

A decision-ordered diagnostic for the four root causes of agent loops, with a copy-pasteable duplicate-call detector, per-error-class retry budgets, and why max_turns alone is not enough.
Why does my AI agent keep looping?
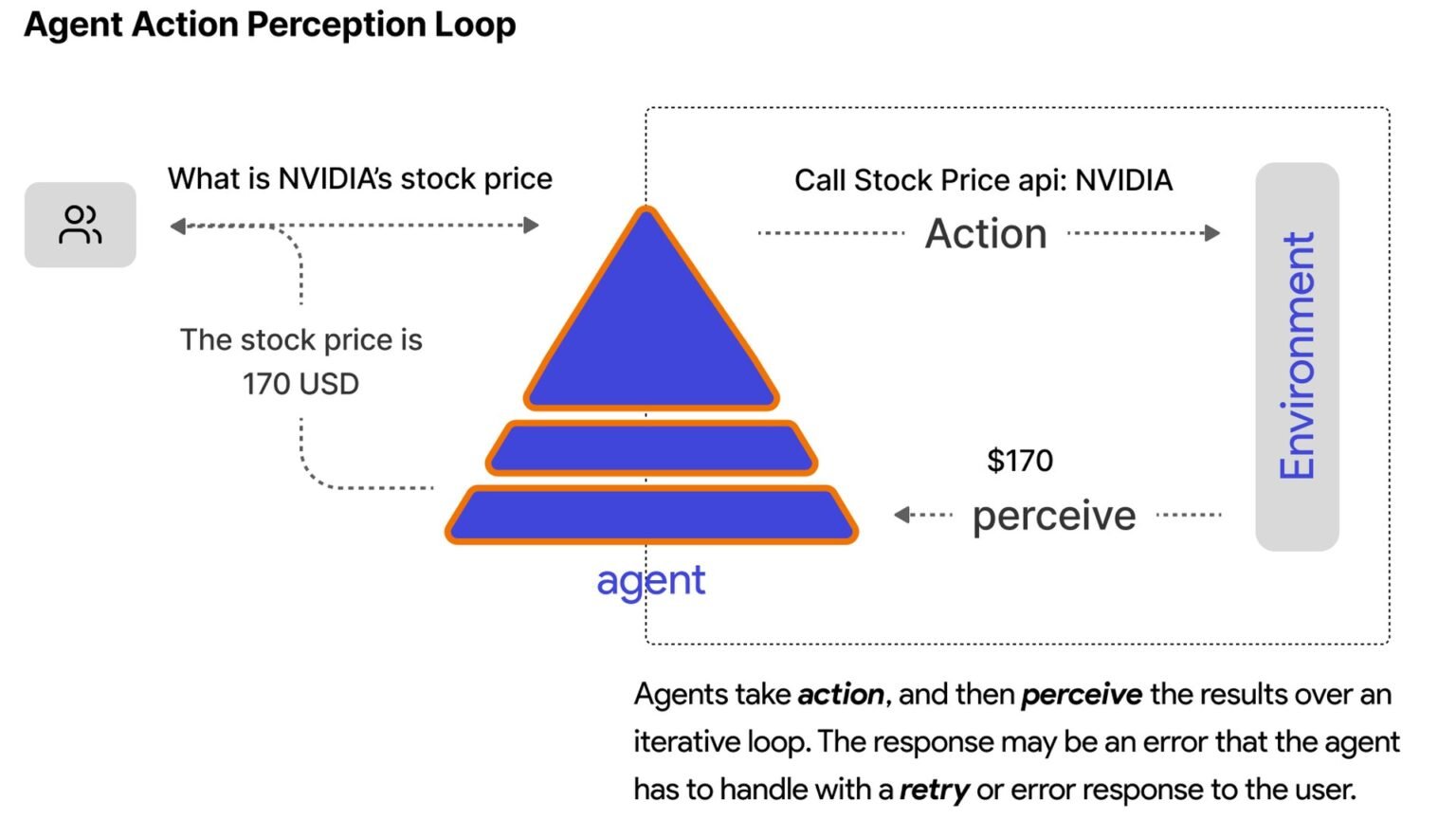
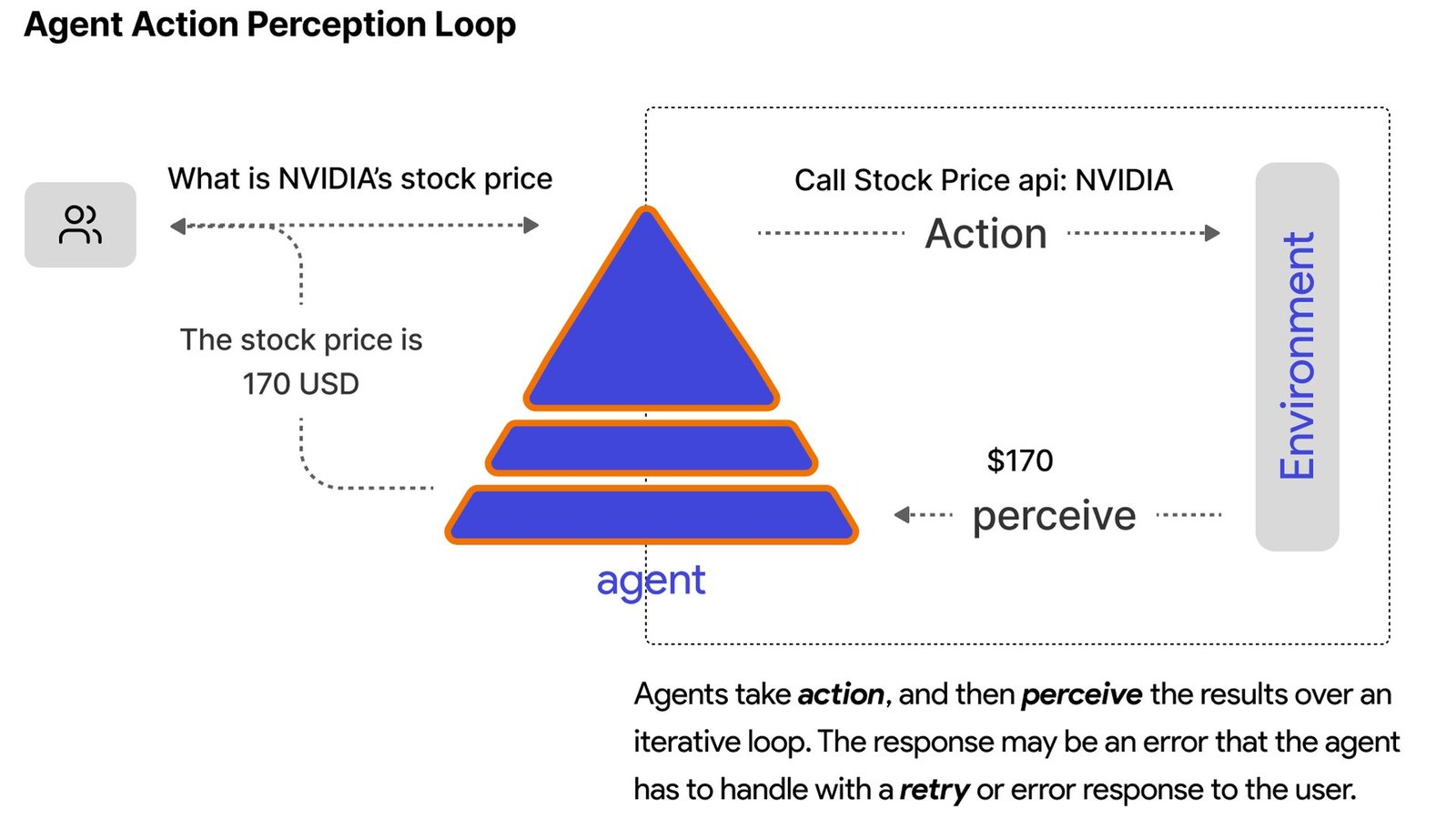
Your AI agent keeps looping because it never receives a machine-readable signal that the task is done, so it interprets every ambiguous tool result as a reason to try again. The loop is not the model being ‘dumb’ — it is the harness failing to give the model a stop condition it can parse. In production this shows up as the same tool being called with the same arguments dozens of times in a row, burning tokens and budget until a turn cap finally kills the run. So why does my AI agent keep looping? Almost always because the success condition is never made explicit to the model.
Unlike a traditional infinite loop, which is a clear logical error in your code, an agent loop is a probabilistic misread. The LLM is choosing the next action one token at a time, and if the world it can see has not visibly changed — no success flag, no terminal status, no new information — the most likely next action is often the same action it just took. That is the whole bug in one sentence.
