If you are running under roughly 10,000 minutes per month and need to launch in weeks, a managed platform like Vapi or Retell is the best voice AI agent framework for you. If you are above ~50,000 minutes per month, or you need sub-500ms latency, HIPAA/SOC2 control, and full observability, an open-source framework like LiveKit Agents or Pipecat will cut your bill by up to 80% and is the better long-term choice.
Almost every comparison you will find ranking the “best voice AI agent framework 2026” is published by a company that sells one of the components — an STT vendor, a TTS vendor, an eval vendor, or a media platform. Those rankings quietly steer you toward whatever the publisher monetizes. This ranking does the opposite: it is vendor-neutral, it names real prices, and it leads with the one number buyers actually need — all-in cost per minute at a given volume tier, plus latency to first audio.
We compared five frameworks that genuinely matter for production voice agents this year: Vapi, Retell, LiveKit Agents, Pipecat, and the TEN Framework. The fault line that organizes everything is build versus buy. Managed platforms (Vapi, Retell) charge a platform fee and abstract telephony; open-source frameworks (LiveKit, Pipecat, TEN) are free to use and you pay only for the AI services plus your own hosting.

Across the credible 2026 analyses, the build-vs-buy crossover lands between ~10K and ~50K minutes/month. Below it, managed wins on total cost of ownership; above it, self-hosting saves up to 80%. Everything else in this ranking is a tie-breaker around that line.
Vapi vs LiveKit vs Pipecat: the ranked comparison table
For most developers in 2026, the ranking is LiveKit Agents #1 for production self-hosting, Pipecat #2 for pipeline control, Vapi #3 for fastest launch, Retell #4 for telephony-first teams, and TEN #5 for multimodal/avatar use cases. The table below is the vendor-neutral view: license, hosting model, telephony, integration breadth, pricing model, and who each one is actually for.
Read the pricing column carefully. Vapi and Retell charge a per-minute platform fee on top of the STT, LLM, TTS, and telephony you pass through — so the advertised $0.05–$0.07/min is never your real cost. LiveKit, Pipecat, and TEN charge nothing for the framework itself; you pay only AI services and hosting. That single distinction is what flips at scale.
LiveKit Agents
Best for: Latency-sensitive, WebRTC-first production deployments at scale
What works
Watch out for
Pipecat
Best for: Teams that want full pipeline control and the widest service choice
What works
Watch out for
Vapi
Best for: Small teams, prototyping, telephony-heavy launches under 10K min/month
What works
Watch out for
Retell AI
Best for: Telephony-first teams wanting managed simplicity without a platform surcharge
What works
Watch out for
TEN Framework
Best for: Multimodal and avatar-driven ‘wow’ demos and full-duplex agents
What works
Watch out for
| Framework | License / model | Self-host vs managed | Telephony | Integrations | Pricing model | Best for |
|---|---|---|---|---|---|---|
| LiveKit Agents | Open source (Apache-2.0) + managed cloud | Both | Native SIP + Twilio | Plugins: OpenAI, Deepgram, ElevenLabs, Cartesia, Silero | Pay AI + hosting only (cloud optional) | WebRTC-native, latency-sensitive production |
| Pipecat | Open source (BSD-2) by Daily | Self-host (Pipecat Cloud optional) | Twilio / SIP via transport | 60+ service integrations | Pay AI + hosting only | Full Python pipeline control |
| Vapi | Managed platform | Managed only | Built-in (abstracted) | Configurable providers | Platform fee (~$0.05/min) + passthrough | Fastest launch, prototyping |
| Retell AI | Managed platform | Managed only | Built-in (abstracted) | Configurable providers | Per-minute (~$0.07/min) + passthrough | Telephony-first, no platform fee |
| TEN Framework | Open source (MIT) | Self-host | Via extensions | Graph-based extensions; avatar (HeyGen/Tavus) | Pay AI + hosting only | Multimodal, vision, lip-sync avatars |
Build vs buy voice AI agent: where does self-hosting win?
