


We pulled the real, peer-reviewed and vendor-disclosed numbers on how much electricity, water, and carbon a single AI query consumes in 2026 — and where the data still goes dark.
What is the AI energy footprint of a single query in 2026?
A typical text query to a frontier model costs about 0.24 to 0.3 watt-hours of electricity and a fraction of a milliliter of water in 2026 — roughly the energy of running an LED bulb for a couple of minutes, or watching TV for under ten seconds. That is the convergent answer from the two most credible recent estimates: Epoch AI’s February 2025 analysis put a median GPT-4o query at about 0.3 Wh, and Google’s August 2025 technical disclosure measured the median Gemini Apps text prompt at 0.24 Wh, 0.26 mL of water, and 0.03 grams of CO2-equivalent.
These numbers are an order of magnitude lower than the figures that went viral in 2023, when an early estimate of roughly 3 Wh per ChatGPT query — and a widely repeated claim of a 500 mL water bottle per conversation — set the public narrative. Both have since been revised down by 90% or more as hardware improved (NVIDIA’s H100 generation displaced the A100), inference stacks were optimized, and the labs started measuring their own systems instead of relying on outside back-of-envelope math.
But ‘a single query’ is doing a lot of work in that sentence. The honest version of the AI energy footprint is a distribution, not a point. The same provider’s number swings by 10x or more depending on the model size, the length of the input, whether the model ‘reasons’ before answering, and whether you are generating text, an image, or a five-second video. The next sections break each of those down with the underlying figures.

Median text prompt in 2026: ~0.24-0.3 Wh and well under 1 mL of water. The ‘bottle of water per chat’ claim was based on 2023 training-era math and is not how a modern single query behaves.
Energy per AI query across model sizes and task types
The energy per query is not one number — it ranges from about 0.03 Wh for a small text model to nearly 1 Wh for a large one, and explodes to hundreds or thousands of watt-hours for high-quality video generation. MIT Technology Review’s May 2025 investigation is the most granular open measurement, run on open-weight Llama and Stable Diffusion models so the numbers could actually be verified end to end.
On their measurements, a small 8-billion-parameter text model used about 114 joules total per response (~0.032 Wh), while a 405-billion-parameter model used about 6,706 joules (~1.86 Wh) — a ~58x spread for the same prompt, driven almost entirely by model size. Image generation landed at roughly 2,282 joules (~0.63 Wh) for a standard 1024×1024 image, rising to ~4,402 joules (~1.22 Wh) at high quality. Video is in a different universe: a low-quality clip cost about 109,000 joules, and a higher-quality five-second clip about 3.4 million joules (~944 Wh) — thousands of times a text prompt.
Two structural shifts make these per-task numbers misleading if you stop there. First, long context: Epoch AI estimates that a query with 100,000 input tokens can cost around 40 Wh — over 100x a short prompt — because the model has to process every token. Second, reasoning models. The o-series and its peers, now default for hard questions, generate roughly 2.5x more tokens to ‘think,’ and energy scales with tokens. The per-query average fell while the per-hard-answer cost rose.
