


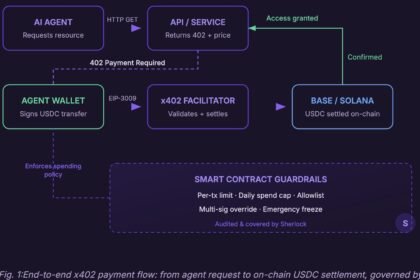
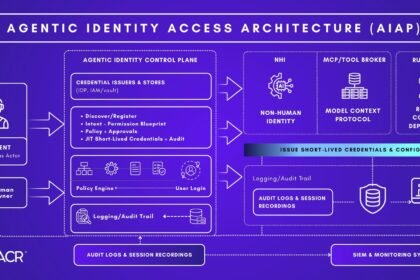



How Much Does It Cost to Build an AI Agent in 2026?
How much does it cost to build an AI agent? In 2026, from $240/year on a no-code tool to $550K…
AI Agent Failure Rate 2026: The Real Data, Reconciled
The AI agent failure rate 2026 is quoted as 40%, 80%, 95% or 89% depending on the source. Here is…
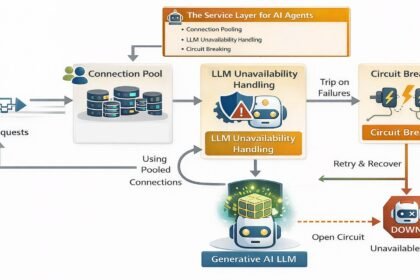
What Is AG-UI Protocol? The Agent-User Interaction Guide
What is AG-UI protocol? A vendor-neutral guide to the agent-user interaction protocol: its ~16 event types, how it differs from…

Verify C2PA Content Credentials in Python: 2026 How-To
Learn to verify C2PA content credentials in Python end-to-end: read the manifest, check validation status, the SHA-256 binding, trust list,…
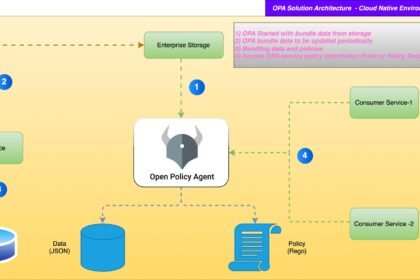
Authorize AI Agent Tool Calls With OPA/Rego (2026)
Authorize AI agent tool calls with OPA Rego: a vendor-neutral Python interceptor plus a copy-paste Rego bundle that allows, denies…

AI Agent Error Rate 2026: Why 95% Per Step Still Fails
The AI agent error rate compounding problem explains why agents fail in production: a 95%-per-step agent over 20 steps succeeds…

Stop AI Agent Calling Tools With Wrong Arguments: A Fix Guide
To stop your AI agent calling tools with wrong arguments, first split the failure into selection vs usage hallucination. Each…
Self-Host LLM Observability With OpenTelemetry in 2026
Learn to self-host LLM observability with OpenTelemetry: a free Grafana LGTM stack, agent trace instrumentation, and Collector-side prompt PII redaction.
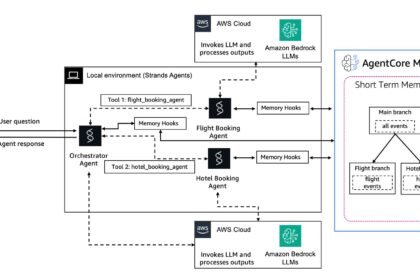
Deploy an AI Agent to AWS Bedrock AgentCore: 2026 CLI Guide
Learn how to deploy an AI agent to AWS Bedrock AgentCore using the new 2026 CLI: four commands, real cost…