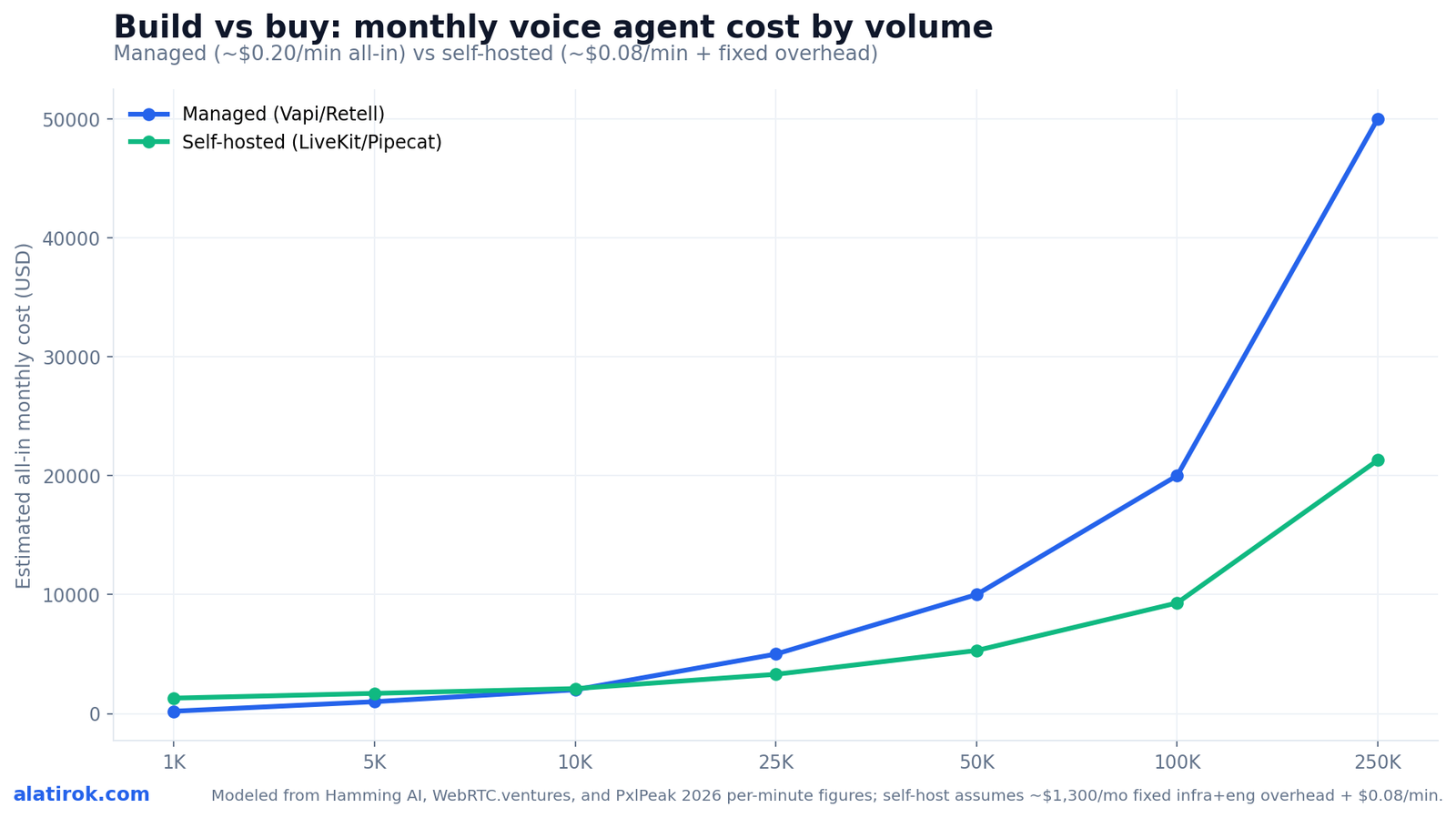
Self-hosting LiveKit or Pipecat overtakes buying Vapi or Retell somewhere between 10K and 50K minutes per month, after which self-hosting saves up to 80% on per-minute cost. The reason is structure, not magic: managed platforms add a per-minute margin on top of the same STT/LLM/TTS you would pay for anyway, while a self-hosted stack carries a roughly fixed monthly overhead (infra plus a slice of engineering time) that gets cheaper per minute the more you run.
Using the verified 2026 figures — managed all-in around $0.20/min (Vapi lands $0.15–$0.40, Retell $0.13–$0.31) versus a self-hosted component cost of roughly $0.08/min plus fixed overhead — the chart below models total monthly spend across volume tiers. The crossover band is shaded: below it, the fixed cost of running your own stack is not yet amortized; above it, the managed margin compounds against you.
Two caveats keep this honest. First, the self-host line includes infrastructure and a conservative slice of engineering time; if your team has no voice engineers, that line shifts up and the crossover moves right. Second, telephony on LiveKit/Pipecat is your integration to build — budget that one-time cost. Neither caveat changes the shape: at volume, owning the stack wins decisively.