This article gives you the diagnostic that every other ranking page skips. Instead of ‘set max_turns and pray,’ you get the four root causes mapped to four specific fixes, a copy-pasteable duplicate-call detector with an exact 3-repeat threshold, a retry-budget table keyed to HTTP error class, and the typed tool-result enum that kills the most common loop of all. Work the four causes in order and you will find yours.
The four root causes of an AI agent stuck in a loop
Almost every agent loop in production traces to one of four root causes: missing completion states, retry amplification across layers, unmapped failure classes treated as transient, or non-idempotent side effects. Diagnose them in that order — completion states first, because they cause the majority of loops and are the cheapest to fix.
MatrixTrak’s production teardown of looping agents names these same four mechanisms, and the AWS engineering write-up on DEV Community confirms the first one is by far the most common. Here is what each looks like in a live trace, and which fix section to jump to.
Cause 1, missing completion states: your tool returns prose like ‘Found 3 results, more may be available’ instead of a status field the model can branch on. The agent has no parsable ‘done,’ so it keeps searching. Fix: typed tool results (section below).
Cause 2, retry amplification: you have retries in your HTTP client, again in your tool wrapper, and again in your agent policy. A single permanent failure becomes 2 x 2 x 2 = 8 attempts, and to the agent it looks like the environment is flaky rather than broken. Fix: one retry owner with a per-error-class budget.
Cause 3, unmapped failure classes: every error — including auth, validation, and permission denials — is treated as transient and retried. Those are stop conditions, not retry events; no number of retries will fix a 403. Fix: the retry-budget table.
Cause 4, non-idempotent side effects: the looping tool actually does something each time — sends an email, charges a card, files a ticket. Now the loop is not just wasting tokens, it is duplicating real-world actions. Fix: idempotency keys plus the duplicate-call detector.
Roughly four out of five loops we have triaged are cause #1 (missing completion states) or cause #3 (unmapped failure classes). Check those two before you touch your prompt or your model choice.
| Root cause | What you see in the trace | The fix |
|---|---|---|
| Missing completion states | Same tool, same args, result text is ambiguous (‘more may be available’) | Typed tool results with a status enum |
| Retry amplification | Bursts of identical calls; retries stacked in HTTP + wrapper + policy | Single retry owner, one budget per error class |
| Unmapped failure classes | Endless retries on 401/403/422 that can never succeed | Retry-budget table: stop on auth/validation/permission |
| Non-idempotent side effects | Duplicate emails, charges, or tickets on each repeat | Idempotency keys + duplicate-call fingerprint detector |
How do I detect when my AI agent is repeating the same tool call?
Detect a loop by fingerprinting each step as a hash of the last tool name plus its result, and trip a circuit breaker when the same fingerprint repeats 3 or more times. This is purely pattern-based — no LLM judgment, no heuristics about ‘progress’ — which makes it reliable enough to run in your hot path.
MatrixTrak’s production approach is exactly this: track last_tool + last_result_hash, and when that fingerprint repeats past a threshold of three, you have a confirmed loop. Three is the right number because two repeats can be legitimate (a retry after a transient blip), but a third identical (tool, result) pair means the agent has learned nothing and the environment has not changed. Here is a drop-in detector you can wire into a PreToolUse hook or wrap around your own tool dispatcher.
The detector below is deliberately stateless about the model’s reasoning. It does not try to decide whether the agent is ‘making progress’ — it only asks whether this exact (tool, result) pair has now happened three times. That is the whole point: the agent’s own narration about why it is retrying is the unreliable part, so we ignore it and watch behavior instead.
Do not silently drop the call. Return the BLOCKED message as the tool result so the model sees it in context. Agents recover well from an explicit ‘you already tried this, change approach’ — far better than from a hard exception that just ends the run.
import hashlib
from collections import Counter
class LoopDetector:
"""Trips when the same (tool, result) fingerprint repeats >= 3 times."""