The chart below puts the real, attributable per-task figures on one axis so you can see the spread that ‘an AI query’ actually hides.
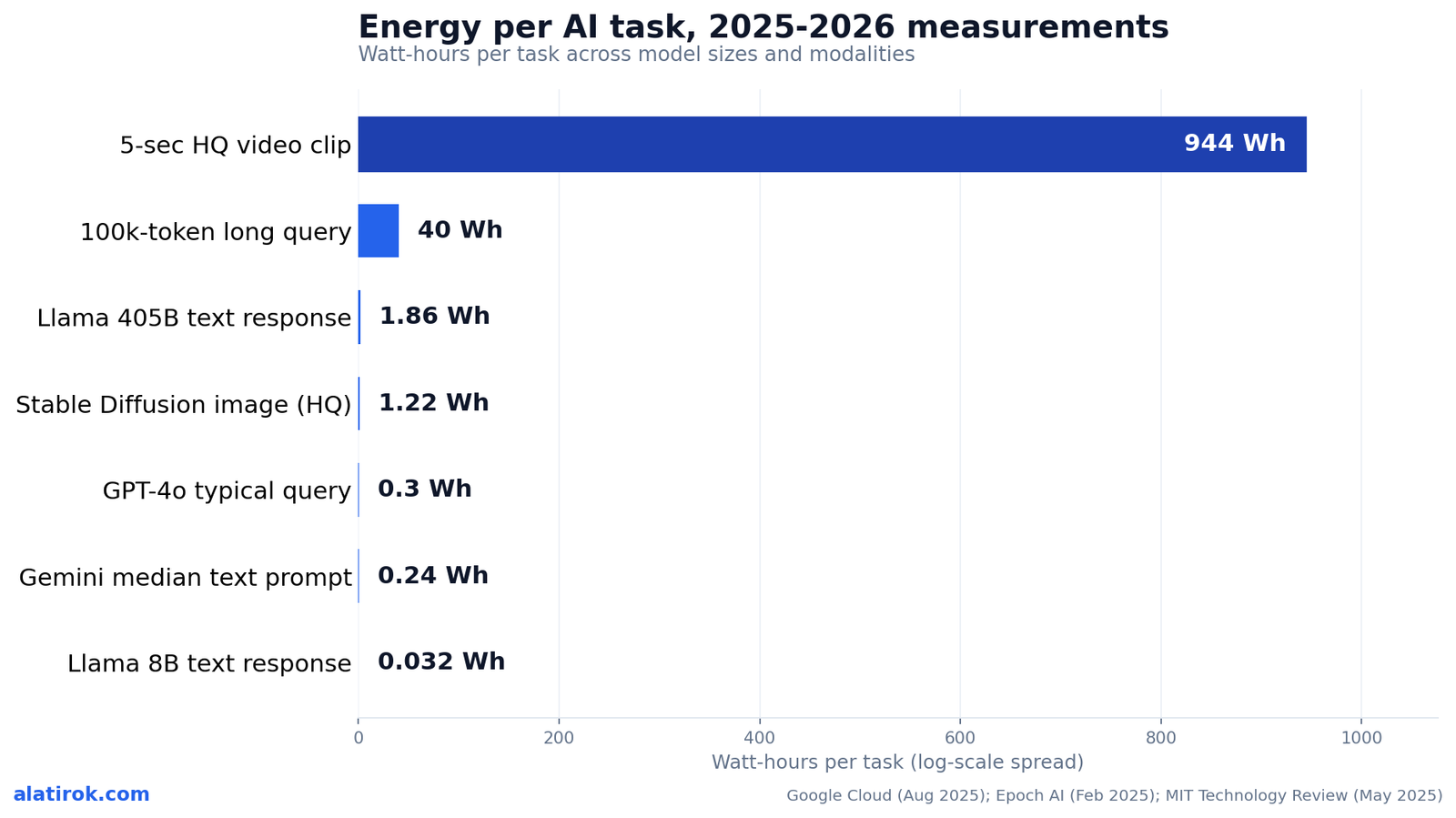
These figures come from different teams using different boundaries. Google’s 0.24 Wh is a full-stack production number; MIT’s Llama figures are controlled measurements on open models. Treat the chart as orders of magnitude, not a leaderboard.
How much water does AI cooling actually use?
0.26 mL
Water per median Gemini text prompt
Google full-stack disclosure, Aug 2025
5.4M L
Total water to train GPT-3 (incl. electricity)
UC Riverside, 2023
1.9 L/kWh
Industry-average water usage effectiveness
vs. ~0.15 L/kWh at AWS
1.09
Google fleet average PUE in 2024
Lower is better; ~1.0 is ideal
A single modern text prompt consumes a fraction of a milliliter of water directly — Google reported 0.26 mL, about five drops, for a median Gemini prompt — but the headline-grabbing numbers come from training and from water-intensive cooling in hot, dry regions. Water enters the AI energy footprint two ways: on-site evaporative cooling at the data center (scope-1), and off-site water consumed generating the electricity the data center draws (scope-2). Most viral figures conflate the two.
The 2023 UC Riverside paper ‘Making AI Less Thirsty’ (Li, Yang, Islam, and Ren) is the origin of the famous water claims, and it is more careful than its viral summaries. It estimated that training GPT-3 in Microsoft’s U.S. data centers consumed about 700,000 liters of on-site freshwater, and roughly 5.4 million liters once electricity-generation water is included. The same paper estimated GPT-3 ‘drinks’ a 500 mL bottle for every 10 to 50 medium responses — a per-query figure that, even at its thirstiest end, is small but far from the near-zero Google now reports for a far more efficient model.
The variable that dominates water is location and cooling design, not the model. Industry water-usage-effectiveness (WUE) averages around 1.9 liters per kWh, but Amazon reports about 0.15 L/kWh, and Microsoft has begun deploying closed-loop, zero-evaporation designs it says will cut over 125 million liters per facility per year, with first sites expected around 2027. A prompt served from a closed-loop Nordic site and the same prompt served from an evaporative-cooled desert site can differ by more than an order of magnitude in water — which is exactly why a single global ‘mL per query’ number is close to meaningless.
“Location and cooling design dominate AI’s water footprint far more than the model does. A single global ‘milliliters per query’ number is close to meaningless.”
On why water is the hardest AI footprint metric to pin down
The sector-wide picture: data center electricity and emissions
Data centers used about 415 TWh of electricity in 2024 — roughly 1.5% of global power — and the IEA projects that doubling to around 945 TWh by 2030 and ~1,200 TWh by 2035, with AI as the primary driver of the growth. This is where the AI energy footprint stops being a rounding error and starts being a grid-planning problem. The per-query number is tiny; the aggregate, multiplied across billions of daily queries and a global build-out of accelerated servers, is not.