Pros
Cons
Open source voice AI agent framework: LiveKit vs Pipecat vs TEN
Among open-source voice AI agent frameworks in 2026, choose LiveKit Agents for WebRTC-native production, Pipecat for maximum Python pipeline control, and TEN for multimodal or avatar-driven agents. All three are free to use, all three are production-capable, and the choice comes down to your transport, your language, and whether voice is the whole product or just one modality.
LiveKit started as real-time media infrastructure, so its Agents layer is the most natural fit when you need WebRTC, multi-participant rooms, or SIP at production latency. It recently added structured workflow capabilities — explicit tool definitions, controlled execution paths, and deterministic branching — which closes much of the orchestration gap that used to push teams toward managed platforms.
Pipecat, created by Daily, models a conversation as a pipeline of frame processors: audio frames flow in, pass through STT, LLM, and TTS stages, and audio flows back out. That abstraction is the reason Pipecat is the favorite of teams who want to own every frame and swap any component. With 60+ integrations and a v1.x line shipped in 2026, it has the widest service choice of any framework here.
TEN (Transformative Extensions Network) is the youngest of the three and the most ambitious about modality. Its graph-based architecture runs audio, video, and data extensions in parallel as nodes in a directed graph, and it ships its own turn-detection model and lightweight VAD for natural full-duplex dialogue. If you want a talking, lip-synced avatar more than a phone agent, TEN is the pick.
“The framework war is really a transport-and-volume decision wearing a feature-comparison costume.”
Alatirok editorial
LiveKit alternatives 2026 and Pipecat alternatives: what else to consider
The strongest LiveKit alternatives in 2026 are Pipecat (for Python pipeline control) and TEN (for multimodal), while the strongest Pipecat alternatives are LiveKit Agents (for WebRTC/SIP) and managed platforms Vapi/Retell (for speed). Which alternative fits depends entirely on what you found limiting in the first place.
If you hit LiveKit’s learning curve or you do not need WebRTC’s multi-participant model, Pipecat’s single-pipeline mental model is simpler to reason about for a one-to-one voice agent. If you found Pipecat’s self-assembly burdensome and you want media and telephony handled for you, LiveKit’s managed cloud — or jumping to Vapi/Retell entirely — removes that work. And if either felt too voice-only, TEN’s parallel extension graph is built for vision and avatars from the start.
There is also a build-vs-buy alternative hiding in plain sight: if your volume sits below the crossover and you are burning engineering time fighting any open-source framework, the rational “alternative” is a managed platform. Buying is not a defeat at low volume; it is the cheaper total cost of ownership. Revisit self-hosting when your minutes cross the line.
Pick a framework that lets you keep your STT/LLM/TTS providers portable. LiveKit and Pipecat both abstract providers behind plugins, so moving from one to the other — or off a managed platform — is mostly a transport rewrite, not a model rewrite.
Best voice agent framework for developers: latency and telephony
For developers, the best voice agent framework is the one that gives you control over endpointing and telephony, because those two factors — not raw model speed — decide whether your agent feels human. The production target most teams converge on in 2026 is P50 under ~400ms and P95 under ~800ms to first audio, with a component budget of roughly 80–120ms STT, 150–250ms LLM first-token, 60–100ms TTS first-chunk, and 20–60ms transport.
Endpointing — how long the agent waits before deciding you have finished speaking — is where frameworks diverge most. Reported defaults put Pipecat around 300ms, Retell around 700ms, and Vapi around 1450ms. LiveKit’s built-in semantic turn detection claims sub-75ms P99 on the turn decision itself. That spread is the single biggest reason two agents on identical models can feel completely different: one interrupts naturally, the other leaves dead air.
Telephony is the other developer reality check. Vapi and Retell abstract SIP/Twilio entirely — you never touch transport. LiveKit offers native SIP and Twilio integration; Pipecat handles it through its transport layer; TEN does it via extensions. The “free” frameworks are free in license but not in integration time, and that time belongs in your decision. Here is a minimal LiveKit Agents entrypoint that shows how little code production voice now takes.
from livekit.agents import Agent, AgentSession, JobContext, WorkerOptions, cli
from livekit.plugins import openai, deepgram, cartesia, silero
class SupportAgent(Agent):
def __init__(self):
super().__init__(
instructions="You are a concise, friendly phone support agent."