def __init__(self, threshold: int = 3):
self.threshold = threshold
self.counts: Counter[str] = Counter()
self.iteration = 0
@staticmethod
def _fingerprint(tool: str, result: str) -> str:
# Hash tool name + result so identical (call, outcome) pairs collide.
# Note: fingerprint the RESULT, not the args -- two different argument
# sets that both return "no_results" are still the same dead end.
raw = f"{tool}::{result}".encode()
return hashlib.sha256(raw).hexdigest()[:16]
def check(self, tool: str, result: str) -> dict:
self.iteration += 1
fp = self._fingerprint(tool, result)
self.counts[fp] += 1
repeats = self.counts[fp]
looping = repeats >= self.threshold
return {
"loop_iteration": self.iteration,
"last_tool": tool,
"last_result_hash": fp,
"tool_calls_count": self.iteration,
"repeats": repeats,
"decision": "BREAK_LOOP" if looping else "continue",
}
# Usage inside your tool-dispatch loop:
detector = LoopDetector(threshold=3)
def on_tool_result(tool_name: str, result_text: str):
verdict = detector.check(tool_name, result_text)
log.info("agent_step", **verdict) # structured, one line per step
if verdict["decision"] == "BREAK_LOOP":
# Feed this back to the model as the tool result so it changes course.
return (
"BLOCKED: This exact tool call has produced the same result "
f"{verdict['repeats']} times. Do not call {tool_name} again with "
"the same approach. Either change strategy or report that you "
"cannot complete the task."
)
return result_textWhat retry budget should I set for each error class?
Set retries by error class, not a single global number: 0 retries for validation, auth, and permission errors; 3 retries with exponential backoff and jitter for rate limits (HTTP 429); 2 retries then escalate for transient 5xx and timeouts. The single biggest cause of retry loops is treating a permanent error as if it were transient.
This is the rule that the generic ‘just add retries’ advice gets dangerously wrong. A 401 or a 422 will return the identical error on attempt number fifty — retrying it is the loop. MatrixTrak’s framework codifies the budgets below, and pairing them with the duplicate-call detector above gives you defense in depth: the budget stops most retry storms at the source, and the fingerprint detector catches anything that slips through (including loops that are not even retry-driven).
Critically, this budget must live in exactly one layer. If your HTTP library retries 5xx three times, and your tool wrapper retries twice on top of that, you have not set a budget of 2 — you have set a budget of 8, and the agent sees a world that looks intermittently broken. Pick one owner for retries (we recommend the tool wrapper, where you know the error class) and disable retries everywhere else.
import random, time
# Map each error class to its budget. Stop-classes get 0 retries by design.
RETRY_BUDGET = {
"validation": {"retries": 0},
"auth": {"retries": 0},
"permission": {"retries": 0},
"rate_limit": {"retries": 3}, # 429
"transient": {"retries": 2}, # 5xx / timeout
}
def classify(status: int) -> str:
if status in (400, 422): return "validation"
if status == 401: return "auth"
if status == 403: return "permission"
if status == 429: return "rate_limit"
if status >= 500 or status == 408: return "transient"
return "transient"
def call_with_budget(do_call):
"""One retry owner. Backoff with full jitter; stop-classes never retry."""
attempt = 0
while True:
status, result = do_call()
if 200 <= status < 300:
return result
cls = classify(status)
budget = RETRY_BUDGET[cls]["retries"]
if attempt >= budget:
# error_class + decision go straight into your structured logs
log.warning("retry_exhausted", error_class=cls, status=status,
decision="escalate")
raise RuntimeError(f"{cls} error ({status}) not retryable here")
sleep = min(2 ** attempt, 30) * (0.5 + random.random()) # full jitter
time.sleep(sleep)
attempt += 1“A 403 will be a 403 on the fiftieth try. Retrying a permanent error is not resilience — it is the loop.”
The single rule that prevents most retry-driven agent loops
| Error class | Example status | Retries | Backoff | Then what |
|---|---|---|---|---|
| Validation | 400 / 422 | 0 | none | Stop — return the validation error to the model so it fixes its input |
| Auth | 401 | 0 | none | Stop and escalate — credentials will not self-heal |
| Permission | 403 | 0 | none | Stop and escalate — this is a policy block, not a glitch |
| Rate limit | 429 | 3 | exponential + jitter | Respect Retry-After; after 3, escalate or queue |
| Transient server | 500 / 502 / 503 | 2 | exponential + jitter | Escalate after 2 — do not retry forever |
| Timeout | 408 / client timeout | 2 | exponential + jitter | Escalate after 2; check the 300s SDK default timeout |
How do typed tool results stop the ambiguous-feedback loop?