The IEA’s 2025 Energy and AI report is the authoritative anchor here. Data center electricity has grown about 12% annually over the last five years and is projected to accelerate to ~15% per year through 2030. Crucially, the AI-specific slice — ‘accelerated servers’ — is projected to grow ~30% annually, versus ~9% for conventional servers. AI was roughly 15% of data center electricity in 2024 by the IEA’s estimate (some research says closer to 20%), and that share could climb to 35-50% by 2030. The United States and China account for nearly 80% of the global growth.
On emissions, the picture is more measured than alarmist coverage suggests. The IEA attributes about 180 megatonnes of indirect CO2 to data centers today — all workloads, not just AI — which is about 0.5% of energy-related combustion emissions. The carbon footprint of AI specifically was estimated at 32.6 to 79.7 million tonnes of CO2 in 2025 in the Patterns (Cell Press) review. The IEA expects data center emissions to reach about 1% of the global total by 2030. Significant, growing fast, and worth governing — but, today, a smaller slice of the climate problem than aviation or steel.
415 TWh in 2024 is about what the entire country of France consumes in a year. The growth — not today’s level — is what makes AI a grid-planning story.
| Metric | 2024 | 2030 (base case) | 2035 (base case) |
|---|---|---|---|
| Data center electricity | ~415 TWh | ~945 TWh | ~1,200 TWh |
| Share of global electricity | ~1.5% | just under 3% | rising |
| AI share of data center power | ~15% | 35-50% | — |
| Annual growth rate | ~12% | ~15%/yr to 2030 | — |
| Data center CO2 share | ~0.5% of combustion | ~1% of global | — |
The disclosure gap: why these numbers stay fuzzy
The biggest problem with the AI energy footprint in 2026 is not that it’s large — it’s that most of it is undisclosed, so nearly every public figure is an estimate built on assumptions the labs could resolve but won’t. MIT Technology Review described closed model providers as serving up ‘a total black box’: OpenAI, Anthropic, and most others treat per-query energy as proprietary, which is why independent researchers have to reverse-engineer numbers from hardware specs, API pricing, and token counts.
Google’s August 2025 technical paper broke that pattern and, in doing so, revealed how much methodology matters. Its comprehensive, full-stack number was 0.24 Wh — but a ‘narrow’ accounting that counted only the active accelerator, ignoring idle provisioned machines, CPU/RAM, data center overhead (PUE), and water, came out at just 0.10 Wh. Same prompt, less than half the footprint, simply by drawing the boundary tighter. Almost every favorable efficiency claim you read uses something closer to the narrow boundary, often without saying so.
This is the governance crux. You cannot regulate, tax, or even rank what you cannot measure consistently. There is no agreed standard for what ‘energy per query’ must include, no required disclosure of region-level WUE, and no audit of the self-reported numbers. Google’s disclosure should be a floor — comprehensive, full-stack, water included — not a one-off PR milestone. Until comparable reporting is mandated, every chart in every article (including this one) carries an asterisk the labs could remove tomorrow.
Pros
Cons
How to shrink your own AI energy footprint
If you build or heavily use AI, the highest-leverage moves are right-sizing the model to the task, capping wasted tokens, and choosing where your inference runs — not abstaining from AI. Because the per-task energy spread is dominated by model size and token count, a builder’s routing decisions matter far more than any single query’s guilt.
The single biggest lever is not calling a 405B model when an 8B model answers correctly — MIT measured roughly a 58x energy gap between the two for the same text prompt. Intent-routing cheaper models for easy queries and reserving frontier reasoning models for genuinely hard ones can cut aggregate energy by an order of magnitude with no quality loss on the easy path. Capping max output tokens, disabling ‘reasoning’ on trivial tasks, caching frequent answers, and batching requests all attack the token count that energy scales with.
On water and carbon, location is the lever you can actually pull. Cloud providers expose region selection; running inference in regions with cleaner grids and closed-loop or low-WUE cooling can change the carbon and water per query by more than an order of magnitude, even for an identical workload. The catch, again, is disclosure — you have to be able to ask your provider for region-level carbon intensity and WUE, and demand it if they can’t answer.