)
async def entrypoint(ctx: JobContext):
await ctx.connect()
session = AgentSession(
# Tune endpointing to taste — this is where 'human' is won or lost.
stt=deepgram.STT(model="nova-3"),
llm=openai.LLM(model="gpt-5.1-mini"),
tts=cartesia.TTS(voice="sonic-english"),
vad=silero.VAD.load(),
turn_detection="semantic", # built-in, sub-75ms P99 turn decision
)
await session.start(agent=SupportAgent(), room=ctx.room)
await session.generate_reply(instructions="Greet the caller and ask how you can help.")
if __name__ == "__main__":
cli.run_app(WorkerOptions(entrypoint_fnc=entrypoint))Voice agent stack 2026: our final verdict
LiveKit #1 for production, Pipecat #2 for control, Vapi #3 for speed
The best voice AI agent framework in 2026 is LiveKit Agents for production self-hosting and Pipecat for maximum control — but only above the ~10K–50K min/month crossover; below it, Vapi or Retell is the cheaper, faster choice. The honest answer is that “best” is a function of volume, latency needs, and whether you have voice engineers, and any ranking that ignores those variables is selling you something.
Concretely: validate your voice UX on a managed platform if you are early or small. Move to LiveKit or Pipecat when your minutes cross the line, you need sub-500ms latency, or compliance forces you to own the stack. Reach for TEN when voice is only one modality and avatars or vision matter. That sequence beats every vendor-slanted ranking because it optimizes your total cost of ownership instead of someone else’s product page.
Builder’s take
I have shipped voice and real-time agents on both managed platforms and self-hosted stacks, and the framework debate almost always collapses into one variable that the vendor blog posts bury on purpose.
- Pick the framework by your call volume, not by the demo. Under ~10K minutes/month, managed (Vapi/Retell) wins on total cost of ownership once you price an engineer’s time. Above ~50K, self-hosting LiveKit or Pipecat is the obvious call.
- Latency is a feature, not a benchmark. The frameworks that let you control endpointing (Pipecat ~300ms default VAD vs Vapi ~1450ms) feel dramatically more human even at identical model latency.
- Telephony is where ‘free’ frameworks quietly cost money. LiveKit and Pipecat make you wire up SIP/Twilio yourself; that integration time is real and belongs in your build-vs-buy math.
- Do not over-index on integration counts. Sixty connectors mean nothing if you only need Deepgram plus one LLM plus Cartesia. Optimize for the path you will actually ship.
Frequently asked questions
It depends on your call volume. Below ~10K minutes/month, managed platforms Vapi or Retell are the best choice for fast launch and lowest total cost of ownership. Above ~50K minutes/month, open-source LiveKit Agents or Pipecat are best, cutting per-minute cost by up to 80% while giving you latency and compliance control.
At low volume Vapi is effectively cheaper because LiveKit’s self-hosting overhead is not yet amortized. At high volume LiveKit is far cheaper: Vapi’s real all-in cost runs $0.15–$0.40/min including its platform fee, while a self-hosted LiveKit stack costs roughly $0.08/min plus fixed infra. The crossover is around 10K–50K minutes/month.
LiveKit Agents and Pipecat are the two strongest open-source frameworks in 2026. LiveKit is WebRTC-native and best for low-latency production with SIP/telephony; Pipecat (by Daily) offers the widest service choice with 60+ integrations and total Python pipeline control. TEN is the best open-source choice for multimodal and avatar use cases.
Buy (Vapi/Retell) when you need to launch in under a month, handle under ~10K minutes/month, or lack voice engineers. Build (LiveKit/Pipecat) when you exceed ~10K–50K minutes/month, need sub-500ms latency, require HIPAA/SOC2 control, or want full observability. Self-hosting saves up to 80% at scale.
The top LiveKit alternatives are Pipecat for simpler single-pipeline Python control, TEN Framework for multimodal and avatar agents, and managed platforms Vapi or Retell if you want telephony and media handled for you and your volume is below the build-vs-buy crossover.
Aim for P50 under ~400ms and P95 under ~800ms to first audio. A typical budget is 80–120ms STT, 150–250ms LLM first-token, 60–100ms TTS first-chunk, and 20–60ms transport. Tuning endpointing matters most: defaults range from ~300ms on Pipecat to ~1450ms on Vapi.
Primary sources
- Vapi vs Pipecat vs LiveKit framework comparison — AssemblyAI
- Choosing a Voice AI Agent Production Framework — WebRTC.ventures
- Best Voice Agent Stack: A Complete Selection Framework — Hamming AI
- Vapi Pricing 2026 breakdown — PxlPeak
- Retell AI Review and Pricing 2026 — Retell AI
- Pipecat open-source framework — GitHub / Pipecat AI
- LiveKit Agents framework — GitHub / LiveKit
- TEN Framework for conversational voice AI — GitHub / TEN Framework
- LiveKit Alternatives in 2026 — FutureAGI
Last updated: June 6, 2026. Related: Agent Infrastructure.