Return a typed status enum from every tool — ok | no_results | error — instead of human-readable prose, so the agent can branch deterministically on the outcome. Ambiguous feedback like ‘more results may be available’ is the most common loop trigger because it reads to the model as ‘keep trying,’ not ‘done.’
This is the root cause that no incumbent explainer puts front and center, and it is the one with the highest leverage. The AWS engineering team’s write-up on DEV Community measured it directly: a tool returning the ambiguous string ‘Found N flights… Note: More results may be available’ caused the agent to make 14 tool calls in 21 seconds. The exact same task, with the tool returning an explicit terminal status, took 2 tool calls in 4 seconds — a 7x reduction purely from clearer signaling.
The fix is not better prompt engineering. It is a contract. Define a small status enum, attach it to every tool result, and the model gets an unambiguous branch point. ‘no_results’ is a terminal success that means stop looking; it is categorically different from ‘error,’ which the model should not confuse with an empty-but-valid answer. Conflating those two is what produces the ‘search forever’ loop.
from enum import Enum
from dataclasses import dataclass, asdict
from typing import Any
class ToolStatus(str, Enum):
OK = "ok" # request succeeded, payload present
NO_RESULTS = "no_results" # request succeeded, nothing to return (TERMINAL)
ERROR = "error" # request failed; see error_class
@dataclass
class ToolResult:
status: ToolStatus
data: Any = None
error_class: str | None = None # validation | auth | permission | ...
message: str = ""
def to_model(self) -> dict:
# The model sees status FIRST. no_results is a stop, not a retry.
return asdict(self)
# Before (ambiguous prose -> the agent re-searches forever):
# return f"Found {n} flights under ${cap}. More results may be available."
# After (typed -> the agent branches deterministically and stops):
def search_flights(cap: int) -> ToolResult:
matches = run_search(cap)
if not matches:
return ToolResult(ToolStatus.NO_RESULTS,
message=f"No flights under ${cap}. This is final.")
return ToolResult(ToolStatus.OK, data=matches,
message=f"Returned {len(matches)} flights. Complete.")Why is max_turns alone not enough to stop an agent loop?
max_turns is a blunt instrument: it caps the damage but does not fix the loop, because an agent that hits its turn limit on a complex task has simply failed on that task. Pair it with max_budget_usd, the duplicate-call detector, and typed tool results so the loop is prevented and contained rather than just truncated.
The Claude Agent SDK documents this honestly. max_turns ‘counts tool-use turns only’ and defaults to no limit; max_budget_usd ‘caps turns based on a spend threshold,’ and the docs state plainly that ‘setting a budget is a good default for production agents.’ Both are real backstops — but they are the last line of defense, not the first. When either fires, the SDK returns a ResultMessage with subtype error_max_turns or error_max_budget_usd, which tells you the run was killed, not that the task succeeded.
Think of it as layered defense. The duplicate-call detector and typed results prevent the loop. The retry budget contains the most common cause. max_budget_usd is your spend ceiling, which matters because a runaway agent’s real cost is dollars, not turns — a single expensive turn can blow past a generous turn count. And max_turns is the final fuse. Relying on max_turns alone is like running a service with only an OOM killer and no memory management: technically it stops, but every stop is an incident.
One more SDK detail worth wiring in: the default external-call timeout is 300 seconds (5 minutes). A tool that hangs without timing out can stall a loop just as effectively as one that repeats, so confirm your tool calls inherit a sane timeout rather than blocking indefinitely.
Pros
Cons
Set max_budget_usd as your production default and keep max_turns as a fuse, but never ship them as your only defense. Without the duplicate-call detector and typed results, you are just choosing how much money to waste before the loop is killed.
What should I log to debug an agent loop fast?
3
Repeat threshold to trip the detector
Same (tool, result) fingerprint three times = confirmed loop
0 / 3 / 2
Retries: stop-class / rate-limit / transient
Validation, auth, permission get zero; 429 gets 3; 5xx/timeout get 2
7x
Fewer tool calls from typed results
AWS measured 14 calls down to 2 with a status enum
$0
max_budget_usd default in the SDK
No limit by default — set one; it is ‘a good default for production agents’
Stop the loop in layers, in order
Log a structured record per step with six fields: loop_iteration, last_tool, last_result_hash, tool_calls_count, error_class, and decision. These turn a 3am loop incident into a one-line grep instead of an archaeological dig through raw transcripts.