Right-size the model per intent
Route easy queries (classification, extraction, short Q&A) to small or distilled models, and reserve 405B-class or reasoning models for hard tasks. MIT measured a ~58x energy gap between an 8B and a 405B text model on the same prompt — this is the highest-leverage single decision.Cap tokens and reasoning
Energy scales with tokens. Set sane max_output_tokens, turn off chain-of-thought / reasoning modes on trivial tasks (they generate ~2.5x more tokens), and avoid stuffing 100k-token context when 2k will do — a long-context query can cost ~40 Wh vs. ~0.3 Wh.Cache and batch
Cache frequent or identical responses so you pay the energy once. Batch requests to keep accelerators at high utilization, which improves energy-per-useful-output versus idle-heavy serving.Choose the region
Select cloud regions with low grid carbon intensity and low-WUE or closed-loop cooling. The same workload can differ by 10x+ in carbon and water by location. Ask your provider for region-level WUE and carbon intensity; treat ‘we can’t tell you’ as a red flag.Builder’s take
I run inference for a living. Cyntr fires off thousands of model calls a day to assemble its feeds, and Loomfeed routes a steady stream of @loom queries. So when someone asks what my products ‘cost the planet,’ I can’t hand-wave it. Here is how I actually think about the AI energy footprint after reading the 2025-2026 disclosures.
- Per-query panic is mostly misplaced. At 0.24-0.3 Wh, one text prompt is roughly nine seconds of TV. The footprint that matters is aggregate inference at fleet scale, and the lever there is requests-per-task, not guilt per request.
- The single biggest efficiency win I have is not picking a ‘green’ model — it’s not calling a 405B model when an 8B one answers. MIT measured a ~58x gap between small and large text models. Right-sizing the model per intent is the highest-leverage climate decision a builder makes.
- Water is the metric I trust least, because it is the most location-dependent and the least disclosed. The same prompt can be near-zero in a closed-loop Nordic site and meaningfully thirsty in an Arizona evaporative-cooled one. If you care, you ask your provider for region-level WUE — and most still can’t give it to you.
- Reasoning models quietly broke the old math. A model that ‘thinks’ for 2.5x more tokens uses proportionally more energy, and the industry shipped reasoning as a default in 2025. The per-query number went down; the per-answer number for hard questions went up.
- I treat Google’s August 2025 disclosure as the new floor for honesty, not the ceiling. It is the first full-stack number from a frontier lab. Everyone else owes us the same comprehensive accounting — idle machines, overhead, water and all — before we can take ‘we’re efficient’ at face value.
Frequently asked questions
A median text query to a frontier model uses about 0.24 to 0.3 watt-hours of electricity — Google reported 0.24 Wh for a median Gemini Apps prompt and Epoch AI estimated about 0.3 Wh for GPT-4o. That is roughly the energy of running an LED bulb for a minute or two, or watching TV for under ten seconds. Image generation is several times higher, and video generation can be hundreds of times higher.
No — that claim comes from 2023 training-era math, not a modern single query. Google’s August 2025 disclosure measured about 0.26 mL (around five drops) of water per median text prompt. The 500 mL figure originally referred to GPT-3 ‘drinking’ a bottle per 10-50 responses in less efficient 2023 conditions. Water use varies enormously by data center location and cooling design.
The IEA estimated data centers used about 415 TWh in 2024 — roughly 1.5% of global electricity — and projects that to roughly double to about 945 TWh by 2030 and reach about 1,200 TWh by 2035 in its base case. AI is the primary driver: AI-focused ‘accelerated servers’ are projected to grow about 30% per year.
Data centers as a whole account for about 180 megatonnes of CO2 today — roughly 0.5% of energy-related combustion emissions — per the IEA. AI specifically was estimated at 32.6 to 79.7 million tonnes of CO2 in 2025 in a 2025 Patterns (Cell Press) review. The IEA expects data center emissions to reach about 1% of the global total by 2030.
Mostly because of measurement boundaries and disclosure gaps. The same prompt can be reported as 0.10 Wh or 0.24 Wh depending on whether idle machines, CPU/RAM, data center overhead, and water are counted. Most closed labs disclose little or nothing per query, so independent estimates are reverse-engineered from hardware and pricing. There is no agreed standard for what ‘energy per query’ must include.
Right-size the model to the task — MIT measured about a 58x energy gap between a small 8B model and a large 405B model on the same text prompt. Reserve large reasoning models for genuinely hard queries, cap output tokens, avoid unnecessary long context, cache and batch requests, and choose cloud regions with cleaner grids and low-water cooling. Routing decisions matter far more than abstaining from individual queries.
Primary sources
- How much energy does ChatGPT use? — Epoch AI
- Measuring the environmental impact of AI inference — Google Cloud
- We did the math on AI’s energy footprint — MIT Technology Review
- Energy demand from AI — Energy and AI — International Energy Agency
- AI and climate change — Energy and AI — International Energy Agency
- Making AI Less Thirsty: the Secret Water Footprint of AI Models — Li, Yang, Islam, Ren (UC Riverside / UT Arlington)
- The carbon and water footprints of data centers — Patterns (Cell Press)
- In a first, Google has released data on how much energy an AI prompt uses — MIT Technology Review
Last updated: May 31, 2026. Related: Governance.