Most teams log the full agent transcript and nothing else, which means debugging a loop requires reading thousands of tokens of model narration to find the three identical calls buried inside. The fields above — the same schema MatrixTrak recommends — let you spot the loop instantly: filter on a repeating last_result_hash, and the loop_iteration count tells you exactly when the fingerprint started repeating and what decision the breaker made.
The decision field is the keystone. It records what your control layer did at each step — continue, BREAK_LOOP, escalate, retry — so when you review an incident you can see not just that the agent looped, but whether your defenses fired correctly. If you see five identical last_result_hash values and a decision of ‘continue’ on all of them, your detector threshold is mis-set. If you see error_class ‘permission’ with decision ‘retry,’ your retry budget is leaking. The logs tell you which of the four root causes you are looking at without ever opening the transcript.
Builder’s take
I have shipped enough agent infrastructure across Cyntr and Loomfeed to know that a looping agent is almost never a ‘bad model’ problem. It is a missing-feedback problem, and you fix it in the harness, not the prompt.
- A loop is a missing state machine. If your agent cannot read a machine-parsable ‘done’, it will keep poking at the world hoping the world changed. Give every tool a typed status before you touch the system prompt.
- max_turns is a fuse, not a fix. I run it as a backstop, but the real controls are a duplicate-call fingerprint detector and a retry budget keyed to the error class. Treat a 429 differently from a 403 differently from a 500.
- Centralize retries in exactly one layer. The worst loops I have debugged were three retry mechanisms (HTTP client, tool wrapper, agent policy) multiplying into 2x2x2 attempts on a permanent failure. Pick one owner.
- Log the fingerprint, not the transcript. loop_iteration, last_tool, last_result_hash, error_class, decision — five fields turn a 3am incident into a one-line grep instead of a transcript archaeology dig.
Frequently asked questions
It is not getting a machine-readable signal that the call succeeded or that the task is done. When a tool returns ambiguous prose like ‘more results may be available,’ the model reads it as an invitation to try again. Return a typed status (ok | no_results | error) instead, and the agent gets an unambiguous branch point. This single fix cut one AWS team’s loop from 14 tool calls to 2.
Three repeats of the same fingerprint. Fingerprint each step as a hash of the last tool name plus its result; when that exact (tool, result) pair occurs three times, you have a confirmed loop. Two repeats can be a legitimate retry after a transient blip, but a third identical pair means the agent has learned nothing and the environment has not changed.
It depends on the error class. Validation (400/422), auth (401), and permission (403) errors get zero retries — they are permanent and will return the same failure every time. Rate limits (429) get three retries with exponential backoff plus jitter. Transient server errors (5xx) and timeouts get two retries, then escalate. A single global retry count is what causes retry loops.
No. max_turns caps the damage but does not prevent the loop, and an agent that hits its turn limit on a complex task has simply failed silently. The Claude Agent SDK documents it as counting tool-use turns only with no default limit. Pair it with max_budget_usd (a spend ceiling the SDK calls ‘a good default for production agents’), a duplicate-call detector, and typed tool results so the loop is prevented, not just truncated.
max_turns caps the number of tool-use round trips; max_budget_usd caps total spend. They protect against different failure shapes. A loop of cheap calls is bounded by max_turns, but a few very expensive turns can blow your real budget while staying under a generous turn count — that is what max_budget_usd catches. Set the budget as your production default and keep max_turns as a final fuse.
This is the dangerous case — the looping tool sends emails, charges cards, or files tickets on each repeat. Two defenses: attach an idempotency key so duplicate calls with the same key are deduplicated server-side, and run the duplicate-call fingerprint detector so the second or third identical call is blocked before it executes the side effect again. Never rely on max_turns here, because even a small loop can duplicate real-world actions.
Primary sources
- How the agent loop works — Claude Agent SDK (max_turns, max_budget_usd) — Anthropic / Claude Code Docs
- How to Prevent AI Agent Reasoning Loops from Wasting Tokens — AWS on DEV Community
- Agent keeps calling same tool: why autonomous agents loop forever in production — MatrixTrak
- Why Your AI Agent Keeps Looping and How to Stop It — Meritshot
- Why your AI agent loops forever (and how to break the cycle) — DEV Community
Last updated: June 2, 2026. Related: Observability.




